 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Where Words Come: Efficient Regularization of Code Tokenizers Through Source Attribution
Apr 15, 2026Efficiency and safety of Large Language Models (LLMs), among other factors, rely on the quality of tokenization. A good tokenizer not only improves inference speed and language understanding but also provides extra defense against jailbreak attacks and lowers the risk of hallucinations. In this work, we investigate the efficiency of code tokenization, in particular from the perspective of data source diversity. We demonstrate that code tokenizers are prone to producing unused, and thus under-trained, tokens due to the imbalance in repository and language diversity in the training data, as well as the dominance of source-specific, repetitive tokens that are often unusable in future inference. By modifying the BPE objective and introducing merge skipping, we implement different techniques under the name Source-Attributed BPE (SA-BPE) to regularize BPE training and minimize overfitting, thereby substantially reducing the number of under-trained tokens while maintaining the same inference procedure as with regular BPE. This provides an effective tool suitable for production use.
Protecting Private Code in IDE Autocomplete using Differential Privacy
Jan 30, 2026Modern Integrated Development Environments (IDEs) increasingly leverage Large Language Models (LLMs) to provide advanced features like code autocomplete. While powerful, training these models on user-written code introduces significant privacy risks, making the models themselves a new type of data vulnerability. Malicious actors can exploit this by launching attacks to reconstruct sensitive training data or infer whether a specific code snippet was used for training. This paper investigates the use of Differential Privacy (DP) as a robust defense mechanism for training an LLM for Kotlin code completion. We fine-tune a \texttt{Mellum} model using DP and conduct a comprehensive evaluation of its privacy and utility. Our results demonstrate that DP provides a strong defense against Membership Inference Attacks (MIAs), reducing the attack's success rate close to a random guess (AUC from 0.901 to 0.606). Furthermore, we show that this privacy guarantee comes at a minimal cost to model performance, with the DP-trained model achieving utility scores comparable to its non-private counterpart, even when trained on 100x less data. Our findings suggest that DP is a practical and effective solution for building private and trustworthy AI-powered IDE features.
Practical Code RAG at Scale: Task-Aware Retrieval Design Choices under Compute Budgets
Oct 23, 2025We study retrieval design for code-focused generation tasks under realistic compute budgets. Using two complementary tasks from Long Code Arena -- code completion and bug localization -- we systematically compare retrieval configurations across various context window sizes along three axes: (i) chunking strategy, (ii) similarity scoring, and (iii) splitting granularity. (1) For PL-PL, sparse BM25 with word-level splitting is the most effective and practical, significantly outperforming dense alternatives while being an order of magnitude faster. (2) For NL-PL, proprietary dense encoders (Voyager-3 family) consistently beat sparse retrievers, however requiring 100x larger latency. (3) Optimal chunk size scales with available context: 32-64 line chunks work best at small budgets, and whole-file retrieval becomes competitive at 16000 tokens. (4) Simple line-based chunking matches syntax-aware splitting across budgets. (5) Retrieval latency varies by up to 200x across configurations; BPE-based splitting is needlessly slow, and BM25 + word splitting offers the best quality-latency trade-off. Thus, we provide evidence-based recommendations for implementing effective code-oriented RAG systems based on task requirements, model constraints, and computational efficiency.
Diff-XYZ: A Benchmark for Evaluating Diff Understanding
Oct 14, 2025Reliable handling of code diffs is central to agents that edit and refactor repositories at scale. We introduce Diff-XYZ, a compact benchmark for code-diff understanding with three supervised tasks: apply (old code $+$ diff $\rightarrow$ new code), anti-apply (new code $-$ diff $\rightarrow$ old code), and diff generation (new code $-$ old code $\rightarrow$ diff). Instances in the benchmark are triples $\langle \textit{old code}, \textit{new code}, \textit{diff} \rangle$ drawn from real commits in CommitPackFT, paired with automatic metrics and a clear evaluation protocol. We use the benchmark to do a focused empirical study of the unified diff format and run a cross-format comparison of different diff representations. Our findings reveal that different formats should be used depending on the use case and model size. For example, representing diffs in search-replace format is good for larger models in the diff generation scenario, yet not suited well for diff analysis and smaller models. The Diff-XYZ benchmark is a reusable foundation for assessing and improving diff handling in LLMs that can aid future development of diff formats and models editing code. The dataset is published on HuggingFace Hub: https://huggingface.co/datasets/JetBrains-Research/diff-xyz.
Challenge on Optimization of Context Collection for Code Completion
Oct 05, 2025



The rapid advancement of workflows and methods for software engineering using AI emphasizes the need for a systematic evaluation and analysis of their ability to leverage information from entire projects, particularly in large code bases. In this challenge on optimization of context collection for code completion, organized by JetBrains in collaboration with Mistral AI as part of the ASE 2025 conference, participants developed efficient mechanisms for collecting context from source code repositories to improve fill-in-the-middle code completions for Python and Kotlin. We constructed a large dataset of real-world code in these two programming languages using permissively licensed open-source projects. The submissions were evaluated based on their ability to maximize completion quality for multiple state-of-the-art neural models using the chrF metric. During the public phase of the competition, nineteen teams submitted solutions to the Python track and eight teams submitted solutions to the Kotlin track. In the private phase, six teams competed, of which five submitted papers to the workshop.
GitGoodBench: A Novel Benchmark For Evaluating Agentic Performance On Git
May 28, 2025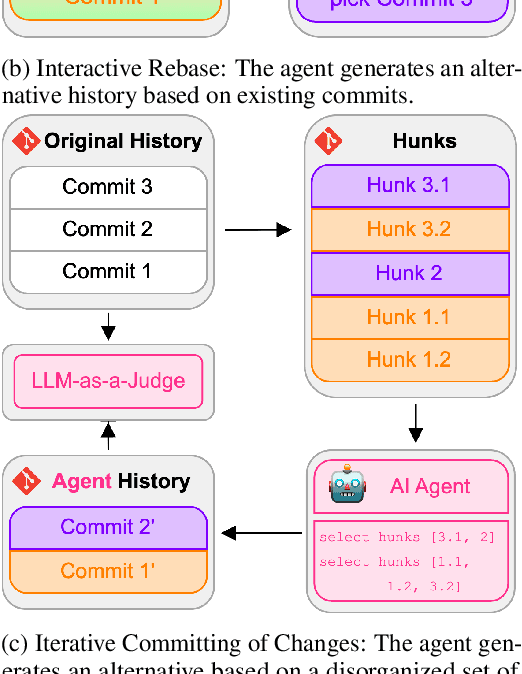

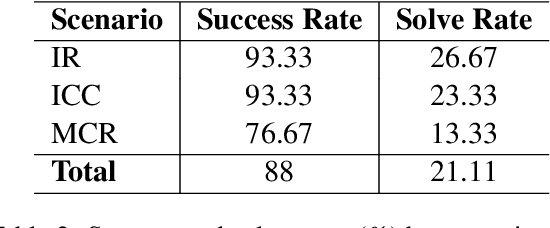
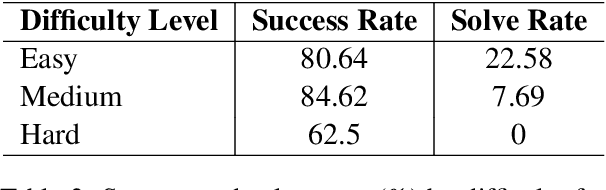
Benchmarks for Software Engineering (SE) AI agents, most notably SWE-bench, have catalyzed progress in programming capabilities of AI agents. However, they overlook critical developer workflows such as Version Control System (VCS) operations. To address this issue, we present GitGoodBench, a novel benchmark for evaluating AI agent performance on VCS tasks. GitGoodBench covers three core Git scenarios extracted from permissive open-source Python, Java, and Kotlin repositories. Our benchmark provides three datasets: a comprehensive evaluation suite (900 samples), a rapid prototyping version (120 samples), and a training corpus (17,469 samples). We establish baseline performance on the prototyping version of our benchmark using GPT-4o equipped with custom tools, achieving a 21.11% solve rate overall. We expect GitGoodBench to serve as a crucial stepping stone toward truly comprehensive SE agents that go beyond mere programming.
EnvBench: A Benchmark for Automated Environment Setup
Mar 18, 2025
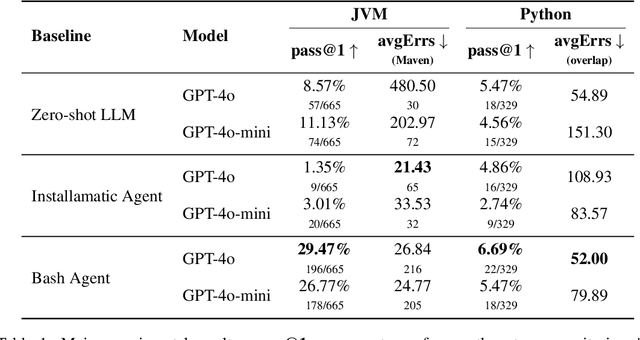
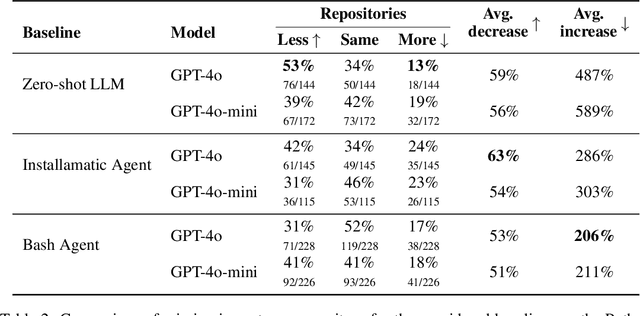
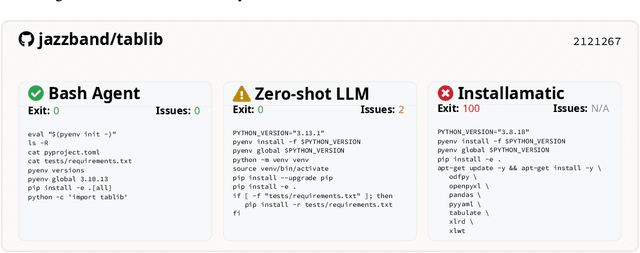
Recent advances in Large Language Models (LLMs) have enabled researchers to focus on practical repository-level tasks in software engineering domain. In this work, we consider a cornerstone task for automating work with software repositories-environment setup, i.e., a task of configuring a repository-specific development environment on a system. Existing studies on environment setup introduce innovative agentic strategies, but their evaluation is often based on small datasets that may not capture the full range of configuration challenges encountered in practice. To address this gap, we introduce a comprehensive environment setup benchmark EnvBench. It encompasses 329 Python and 665 JVM-based (Java, Kotlin) repositories, with a focus on repositories that present genuine configuration challenges, excluding projects that can be fully configured by simple deterministic scripts. To enable further benchmark extension and usage for model tuning, we implement two automatic metrics: a static analysis check for missing imports in Python and a compilation check for JVM languages. We demonstrate the applicability of our benchmark by evaluating three environment setup approaches, including a simple zero-shot baseline and two agentic workflows, that we test with two powerful LLM backbones, GPT-4o and GPT-4o-mini. The best approach manages to successfully configure 6.69% repositories for Python and 29.47% repositories for JVM, suggesting that EnvBench remains challenging for current approaches. Our benchmark suite is publicly available at https://github.com/JetBrains-Research/EnvBench. The dataset and experiment trajectories are available at https://jb.gg/envbench.
Drawing Pandas: A Benchmark for LLMs in Generating Plotting Code
Dec 03, 2024This paper introduces the human-curated PandasPlotBench dataset, designed to evaluate language models' effectiveness as assistants in visual data exploration. Our benchmark focuses on generating code for visualizing tabular data - such as a Pandas DataFrame - based on natural language instructions, complementing current evaluation tools and expanding their scope. The dataset includes 175 unique tasks. Our experiments assess several leading Large Language Models (LLMs) across three visualization libraries: Matplotlib, Seaborn, and Plotly. We show that the shortening of tasks has a minimal effect on plotting capabilities, allowing for the user interface that accommodates concise user input without sacrificing functionality or accuracy. Another of our findings reveals that while LLMs perform well with popular libraries like Matplotlib and Seaborn, challenges persist with Plotly, highlighting areas for improvement. We hope that the modular design of our benchmark will broaden the current studies on generating visualizations. Our benchmark is available online: https://huggingface.co/datasets/JetBrains-Research/plot_bench. The code for running the benchmark is also available: https://github.com/JetBrains-Research/PandasPlotBench.
Long Code Arena: a Set of Benchmarks for Long-Context Code Models
Jun 17, 2024



Nowadays, the fields of code and natural language processing are evolving rapidly. In particular, models become better at processing long context windows - supported context sizes have increased by orders of magnitude over the last few years. However, there is a shortage of benchmarks for code processing that go beyond a single file of context, while the most popular ones are limited to a single method. With this work, we aim to close this gap by introducing Long Code Arena, a suite of six benchmarks for code processing tasks that require project-wide context. These tasks cover different aspects of code processing: library-based code generation, CI builds repair, project-level code completion, commit message generation, bug localization, and module summarization. For each task, we provide a manually verified dataset for testing, an evaluation suite, and open-source baseline solutions based on popular LLMs to showcase the usage of the dataset and to simplify adoption by other researchers. We publish the benchmark page on HuggingFace Spaces with the leaderboard, links to HuggingFace Hub for all the datasets, and link to the GitHub repository with baselines: https://huggingface.co/spaces/JetBrains-Research/long-code-arena.
EM-Assist: Safe Automated ExtractMethod Refactoring with LLMs
May 31, 2024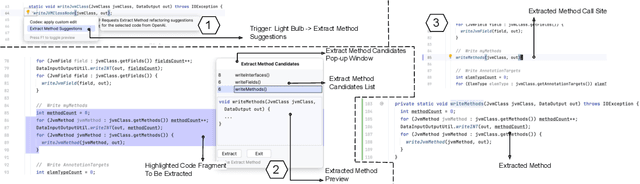
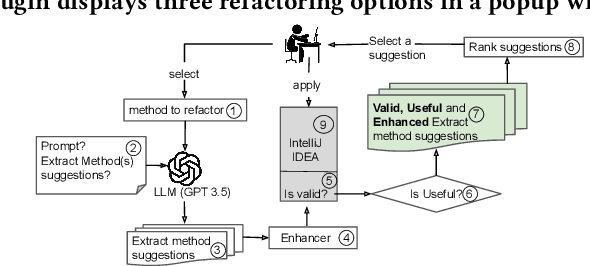

Excessively long methods, loaded with multiple responsibilities, are challenging to understand, debug, reuse, and maintain. The solution lies in the widely recognized Extract Method refactoring. While the application of this refactoring is supported in modern IDEs, recommending which code fragments to extract has been the topic of many research tools. However, they often struggle to replicate real-world developer practices, resulting in recommendations that do not align with what a human developer would do in real life. To address this issue, we introduce EM-Assist, an IntelliJ IDEA plugin that uses LLMs to generate refactoring suggestions and subsequently validates, enhances, and ranks them. Finally, EM-Assist uses the IntelliJ IDE to apply the user-selected recommendation. In our extensive evaluation of 1,752 real-world refactorings that actually took place in open-source projects, EM-Assist's recall rate was 53.4% among its top-5 recommendations, compared to 39.4% for the previous best-in-class tool that relies solely on static analysis. Moreover, we conducted a usability survey with 18 industrial developers and 94.4% gave a positive rating.