 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Impact of Source Code Parsers on ML4SE Models
Jun 17, 2022
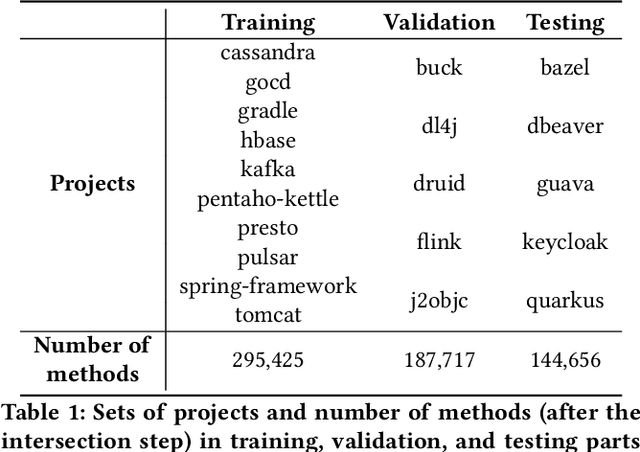


As researchers and practitioners apply Machine Learning to increasingly more software engineering problems, the approaches they use become more sophisticated. A lot of modern approaches utilize internal code structure in the form of an abstract syntax tree (AST) or its extensions: path-based representation, complex graph combining AST with additional edges. Even though the process of extracting ASTs from code can be done with different parsers, the impact of choosing a parser on the final model quality remains unstudied. Moreover, researchers often omit the exact details of extracting particular code representations. In this work, we evaluate two models, namely Code2Seq and TreeLSTM, in the method name prediction task backed by eight different parsers for the Java language. To unify the process of data preparation with different parsers, we develop SuperParser, a multi-language parser-agnostic library based on PathMiner. SuperParser facilitates the end-to-end creation of datasets suitable for training and evaluation of ML models that work with structural information from source code. Our results demonstrate that trees built by different parsers vary in their structure and content. We then analyze how this diversity affects the models' quality and show that the quality gap between the most and least suitable parsers for both models turns out to be significant. Finally, we discuss other features of the parsers that researchers and practitioners should take into account when selecting a parser along with the impact on the models' quality. The code of SuperParser is publicly available at https://doi.org/10.5281/zenodo.6366591. We also publish Java-norm, the dataset we use to evaluate the models: https://doi.org/10.5281/zenodo.6366599.