 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonverbalTTS: A Public English Corpus of Text-Aligned Nonverbal Vocalizations with Emotion Annotations for Text-to-Speech
Jul 17, 2025Current expressive speech synthesis models are constrained by the limited availability of open-source datasets containing diverse nonverbal vocalizations (NVs). In this work, we introduce NonverbalTTS (NVTTS), a 17-hour open-access dataset annotated with 10 types of NVs (e.g., laughter, coughs) and 8 emotional categories. The dataset is derived from popular sources, VoxCeleb and Expresso, using automated detection followed by human validation. We propose a comprehensive pipeline that integrates automatic speech recognition (ASR), NV tagging, emotion classification, and a fusion algorithm to merge transcriptions from multiple annotators. Fine-tuning open-source text-to-speech (TTS) models on the NVTTS dataset achieves parity with closed-source systems such as CosyVoice2, as measured by both human evaluation and automatic metrics, including speaker similarity and NV fidelity. By releasing NVTTS and its accompanying annotation guidelines, we address a key bottleneck in expressive TTS research. The dataset is available at https://huggingface.co/datasets/deepvk/NonverbalTTS.
TAGC: Optimizing Gradient Communication in Distributed Transformer Training
Apr 08, 2025

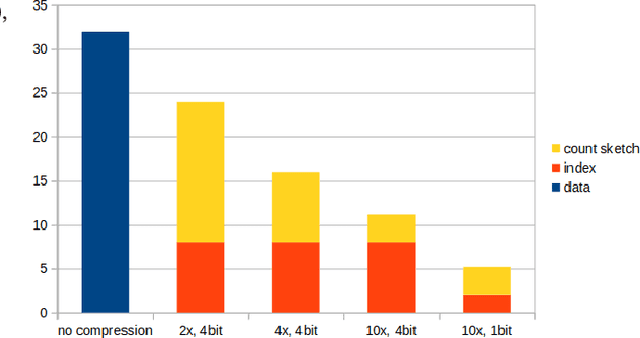

The increasing complexity of large language models (LLMs) necessitates efficient training strategies to mitigate the high computational costs associated with distributed training. A significant bottleneck in this process is gradient synchronization across multiple GPUs, particularly in the zero-redundancy parallelism mode. In this paper, we introduce Transformer-Aware Gradient Compression (TAGC), an optimized gradient compression algorithm designed specifically for transformer-based models. TAGC extends the lossless homomorphic compression method by adapting it for sharded models and incorporating transformer-specific optimizations, such as layer-selective compression and dynamic sparsification. Our experimental results demonstrate that TAGC accelerates training by up to 15% compared to the standard Fully Sharded Data Parallel (FSDP) approach, with minimal impact on model quality. We integrate TAGC into the PyTorch FSDP framework, the implementation is publicly available at https://github.com/ipolyakov/TAGC.
METR: Image Watermarking with Large Number of Unique Messages
Aug 15, 2024



Improvements in diffusion models have boosted the quality of image generation, which has led researchers, companies, and creators to focus on improving watermarking algorithms. This provision would make it possible to clearly identify the creators of generative art. The main challenges that modern watermarking algorithms face have to do with their ability to withstand attacks and encrypt many unique messages, such as user IDs. In this paper, we present METR: Message Enhanced Tree-Ring, which is an approach that aims to address these challenges. METR is built on the Tree-Ring watermarking algorithm, a technique that makes it possible to encode multiple distinct messages without compromising attack resilience or image quality. This ensures the suitability of this watermarking algorithm for any Diffusion Model. In order to surpass the limitations on the quantity of encoded messages, we propose METR++, an enhanced version of METR. This approach, while limited to the Latent Diffusion Model architecture, is designed to inject a virtually unlimited number of unique messages. We demonstrate its robustness to attacks and ability to encrypt many unique messages while preserving image quality, which makes METR and METR++ hold great potential for practical applications in real-world settings. Our code is available at https://github.com/deepvk/metr
Adapting WavLM for Speech Emotion Recognition
May 07, 2024Recently, the usage of speech self-supervised models (SSL) for downstream tasks has been drawing a lot of attention. While large pre-trained models commonly outperform smaller models trained from scratch, questions regarding the optimal fine-tuning strategies remain prevalent. In this paper, we explore the fine-tuning strategies of the WavLM Large model for the speech emotion recognition task on the MSP Podcast Corpus. More specifically, we perform a series of experiments focusing on using gender and semantic information from utterances. We then sum up our findings and describe the final model we used for submission to Speech Emotion Recognition Challenge 2024.
Evaluation of Contrastive Learning with Various Code Representations for Code Clone Detection
Jun 17, 2022



Code clones are pairs of code snippets that implement similar functionality. Clone detection is a fundamental branch of automatic source code comprehension, having many applications in refactoring recommendation, plagiarism detection, and code summarization. A particularly interesting case of clone detection is the detection of semantic clones, i.e., code snippets that have the same functionality but significantly differ in implementation. A promising approach to detecting semantic clones is contrastive learning (CL), a machine learning paradigm popular in computer vision but not yet commonly adopted for code processing. Our work aims to evaluate the most popular CL algorithms combined with three source code representations on two tasks. The first task is code clone detection, which we evaluate on the POJ-104 dataset containing implementations of 104 algorithms. The second task is plagiarism detection. To evaluate the models on this task, we introduce CodeTransformator, a tool for transforming source code. We use it to create a dataset that mimics plagiarised code based on competitive programming solutions. We trained nine models for both tasks and compared them with six existing approaches, including traditional tools and modern pre-trained neural models. The results of our evaluation show that proposed models perform diversely in each task, however the performance of the graph-based models is generally above the others. Among CL algorithms, SimCLR and SwAV lead to better results, while Moco is the most robust approach. Our code and trained models are available at https://doi.org/10.5281/zenodo.6360627, https://doi.org/10.5281/zenodo.5596345.
Evaluating the Impact of Source Code Parsers on ML4SE Models
Jun 17, 2022


As researchers and practitioners apply Machine Learning to increasingly more software engineering problems, the approaches they use become more sophisticated. A lot of modern approaches utilize internal code structure in the form of an abstract syntax tree (AST) or its extensions: path-based representation, complex graph combining AST with additional edges. Even though the process of extracting ASTs from code can be done with different parsers, the impact of choosing a parser on the final model quality remains unstudied. Moreover, researchers often omit the exact details of extracting particular code representations. In this work, we evaluate two models, namely Code2Seq and TreeLSTM, in the method name prediction task backed by eight different parsers for the Java language. To unify the process of data preparation with different parsers, we develop SuperParser, a multi-language parser-agnostic library based on PathMiner. SuperParser facilitates the end-to-end creation of datasets suitable for training and evaluation of ML models that work with structural information from source code. Our results demonstrate that trees built by different parsers vary in their structure and content. We then analyze how this diversity affects the models' quality and show that the quality gap between the most and least suitable parsers for both models turns out to be significant. Finally, we discuss other features of the parsers that researchers and practitioners should take into account when selecting a parser along with the impact on the models' quality. The code of SuperParser is publicly available at https://doi.org/10.5281/zenodo.6366591. We also publish Java-norm, the dataset we use to evaluate the models: https://doi.org/10.5281/zenodo.6366599.
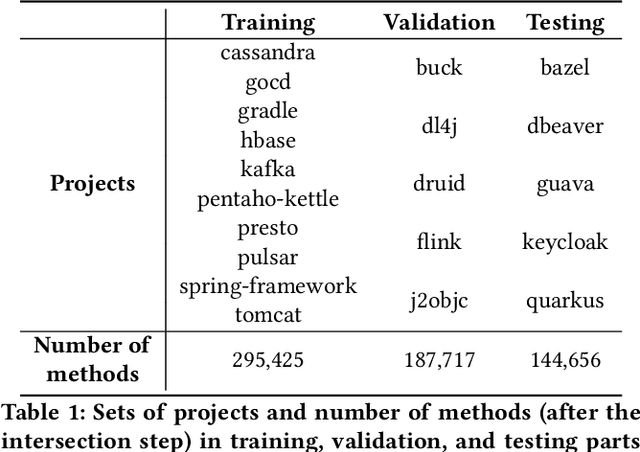
Assessing Project-Level Fine-Tuning of ML4SE Models
Jun 07, 2022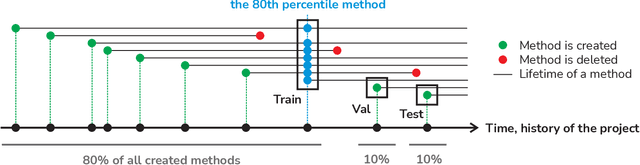



Machine Learning for Software Engineering (ML4SE) is an actively growing research area that focuses on methods that help programmers in their work. In order to apply the developed methods in practice, they need to achieve reasonable quality in order to help rather than distract developers. While the development of new approaches to code representation and data collection improves the overall quality of the models, it does not take into account the information that we can get from the project at hand. In this work, we investigate how the model's quality can be improved if we target a specific project. We develop a framework to assess quality improvements that models can get after fine-tuning for the method name prediction task on a particular project. We evaluate three models of different complexity and compare their quality in three settings: trained on a large dataset of Java projects, further fine-tuned on the data from a particular project, and trained from scratch on this data. We show that per-project fine-tuning can greatly improve the models' quality as they capture the project's domain and naming conventions. We open-source the tool we used for data collection, as well as the code to run the experiments: https://zenodo.org/record/6040745.
PSIMiner: A Tool for Mining Rich Abstract Syntax Trees from Code
Mar 23, 2021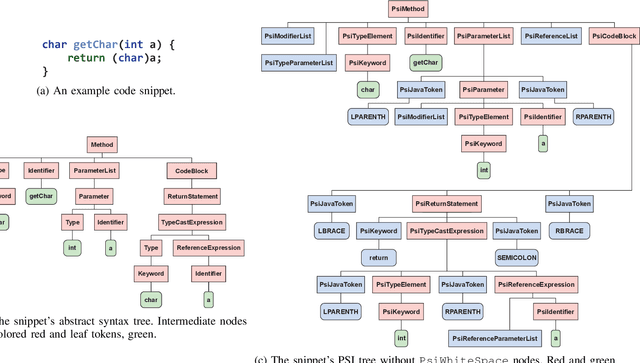

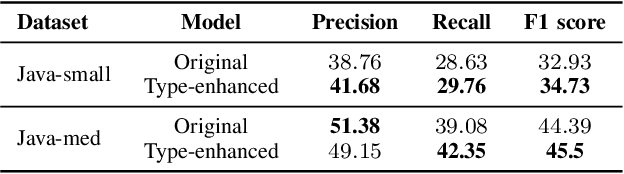
The application of machine learning algorithms to source code has grown in the past years. Since these algorithms are quite sensitive to input data, it is not surprising that researchers experiment with input representations. Nowadays, a popular starting point to represent code is abstract syntax trees (ASTs). Abstract syntax trees have been used for a long time in various software engineering domains, and in particular in IDEs. The API of modern IDEs allows to manipulate and traverse ASTs, resolve references between code elements, etc. Such algorithms can enrich ASTs with new data and therefore may be useful in ML-based code analysis. In this work, we present PSIMiner - a tool for processing PSI trees from the IntelliJ Platform. PSI trees contain code syntax trees as well as functions to work with them, and therefore can be used to enrich code representation using static analysis algorithms of modern IDEs. To showcase this idea, we use our tool to infer types of identifiers in Java ASTs and extend the code2seq model for the method name prediction problem.