 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenge on Optimization of Context Collection for Code Completion
Oct 05, 2025



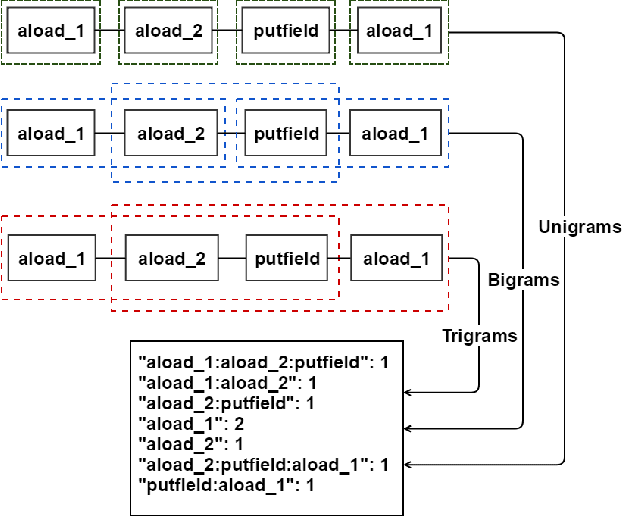
The rapid advancement of workflows and methods for software engineering using AI emphasizes the need for a systematic evaluation and analysis of their ability to leverage information from entire projects, particularly in large code bases. In this challenge on optimization of context collection for code completion, organized by JetBrains in collaboration with Mistral AI as part of the ASE 2025 conference, participants developed efficient mechanisms for collecting context from source code repositories to improve fill-in-the-middle code completions for Python and Kotlin. We constructed a large dataset of real-world code in these two programming languages using permissively licensed open-source projects. The submissions were evaluated based on their ability to maximize completion quality for multiple state-of-the-art neural models using the chrF metric. During the public phase of the competition, nineteen teams submitted solutions to the Python track and eight teams submitted solutions to the Kotlin track. In the private phase, six teams competed, of which five submitted papers to the workshop.
PSIMiner: A Tool for Mining Rich Abstract Syntax Trees from Code
Mar 23, 2021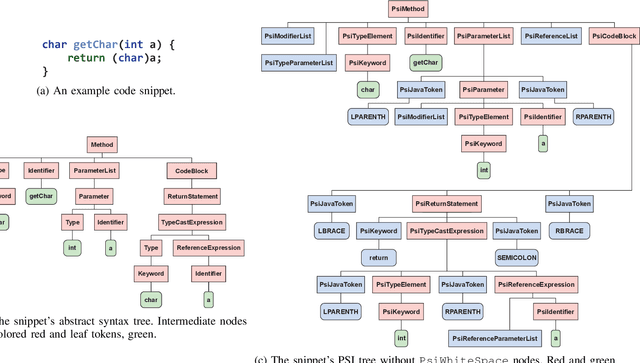

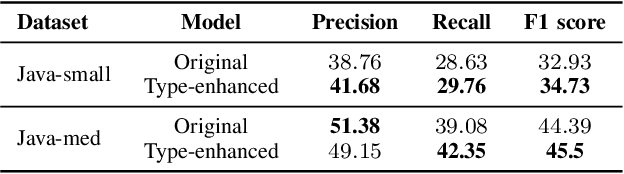
The application of machine learning algorithms to source code has grown in the past years. Since these algorithms are quite sensitive to input data, it is not surprising that researchers experiment with input representations. Nowadays, a popular starting point to represent code is abstract syntax trees (ASTs). Abstract syntax trees have been used for a long time in various software engineering domains, and in particular in IDEs. The API of modern IDEs allows to manipulate and traverse ASTs, resolve references between code elements, etc. Such algorithms can enrich ASTs with new data and therefore may be useful in ML-based code analysis. In this work, we present PSIMiner - a tool for processing PSI trees from the IntelliJ Platform. PSI trees contain code syntax trees as well as functions to work with them, and therefore can be used to enrich code representation using static analysis algorithms of modern IDEs. To showcase this idea, we use our tool to infer types of identifiers in Java ASTs and extend the code2seq model for the method name prediction problem.
Using Large-Scale Anomaly Detection on Code to Improve Kotlin Compiler
Apr 03, 2020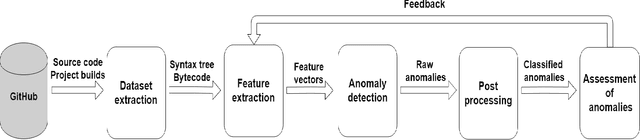
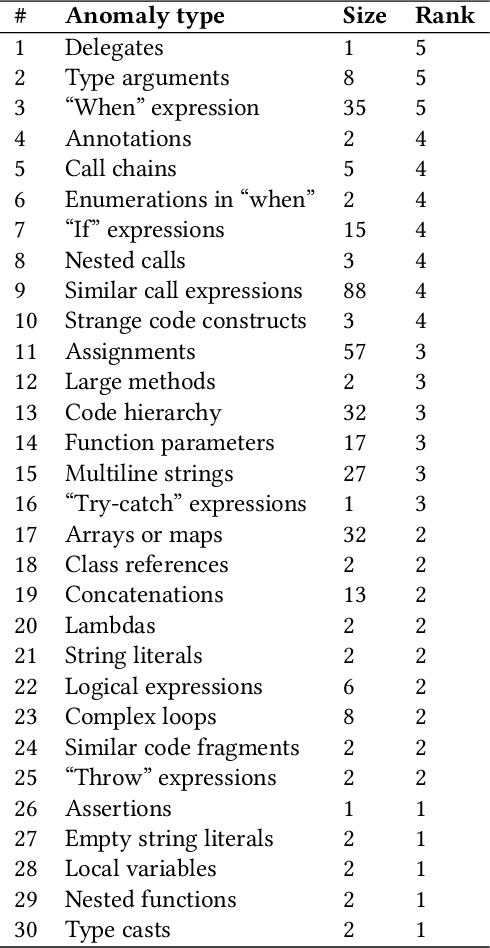
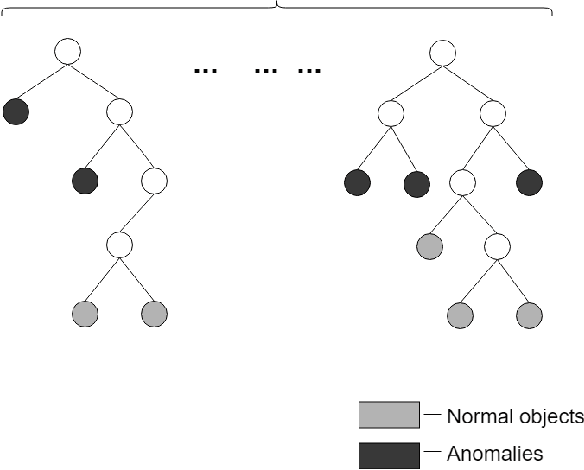
In this work, we apply anomaly detection to source code and bytecode to facilitate the development of a programming language and its compiler. We define anomaly as a code fragment that is different from typical code written in a particular programming language. Identifying such code fragments is beneficial to both language developers and end users, since anomalies may indicate potential issues with the compiler or with runtime performance. Moreover, anomalies could correspond to problems in language design. For this study, we choose Kotlin as the target programming language. We outline and discuss approaches to obtaining vector representations of source code and bytecode and to the detection of anomalies across vectorized code snippets. The paper presents a method that aims to detect two types of anomalies: syntax tree anomalies and so-called compiler-induced anomalies that arise only in the compiled bytecode. We describe several experiments that employ different combinations of vectorization and anomaly detection techniques and discuss types of detected anomalies and their usefulness for language developers. We demonstrate that the extracted anomalies and the underlying extraction technique provide additional value for language development.
Classifiers for centrality determination in proton-nucleus and nucleus-nucleus collisions
Nov 30, 2016

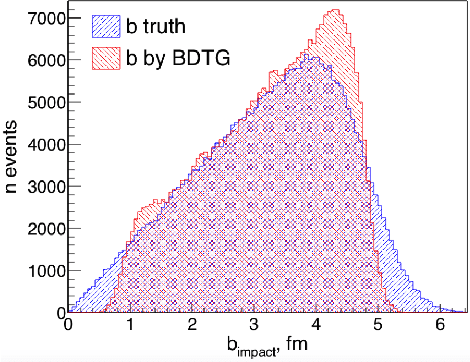
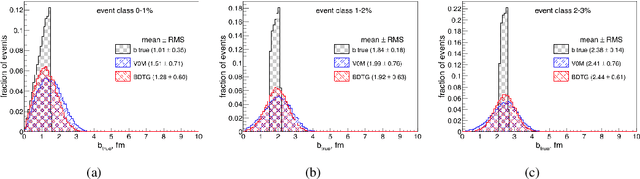
Centrality, as a geometrical property of the collision, is crucial for the physical interpretation of nucleus-nucleus and proton-nucleus experimental data. However, it cannot be directly accessed in event-by-event data analysis. Common methods for centrality estimation in A-A and p-A collisions usually rely on a single detector (either on the signal in zero-degree calorimeters or on the multiplicity in some semi-central rapidity range). In the present work, we made an attempt to develop an approach for centrality determination that is based on machine-learning techniques and utilizes information from several detector subsystems simultaneously. Different event classifiers are suggested and evaluated for their selectivity power in terms of the number of nucleons-participants and the impact parameter of the collision. Finer centrality resolution may allow to reduce impact from so-called volume fluctuations on physical observables being studied in heavy-ion experiments like ALICE at the LHC and fixed target experiment NA61/SHINE on SPS.
* To be published in proceedings of the "XIIth Quark Confinement and the Hadron Spectrum" conference (Thessaloniki, 2016)