 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large-Scale Anomaly Detection on Code to Improve Kotlin Compiler
Apr 03, 2020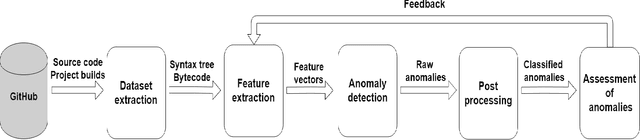
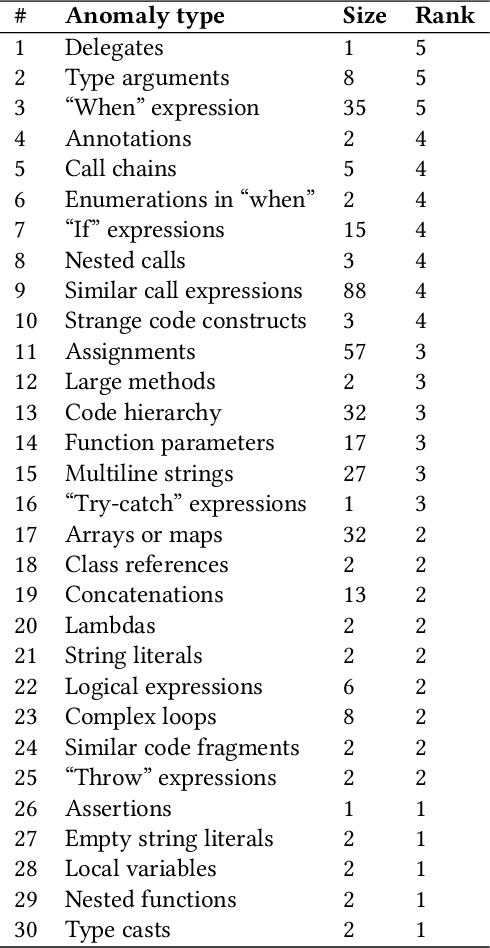
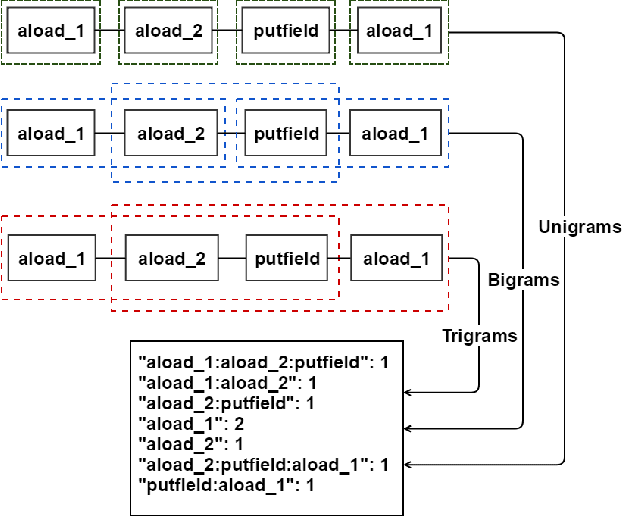
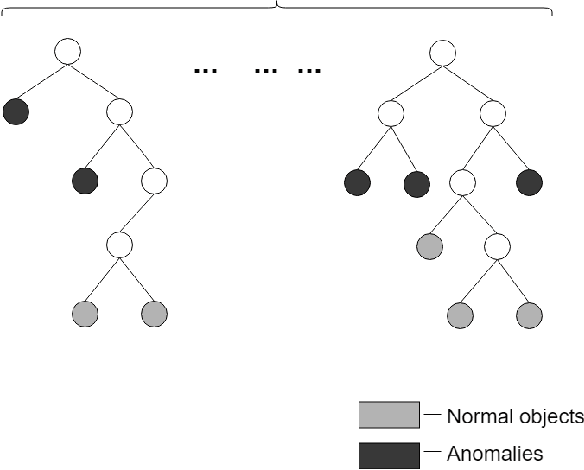
In this work, we apply anomaly detection to source code and bytecode to facilitate the development of a programming language and its compiler. We define anomaly as a code fragment that is different from typical code written in a particular programming language. Identifying such code fragments is beneficial to both language developers and end users, since anomalies may indicate potential issues with the compiler or with runtime performance. Moreover, anomalies could correspond to problems in language design. For this study, we choose Kotlin as the target programming language. We outline and discuss approaches to obtaining vector representations of source code and bytecode and to the detection of anomalies across vectorized code snippets. The paper presents a method that aims to detect two types of anomalies: syntax tree anomalies and so-called compiler-induced anomalies that arise only in the compiled bytecode. We describe several experiments that employ different combinations of vectorization and anomaly detection techniques and discuss types of detected anomalies and their usefulness for language developers. We demonstrate that the extracted anomalies and the underlying extraction technique provide additional value for language development.