 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of the BLEU: how should we assess quality of the Code Generation models?
Paper and Code
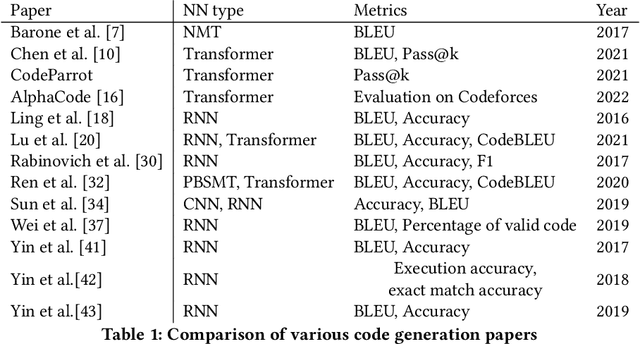
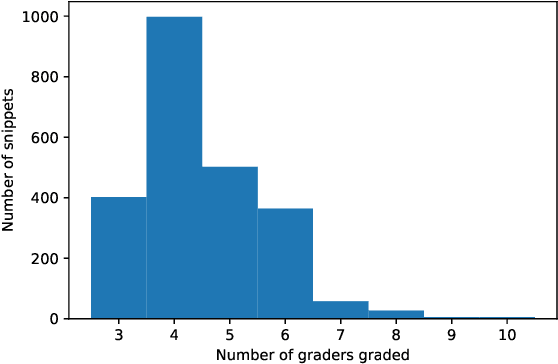

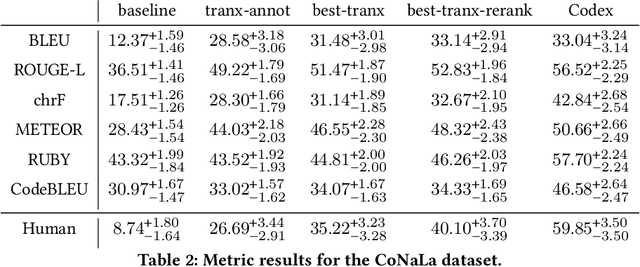
In recent years, researchers have created and introduced a significant number of various code generation models. As human evaluation of every new model version is unfeasible, the community adopted automatic evaluation metrics such as BLEU to approximate the results of human judgement. These metrics originate from the machine translation domain and it is unclear whether they are applicable for the code generation tasks and how well do they agree with the human evaluation on this task. There also are two metrics, CodeBLEU and RUBY, that were developed to estimate the similarity of code and take into account the code properties. However, for these metrics there are hardly any studies on their agreement with the human evaluation. Despite all that, minimal differences in the metric scores are used to claim superiority of some code generation models over the others. In this paper, we present a study on applicability of six metrics -- BLEU, ROUGE-L, METEOR, ChrF, CodeBLEU, RUBY -- for evaluation of the code generation models. We conduct a study on two different code generation datasets and use human annotators to assess the quality of all models run on these datasets. The results indicate that for the CoNaLa dataset of Python one-liners none of the metrics can correctly emulate human judgement on which model is better with $>95\%$ certainty if the difference in model scores is less than 5 points. For the HearthStone dataset, which consists of classes of particular structure, the difference in model scores of at least 2 points is enough to claim the superiority of one model over the other. Using our findings, we derive several recommendations on using metrics to estimate the model performance on the code generation task.