 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVegaChat: A Robust Framework for LLM-Based Chart Generation and Assessment
Jan 21, 2026Natural-language-to-visualization (NL2VIS) systems based on large language models (LLMs) have substantially improved the accessibility of data visualization. However, their further adoption is hindered by two coupled challenges: (i) the absence of standardized evaluation metrics makes it difficult to assess progress in the field and compare different approaches; and (ii) natural language descriptions are inherently underspecified, so multiple visualizations may be valid for the same query. To address these issues, we introduce VegaChat, a framework for generating, validating, and assessing declarative visualizations from natural language. We propose two complementary metrics: Spec Score, a deterministic metric that measures specification-level similarity without invoking an LLM, and Vision Score, a library-agnostic, image-based metric that leverages a multimodal LLM to assess chart similarity and prompt compliance. We evaluate VegaChat on the NLV Corpus and on the annotated subset of ChartLLM. VegaChat achieves near-zero rates of invalid or empty visualizations, while Spec Score and Vision Score exhibit strong correlation with human judgments (Pearson 0.65 and 0.71, respectively), indicating that the proposed metrics support consistent, cross-library comparison. The code and evaluation artifacts are available at https://zenodo.org/records/17062309.
Full Line Code Completion: Bringing AI to Desktop
May 14, 2024



In recent years, several industrial solutions for the problem of multi-token code completion have appeared, each making a great advance in the area but mostly focusing on cloud-based runtime and avoiding working on the end user's device. In this work, we describe our approach for building a multi-token code completion feature for the JetBrains' IntelliJ Platform, which we call Full Line Code Completion. The feature suggests only syntactically correct code and works fully locally, i.e., data querying and the generation of suggestions happens on the end user's machine. We share important time and memory-consumption restrictions, as well as design principles that a code completion engine should satisfy. Working entirely on the end user's device, our code completion engine enriches user experience while being not only fast and compact but also secure. We share a number of useful techniques to meet the stated development constraints and also describe offline and online evaluation pipelines that allowed us to make better decisions. Our online evaluation shows that the usage of the tool leads to 1.5 times more code in the IDE being produced by code completion. The described solution was initially started with the help of researchers and was bundled into two JetBrains' IDEs - PyCharm Pro and DataSpell - at the end of 2023, so we believe that this work is useful for bridging academia and industry, providing researchers with the knowledge of what happens when complex research-based solutions are integrated into real products.
Context Composing for Full Line Code Completion
Feb 14, 2024Code Completion is one of the most used Integrated Development Environment (IDE) features, which affects the everyday life of a software developer. Modern code completion approaches moved from the composition of several static analysis-based contributors to pipelines that involve neural networks. This change allows the proposal of longer code suggestions while maintaining the relatively short time spent on generation itself. At JetBrains, we put a lot of effort into perfecting the code completion workflow so it can be both helpful and non-distracting for a programmer. We managed to ship the Full Line Code Completion feature to PyCharm Pro IDE and proved its usefulness in A/B testing on hundreds of real Python users. The paper describes our approach to context composing for the Transformer model that is a core of the feature's implementation. In addition to that, we share our next steps to improve the feature and emphasize the importance of several research aspects in the area.
From Commit Message Generation to History-Aware Commit Message Completion
Aug 15, 2023



Commit messages are crucial to software development, allowing developers to track changes and collaborate effectively. Despite their utility, most commit messages lack important information since writing high-quality commit messages is tedious and time-consuming. The active research on commit message generation (CMG) has not yet led to wide adoption in practice. We argue that if we could shift the focus from commit message generation to commit message completion and use previous commit history as additional context, we could significantly improve the quality and the personal nature of the resulting commit messages. In this paper, we propose and evaluate both of these novel ideas. Since the existing datasets lack historical data, we collect and share a novel dataset called CommitChronicle, containing 10.7M commits across 20 programming languages. We use this dataset to evaluate the completion setting and the usefulness of the historical context for state-of-the-art CMG models and GPT-3.5-turbo. Our results show that in some contexts, commit message completion shows better results than generation, and that while in general GPT-3.5-turbo performs worse, it shows potential for long and detailed messages. As for the history, the results show that historical information improves the performance of CMG models in the generation task, and the performance of GPT-3.5-turbo in both generation and completion.
Out of the BLEU: how should we assess quality of the Code Generation models?
Aug 05, 2022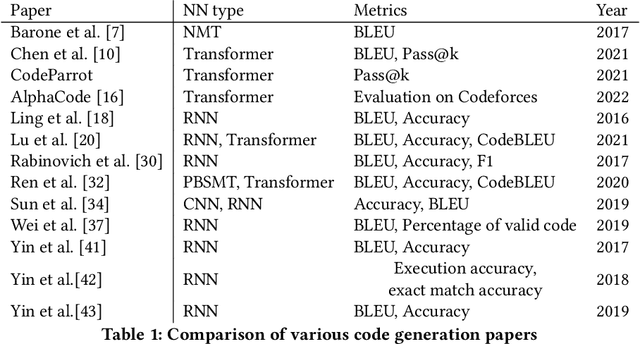

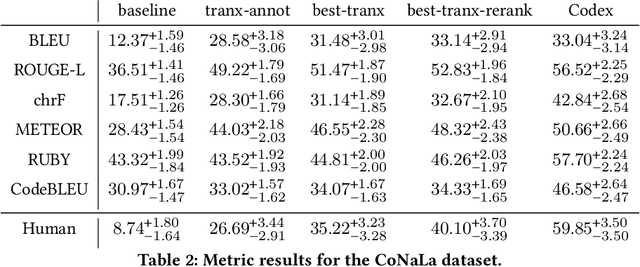
In recent years, researchers have created and introduced a significant number of various code generation models. As human evaluation of every new model version is unfeasible, the community adopted automatic evaluation metrics such as BLEU to approximate the results of human judgement. These metrics originate from the machine translation domain and it is unclear whether they are applicable for the code generation tasks and how well do they agree with the human evaluation on this task. There also are two metrics, CodeBLEU and RUBY, that were developed to estimate the similarity of code and take into account the code properties. However, for these metrics there are hardly any studies on their agreement with the human evaluation. Despite all that, minimal differences in the metric scores are used to claim superiority of some code generation models over the others. In this paper, we present a study on applicability of six metrics -- BLEU, ROUGE-L, METEOR, ChrF, CodeBLEU, RUBY -- for evaluation of the code generation models. We conduct a study on two different code generation datasets and use human annotators to assess the quality of all models run on these datasets. The results indicate that for the CoNaLa dataset of Python one-liners none of the metrics can correctly emulate human judgement on which model is better with $>95\%$ certainty if the difference in model scores is less than 5 points. For the HearthStone dataset, which consists of classes of particular structure, the difference in model scores of at least 2 points is enough to claim the superiority of one model over the other. Using our findings, we derive several recommendations on using metrics to estimate the model performance on the code generation task.