 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Coordinated Rename Refactoring
Jan 01, 2026The primary value of AI agents in software development lies in their ability to extend the developer's capacity for reasoning and action, not to supplant human involvement. To showcase how to use agents working in tandem with developers, we designed a novel approach for carrying out coordinated renaming. Coordinated renaming, where a single rename refactoring triggers refactorings in multiple, related identifiers, is a frequent yet challenging task. Developers must manually propagate these rename refactorings across numerous files and contexts, a process that is both tedious and highly error-prone. State-of-the-art heuristic-based approaches produce an overwhelming number of false positives, while vanilla Large Language Models (LLMs) provide incomplete suggestions due to their limited context and inability to interact with refactoring tools. This leaves developers with incomplete refactorings or burdens them with filtering too many false positives. Coordinated renaming is exactly the kind of repetitive task that agents can significantly reduce the developers' burden while keeping them in the driver's seat. We designed, implemented, and evaluated the first multi-agent framework that automates coordinated renaming. It operates on a key insight: a developer's initial refactoring is a clue to infer the scope of related refactorings. Our Scope Inference Agent first transforms this clue into an explicit, natural-language Declared Scope. The Planned Execution Agent then uses this as a strict plan to identify program elements that should undergo refactoring and safely executes the changes by invoking the IDE's own trusted refactoring APIs. Finally, the Replication Agent uses it to guide the project-wide search. We first conducted a formative study on the practice of coordinated renaming in 609K commits in 100 open-source projects and surveyed 205 developers ...
Towards Realistic Evaluation of Commit Message Generation by Matching Online and Offline Settings
Oct 15, 2024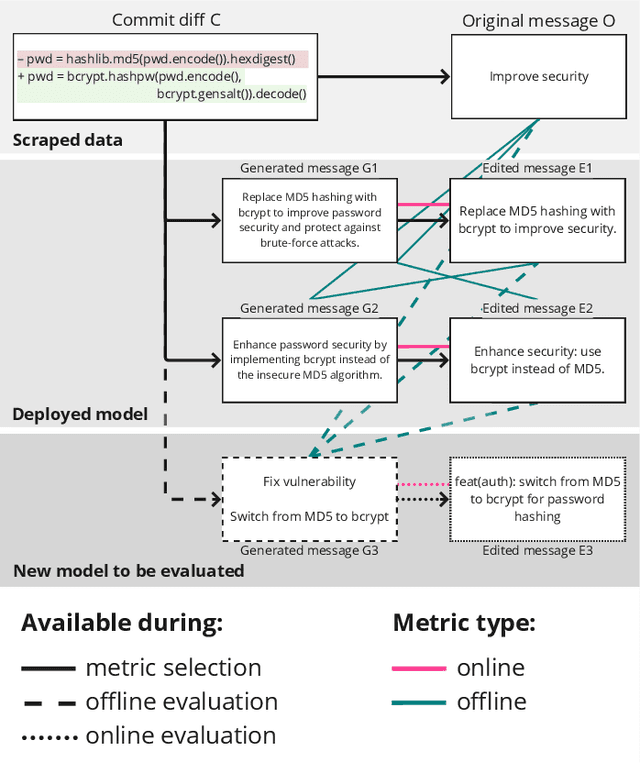
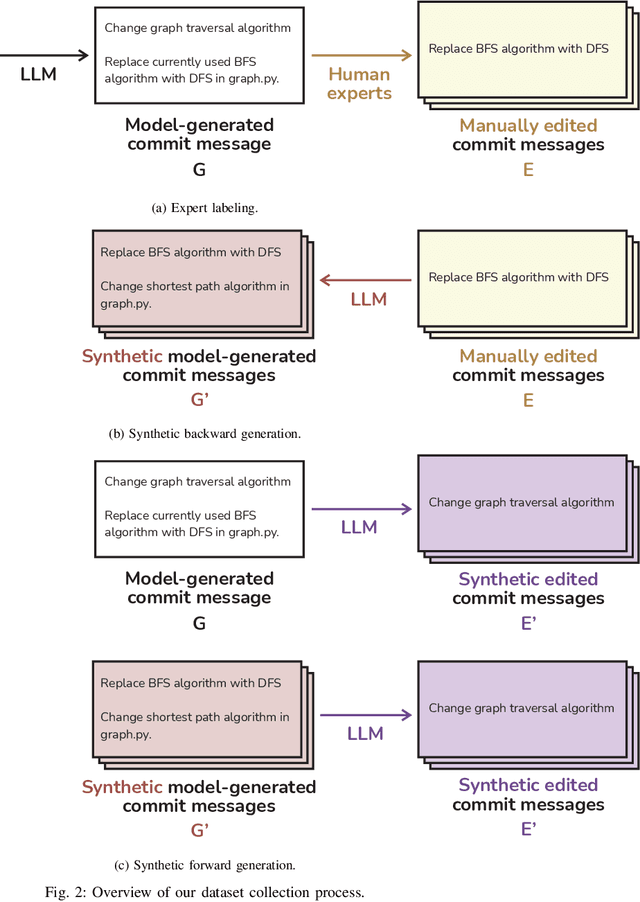
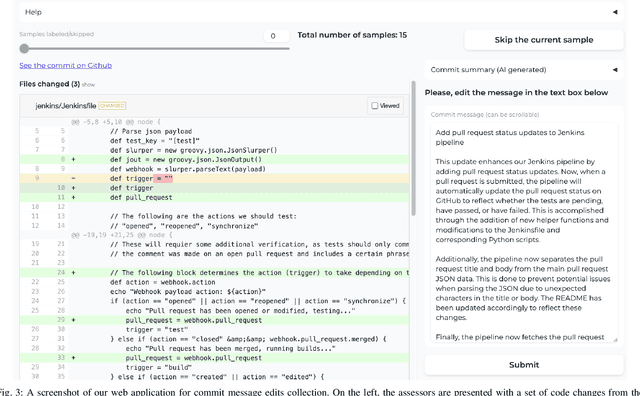
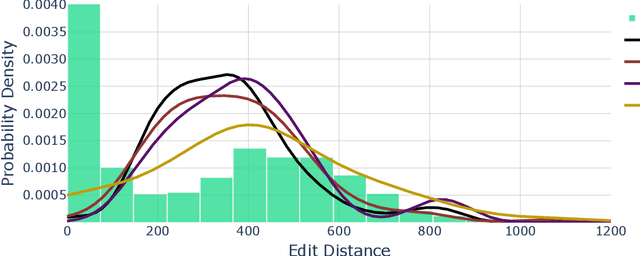
Commit message generation (CMG) is a crucial task in software engineering that is challenging to evaluate correctly. When a CMG system is integrated into the IDEs and other products at JetBrains, we perform online evaluation based on user acceptance of the generated messages. However, performing online experiments with every change to a CMG system is troublesome, as each iteration affects users and requires time to collect enough statistics. On the other hand, offline evaluation, a prevalent approach in the research literature, facilitates fast experiments but employs automatic metrics that are not guaranteed to represent the preferences of real users. In this work, we describe a novel way we employed to deal with this problem at JetBrains, by leveraging an online metric - the number of edits users introduce before committing the generated messages to the VCS - to select metrics for offline experiments. To support this new type of evaluation, we develop a novel markup collection tool mimicking the real workflow with a CMG system, collect a dataset with 57 pairs consisting of commit messages generated by GPT-4 and their counterparts edited by human experts, and design and verify a way to synthetically extend such a dataset. Then, we use the final dataset of 656 pairs to study how the widely used similarity metrics correlate with the online metric reflecting the real users' experience. Our results indicate that edit distance exhibits the highest correlation, whereas commonly used similarity metrics such as BLEU and METEOR demonstrate low correlation. This contradicts the previous studies on similarity metrics for CMG, suggesting that user interactions with a CMG system in real-world settings differ significantly from the responses by human labelers operating within controlled research environments. We release all the code and the dataset for researchers: https://jb.gg/cmg-evaluation.
EM-Assist: Safe Automated ExtractMethod Refactoring with LLMs
May 31, 2024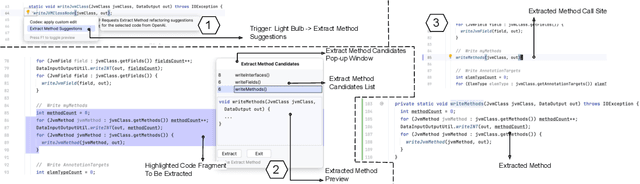
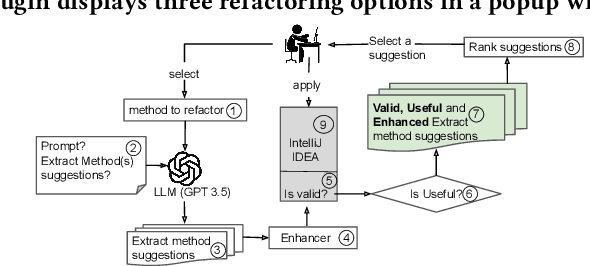

Excessively long methods, loaded with multiple responsibilities, are challenging to understand, debug, reuse, and maintain. The solution lies in the widely recognized Extract Method refactoring. While the application of this refactoring is supported in modern IDEs, recommending which code fragments to extract has been the topic of many research tools. However, they often struggle to replicate real-world developer practices, resulting in recommendations that do not align with what a human developer would do in real life. To address this issue, we introduce EM-Assist, an IntelliJ IDEA plugin that uses LLMs to generate refactoring suggestions and subsequently validates, enhances, and ranks them. Finally, EM-Assist uses the IntelliJ IDE to apply the user-selected recommendation. In our extensive evaluation of 1,752 real-world refactorings that actually took place in open-source projects, EM-Assist's recall rate was 53.4% among its top-5 recommendations, compared to 39.4% for the previous best-in-class tool that relies solely on static analysis. Moreover, we conducted a usability survey with 18 industrial developers and 94.4% gave a positive rating.
From Commit Message Generation to History-Aware Commit Message Completion
Aug 15, 2023



Commit messages are crucial to software development, allowing developers to track changes and collaborate effectively. Despite their utility, most commit messages lack important information since writing high-quality commit messages is tedious and time-consuming. The active research on commit message generation (CMG) has not yet led to wide adoption in practice. We argue that if we could shift the focus from commit message generation to commit message completion and use previous commit history as additional context, we could significantly improve the quality and the personal nature of the resulting commit messages. In this paper, we propose and evaluate both of these novel ideas. Since the existing datasets lack historical data, we collect and share a novel dataset called CommitChronicle, containing 10.7M commits across 20 programming languages. We use this dataset to evaluate the completion setting and the usefulness of the historical context for state-of-the-art CMG models and GPT-3.5-turbo. Our results show that in some contexts, commit message completion shows better results than generation, and that while in general GPT-3.5-turbo performs worse, it shows potential for long and detailed messages. As for the history, the results show that historical information improves the performance of CMG models in the generation task, and the performance of GPT-3.5-turbo in both generation and completion.