 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-XYZ: A Benchmark for Evaluating Diff Understanding
Oct 14, 2025Reliable handling of code diffs is central to agents that edit and refactor repositories at scale. We introduce Diff-XYZ, a compact benchmark for code-diff understanding with three supervised tasks: apply (old code $+$ diff $\rightarrow$ new code), anti-apply (new code $-$ diff $\rightarrow$ old code), and diff generation (new code $-$ old code $\rightarrow$ diff). Instances in the benchmark are triples $\langle \textit{old code}, \textit{new code}, \textit{diff} \rangle$ drawn from real commits in CommitPackFT, paired with automatic metrics and a clear evaluation protocol. We use the benchmark to do a focused empirical study of the unified diff format and run a cross-format comparison of different diff representations. Our findings reveal that different formats should be used depending on the use case and model size. For example, representing diffs in search-replace format is good for larger models in the diff generation scenario, yet not suited well for diff analysis and smaller models. The Diff-XYZ benchmark is a reusable foundation for assessing and improving diff handling in LLMs that can aid future development of diff formats and models editing code. The dataset is published on HuggingFace Hub: https://huggingface.co/datasets/JetBrains-Research/diff-xyz.
Challenge on Optimization of Context Collection for Code Completion
Oct 05, 2025



The rapid advancement of workflows and methods for software engineering using AI emphasizes the need for a systematic evaluation and analysis of their ability to leverage information from entire projects, particularly in large code bases. In this challenge on optimization of context collection for code completion, organized by JetBrains in collaboration with Mistral AI as part of the ASE 2025 conference, participants developed efficient mechanisms for collecting context from source code repositories to improve fill-in-the-middle code completions for Python and Kotlin. We constructed a large dataset of real-world code in these two programming languages using permissively licensed open-source projects. The submissions were evaluated based on their ability to maximize completion quality for multiple state-of-the-art neural models using the chrF metric. During the public phase of the competition, nineteen teams submitted solutions to the Python track and eight teams submitted solutions to the Kotlin track. In the private phase, six teams competed, of which five submitted papers to the workshop.
Towards Realistic Evaluation of Commit Message Generation by Matching Online and Offline Settings
Oct 15, 2024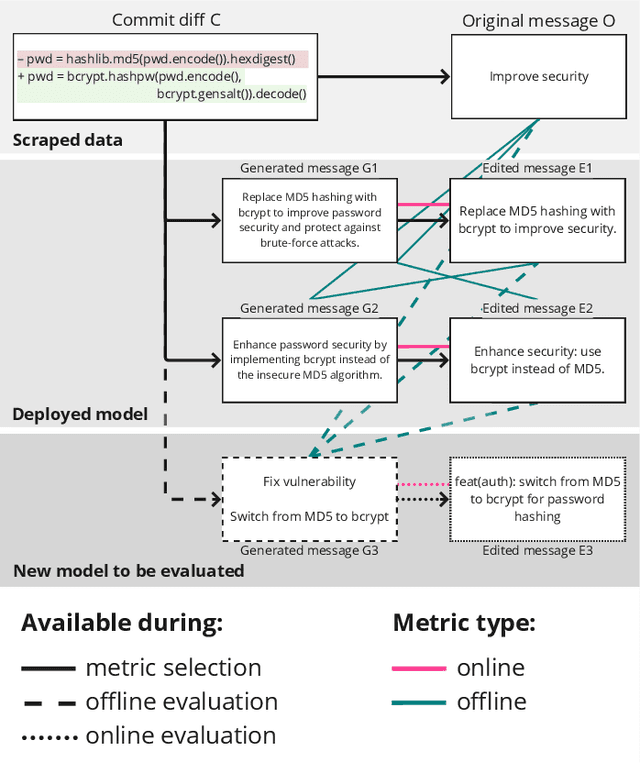
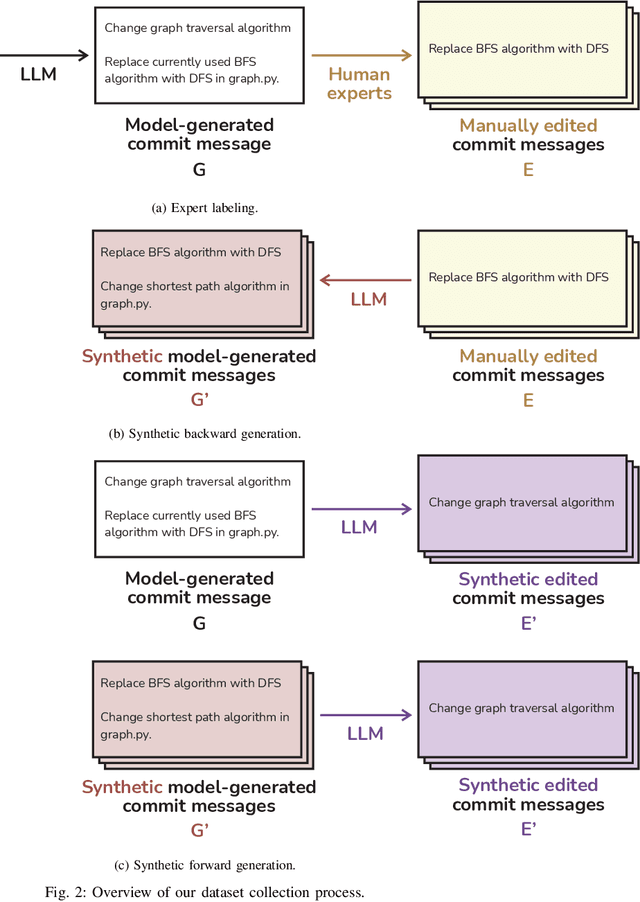
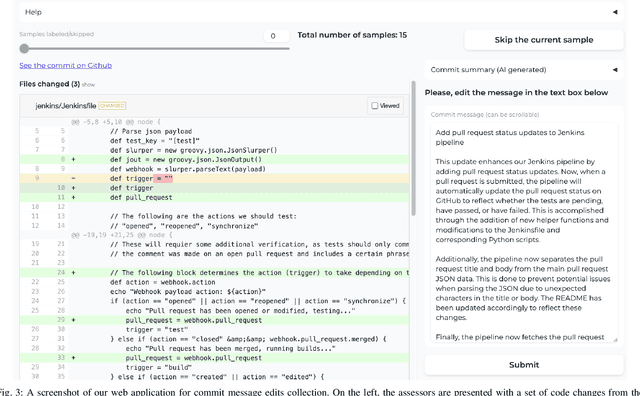
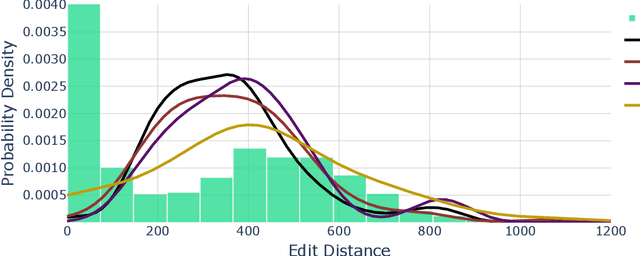
Commit message generation (CMG) is a crucial task in software engineering that is challenging to evaluate correctly. When a CMG system is integrated into the IDEs and other products at JetBrains, we perform online evaluation based on user acceptance of the generated messages. However, performing online experiments with every change to a CMG system is troublesome, as each iteration affects users and requires time to collect enough statistics. On the other hand, offline evaluation, a prevalent approach in the research literature, facilitates fast experiments but employs automatic metrics that are not guaranteed to represent the preferences of real users. In this work, we describe a novel way we employed to deal with this problem at JetBrains, by leveraging an online metric - the number of edits users introduce before committing the generated messages to the VCS - to select metrics for offline experiments. To support this new type of evaluation, we develop a novel markup collection tool mimicking the real workflow with a CMG system, collect a dataset with 57 pairs consisting of commit messages generated by GPT-4 and their counterparts edited by human experts, and design and verify a way to synthetically extend such a dataset. Then, we use the final dataset of 656 pairs to study how the widely used similarity metrics correlate with the online metric reflecting the real users' experience. Our results indicate that edit distance exhibits the highest correlation, whereas commonly used similarity metrics such as BLEU and METEOR demonstrate low correlation. This contradicts the previous studies on similarity metrics for CMG, suggesting that user interactions with a CMG system in real-world settings differ significantly from the responses by human labelers operating within controlled research environments. We release all the code and the dataset for researchers: https://jb.gg/cmg-evaluation.
All You Need Is Logs: Improving Code Completion by Learning from Anonymous IDE Usage Logs
May 21, 2022

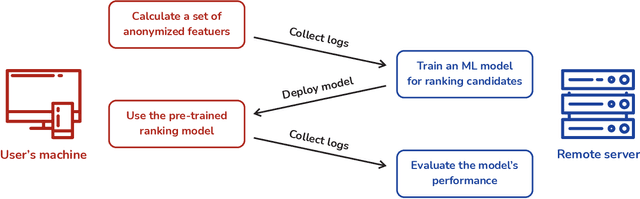
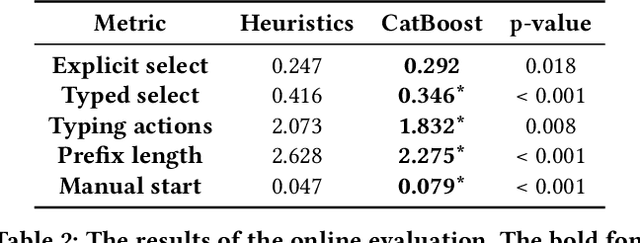
Integrated Development Environments (IDE) are designed to make users more productive, as well as to make their work more comfortable. To achieve this, a lot of diverse tools are embedded into IDEs, and the developers of IDEs can employ anonymous usage logs to collect the data about how they are being used to improve them. A particularly important component that this can be applied to is code completion, since improving code completion using statistical learning techniques is a well-established research area. In this work, we propose an approach for collecting completion usage logs from the users in an IDE and using them to train a machine learning based model for ranking completion candidates. We developed a set of features that describe completion candidates and their context, and deployed their anonymized collection in the Early Access Program of IntelliJ-based IDEs. We used the logs to collect a dataset of code completions from users, and employed it to train a ranking CatBoost model. Then, we evaluated it in two settings: on a held-out set of the collected completions and in a separate A/B test on two different groups of users in the IDE. Our evaluation shows that using a simple ranking model trained on the past user behavior logs significantly improved code completion experience. Compared to the default heuristics-based ranking, our model demonstrated a decrease in the number of typing actions necessary to perform the completion in the IDE from 2.073 to 1.832. The approach adheres to privacy requirements and legal constraints, since it does not require collecting personal information, performing all the necessary anonymization on the client's side. Importantly, it can be improved continuously: implementing new features, collecting new data, and evaluating new models - this way, we have been using it in production since the end of 2020.