 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Line Code Completion: Bringing AI to Desktop
May 14, 2024In recent years, several industrial solutions for the problem of multi-token code completion have appeared, each making a great advance in the area but mostly focusing on cloud-based runtime and avoiding working on the end user's device. In this work, we describe our approach for building a multi-token code completion feature for the JetBrains' IntelliJ Platform, which we call Full Line Code Completion. The feature suggests only syntactically correct code and works fully locally, i.e., data querying and the generation of suggestions happens on the end user's machine. We share important time and memory-consumption restrictions, as well as design principles that a code completion engine should satisfy. Working entirely on the end user's device, our code completion engine enriches user experience while being not only fast and compact but also secure. We share a number of useful techniques to meet the stated development constraints and also describe offline and online evaluation pipelines that allowed us to make better decisions. Our online evaluation shows that the usage of the tool leads to 1.5 times more code in the IDE being produced by code completion. The described solution was initially started with the help of researchers and was bundled into two JetBrains' IDEs - PyCharm Pro and DataSpell - at the end of 2023, so we believe that this work is useful for bridging academia and industry, providing researchers with the knowledge of what happens when complex research-based solutions are integrated into real products.
All You Need Is Logs: Improving Code Completion by Learning from Anonymous IDE Usage Logs
May 21, 2022

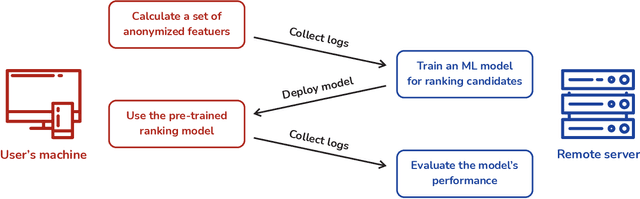
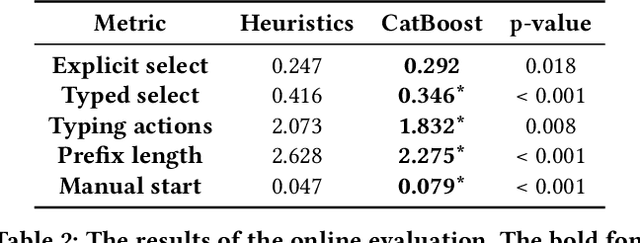
Integrated Development Environments (IDE) are designed to make users more productive, as well as to make their work more comfortable. To achieve this, a lot of diverse tools are embedded into IDEs, and the developers of IDEs can employ anonymous usage logs to collect the data about how they are being used to improve them. A particularly important component that this can be applied to is code completion, since improving code completion using statistical learning techniques is a well-established research area. In this work, we propose an approach for collecting completion usage logs from the users in an IDE and using them to train a machine learning based model for ranking completion candidates. We developed a set of features that describe completion candidates and their context, and deployed their anonymized collection in the Early Access Program of IntelliJ-based IDEs. We used the logs to collect a dataset of code completions from users, and employed it to train a ranking CatBoost model. Then, we evaluated it in two settings: on a held-out set of the collected completions and in a separate A/B test on two different groups of users in the IDE. Our evaluation shows that using a simple ranking model trained on the past user behavior logs significantly improved code completion experience. Compared to the default heuristics-based ranking, our model demonstrated a decrease in the number of typing actions necessary to perform the completion in the IDE from 2.073 to 1.832. The approach adheres to privacy requirements and legal constraints, since it does not require collecting personal information, performing all the necessary anonymization on the client's side. Importantly, it can be improved continuously: implementing new features, collecting new data, and evaluating new models - this way, we have been using it in production since the end of 2020.