 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKotlin ML Pack: Technical Report
May 29, 2024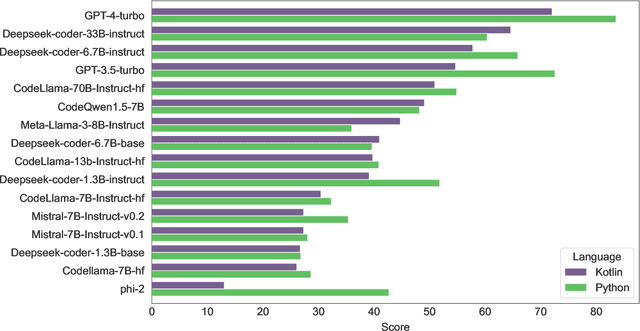
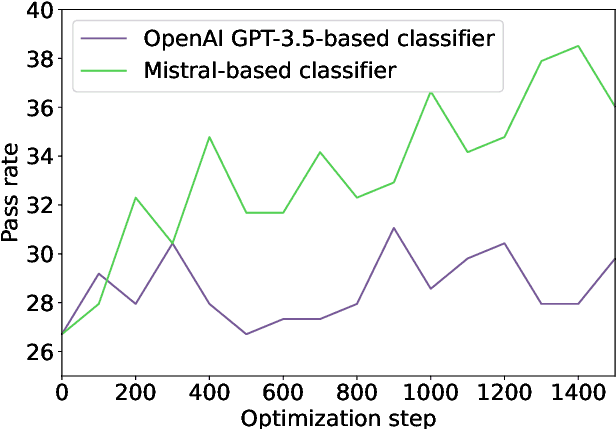
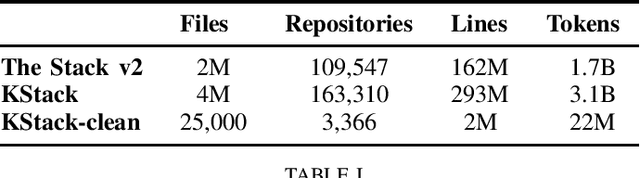
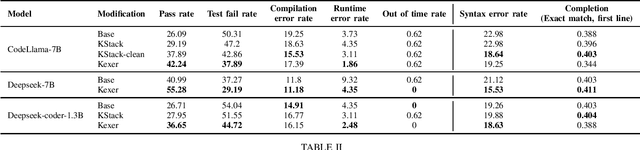
In this technical report, we present three novel datasets of Kotlin code: KStack, KStack-clean, and KExercises. We also describe the results of fine-tuning CodeLlama and DeepSeek models on this data. Additionally, we present a version of the HumanEval benchmark rewritten by human experts into Kotlin - both the solutions and the tests. Our results demonstrate that small, high-quality datasets (KStack-clean and KExercises) can significantly improve model performance on code generation tasks, achieving up to a 16-point increase in pass rate on the HumanEval benchmark. Lastly, we discuss potential future work in the field of improving language modeling for Kotlin, including the use of static analysis tools in the learning process and the introduction of more intricate and realistic benchmarks.
Judging Adam: Studying the Performance of Optimization Methods on ML4SE Tasks
Mar 06, 2023



Solving a problem with a deep learning model requires researchers to optimize the loss function with a certain optimization method. The research community has developed more than a hundred different optimizers, yet there is scarce data on optimizer performance in various tasks. In particular, none of the benchmarks test the performance of optimizers on source code-related problems. However, existing benchmark data indicates that certain optimizers may be more efficient for particular domains. In this work, we test the performance of various optimizers on deep learning models for source code and find that the choice of an optimizer can have a significant impact on the model quality, with up to two-fold score differences between some of the relatively well-performing optimizers. We also find that RAdam optimizer (and its modification with the Lookahead envelope) is the best optimizer that almost always performs well on the tasks we consider. Our findings show a need for a more extensive study of the optimizers in code-related tasks, and indicate that the ML4SE community should consider using RAdam instead of Adam as the default optimizer for code-related deep learning tasks.
Out of the BLEU: how should we assess quality of the Code Generation models?
Aug 05, 2022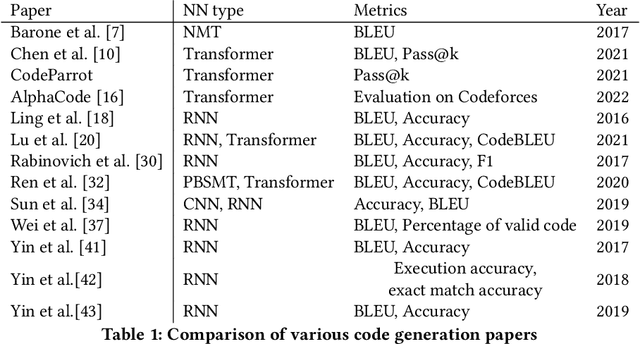

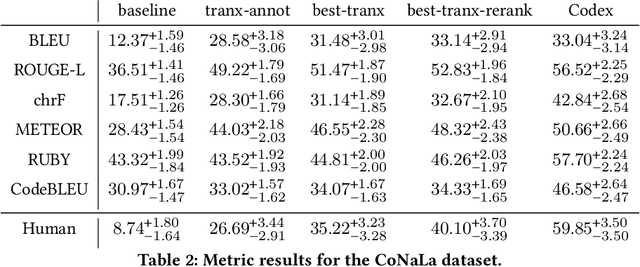
In recent years, researchers have created and introduced a significant number of various code generation models. As human evaluation of every new model version is unfeasible, the community adopted automatic evaluation metrics such as BLEU to approximate the results of human judgement. These metrics originate from the machine translation domain and it is unclear whether they are applicable for the code generation tasks and how well do they agree with the human evaluation on this task. There also are two metrics, CodeBLEU and RUBY, that were developed to estimate the similarity of code and take into account the code properties. However, for these metrics there are hardly any studies on their agreement with the human evaluation. Despite all that, minimal differences in the metric scores are used to claim superiority of some code generation models over the others. In this paper, we present a study on applicability of six metrics -- BLEU, ROUGE-L, METEOR, ChrF, CodeBLEU, RUBY -- for evaluation of the code generation models. We conduct a study on two different code generation datasets and use human annotators to assess the quality of all models run on these datasets. The results indicate that for the CoNaLa dataset of Python one-liners none of the metrics can correctly emulate human judgement on which model is better with $>95\%$ certainty if the difference in model scores is less than 5 points. For the HearthStone dataset, which consists of classes of particular structure, the difference in model scores of at least 2 points is enough to claim the superiority of one model over the other. Using our findings, we derive several recommendations on using metrics to estimate the model performance on the code generation task.