 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKotlin ML Pack: Technical Report
Paper and Code
May 29, 2024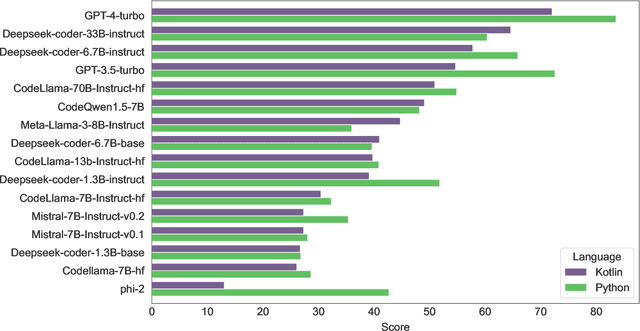
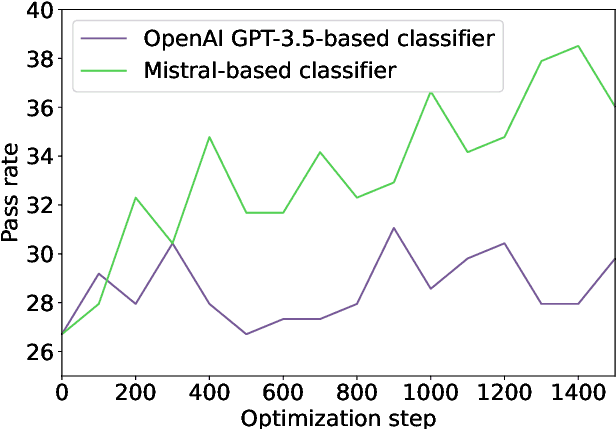
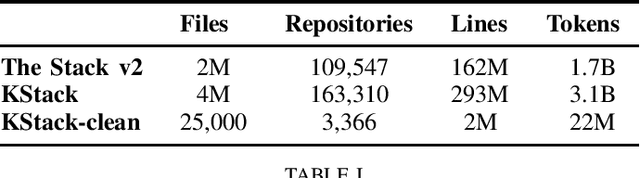
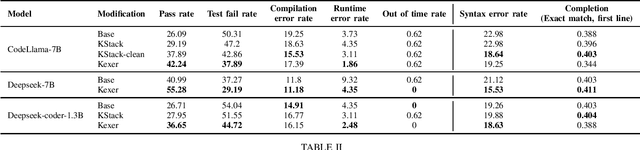
In this technical report, we present three novel datasets of Kotlin code: KStack, KStack-clean, and KExercises. We also describe the results of fine-tuning CodeLlama and DeepSeek models on this data. Additionally, we present a version of the HumanEval benchmark rewritten by human experts into Kotlin - both the solutions and the tests. Our results demonstrate that small, high-quality datasets (KStack-clean and KExercises) can significantly improve model performance on code generation tasks, achieving up to a 16-point increase in pass rate on the HumanEval benchmark. Lastly, we discuss potential future work in the field of improving language modeling for Kotlin, including the use of static analysis tools in the learning process and the introduction of more intricate and realistic benchmarks.