 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Language You Ask In: Language-Conditioned Ideological Divergence in LLM Analysis of Contested Political Documents
Jan 17, 2026Large language models (LLMs) are increasingly deployed as analytical tools across multilingual contexts, yet their outputs may carry systematic biases conditioned by the language of the prompt. This study presents an experimental comparison of LLM-generated political analyses of a Ukrainian civil society document, using semantically equivalent prompts in Russian and Ukrainian. Despite identical source material and parallel query structures, the resulting analyses varied substantially in rhetorical positioning, ideological orientation, and interpretive conclusions. The Russian-language output echoed narratives common in Russian state discourse, characterizing civil society actors as illegitimate elites undermining democratic mandates. The Ukrainian-language output adopted vocabulary characteristic of Western liberal-democratic political science, treating the same actors as legitimate stakeholders within democratic contestation. These findings demonstrate that prompt language alone can produce systematically different ideological orientations from identical models analyzing identical content, with significant implications for AI deployment in polarized information environments, cross-lingual research applications, and the governance of AI systems in multilingual societies.
Frequency Matters: When Time Series Foundation Models Fail Under Spectral Shift
Nov 06, 2025Time series foundation models (TSFMs) have shown strong results on public benchmarks, prompting comparisons to a "BERT moment" for time series. Their effectiveness in industrial settings, however, remains uncertain. We examine why TSFMs often struggle to generalize and highlight spectral shift (a mismatch between the dominant frequency components in downstream tasks and those represented during pretraining) as a key factor. We present evidence from an industrial-scale player engagement prediction task in mobile gaming, where TSFMs underperform domain-adapted baselines. To isolate the mechanism, we design controlled synthetic experiments contrasting signals with seen versus unseen frequency bands, observing systematic degradation under spectral mismatch. These findings position frequency awareness as critical for robust TSFM deployment and motivate new pretraining and evaluation protocols that explicitly account for spectral diversity.
Enhancing Graph Classification Robustness with Singular Pooling
Oct 26, 2025Graph Neural Networks (GNNs) have achieved strong performance across a range of graph representation learning tasks, yet their adversarial robustness in graph classification remains underexplored compared to node classification. While most existing defenses focus on the message-passing component, this work investigates the overlooked role of pooling operations in shaping robustness. We present a theoretical analysis of standard flat pooling methods (sum, average and max), deriving upper bounds on their adversarial risk and identifying their vulnerabilities under different attack scenarios and graph structures. Motivated by these insights, we propose \textit{Robust Singular Pooling (RS-Pool)}, a novel pooling strategy that leverages the dominant singular vector of the node embedding matrix to construct a robust graph-level representation. We theoretically investigate the robustness of RS-Pool and interpret the resulting bound leading to improved understanding of our proposed pooling operator. While our analysis centers on Graph Convolutional Networks (GCNs), RS-Pool is model-agnostic and can be implemented efficiently via power iteration. Empirical results on real-world benchmarks show that RS-Pool provides better robustness than the considered pooling methods when subject to state-of-the-art adversarial attacks while maintaining competitive clean accuracy. Our code is publicly available at:\href{https://github.com/king/rs-pool}{https://github.com/king/rs-pool}.
Are We Really Measuring Progress? Transferring Insights from Evaluating Recommender Systems to Temporal Link Prediction
Jun 14, 2025Recent work has questioned the reliability of graph learning benchmarks, citing concerns around task design, methodological rigor, and data suitability. In this extended abstract, we contribute to this discussion by focusing on evaluation strategies in Temporal Link Prediction (TLP). We observe that current evaluation protocols are often affected by one or more of the following issues: (1) inconsistent sampled metrics, (2) reliance on hard negative sampling often introduced as a means to improve robustness, and (3) metrics that implicitly assume equal base probabilities across source nodes by combining predictions. We support these claims through illustrative examples and connections to longstanding concerns in the recommender systems community. Our ongoing work aims to systematically characterize these problems and explore alternatives that can lead to more robust and interpretable evaluation. We conclude with a discussion of potential directions for improving the reliability of TLP benchmarks.
Enhancing Pre-Trained Decision Transformers with Prompt-Tuning Bandits
Feb 10, 2025Harnessing large offline datasets is vital for training foundation models that can generalize across diverse tasks. Offline Reinforcement Learning (RL) offers a powerful framework for these scenarios, enabling the derivation of optimal policies even from suboptimal data. The Prompting Decision Transformer (PDT) is an offline RL multi-task model that distinguishes tasks through stochastic trajectory prompts, which are task-specific tokens maintained in context during rollouts. However, PDT samples these tokens uniformly at random from per-task demonstration datasets, failing to account for differences in token informativeness and potentially leading to performance degradation. To address this limitation, we introduce a scalable bandit-based prompt-tuning method that dynamically learns to construct high-performance trajectory prompts. Our approach significantly enhances downstream task performance without modifying the pre-trained Transformer backbone. Empirical results on benchmark tasks and a newly designed multi-task environment demonstrate the effectiveness of our method, creating a seamless bridge between general multi-task offline pre-training and task-specific online adaptation.
Towards bandit-based prompt-tuning for in-the-wild foundation agents
Feb 10, 2025Prompting has emerged as the dominant paradigm for adapting large, pre-trained transformer-based models to downstream tasks. The Prompting Decision Transformer (PDT) enables large-scale, multi-task offline reinforcement learning pre-training by leveraging stochastic trajectory prompts to identify the target task. However, these prompts are sampled uniformly from expert demonstrations, overlooking a critical limitation: Not all prompts are equally informative for differentiating between tasks. To address this, we propose an inference time bandit-based prompt-tuning framework that explores and optimizes trajectory prompt selection to enhance task performance. Our experiments indicate not only clear performance gains due to bandit-based prompt-tuning, but also better sample complexity, scalability, and prompt space exploration compared to prompt-tuning baselines.
On the Power of Heuristics in Temporal Graphs
Feb 07, 2025Dynamic graph datasets often exhibit strong temporal patterns, such as recency, which prioritizes recent interactions, and popularity, which favors frequently occurring nodes. We demonstrate that simple heuristics leveraging only these patterns can perform on par or outperform state-of-the-art neural network models under standard evaluation protocols. To further explore these dynamics, we introduce metrics that quantify the impact of recency and popularity across datasets. Our experiments on BenchTemp and the Temporal Graph Benchmark show that our approaches achieve state-of-the-art performance across all datasets in the latter and secure top ranks on multiple datasets in the former. These results emphasize the importance of refined evaluation schemes to enable fair comparisons and promote the development of more robust temporal graph models. Additionally, they reveal that current deep learning methods often struggle to capture the key patterns underlying predictions in real-world temporal graphs. For reproducibility, we have made our code publicly available.
Unified Approaches in Self-Supervised Event Stream Modeling: Progress and Prospects
Feb 07, 2025



The proliferation of digital interactions across diverse domains, such as healthcare, e-commerce, gaming, and finance, has resulted in the generation of vast volumes of event stream (ES) data. ES data comprises continuous sequences of timestamped events that encapsulate detailed contextual information relevant to each domain. While ES data holds significant potential for extracting actionable insights and enhancing decision-making, its effective utilization is hindered by challenges such as the scarcity of labeled data and the fragmented nature of existing research efforts. Self-Supervised Learning (SSL) has emerged as a promising paradigm to address these challenges by enabling the extraction of meaningful representations from unlabeled ES data. In this survey, we systematically review and synthesize SSL methodologies tailored for ES modeling across multiple domains, bridging the gaps between domain-specific approaches that have traditionally operated in isolation. We present a comprehensive taxonomy of SSL techniques, encompassing both predictive and contrastive paradigms, and analyze their applicability and effectiveness within different application contexts. Furthermore, we identify critical gaps in current research and propose a future research agenda aimed at developing scalable, domain-agnostic SSL frameworks for ES modeling. By unifying disparate research efforts and highlighting cross-domain synergies, this survey aims to accelerate innovation, improve reproducibility, and expand the applicability of SSL to diverse real-world ES challenges.
Expressivity of Representation Learning on Continuous-Time Dynamic Graphs: An Information-Flow Centric Review
Dec 05, 2024Graphs are ubiquitous in real-world applications, ranging from social networks to biological systems, and have inspired the development of Graph Neural Networks (GNNs) for learning expressive representations. While most research has centered on static graphs, many real-world scenarios involve dynamic, temporally evolving graphs, motivating the need for Continuous-Time Dynamic Graph (CTDG) models. This paper provides a comprehensive review of Graph Representation Learning (GRL) on CTDGs with a focus on Self-Supervised Representation Learning (SSRL). We introduce a novel theoretical framework that analyzes the expressivity of CTDG models through an Information-Flow (IF) lens, quantifying their ability to propagate and encode temporal and structural information. Leveraging this framework, we categorize existing CTDG methods based on their suitability for different graph types and application scenarios. Within the same scope, we examine the design of SSRL methods tailored to CTDGs, such as predictive and contrastive approaches, highlighting their potential to mitigate the reliance on labeled data. Empirical evaluations on synthetic and real-world datasets validate our theoretical insights, demonstrating the strengths and limitations of various methods across long-range, bi-partite and community-based graphs. This work offers both a theoretical foundation and practical guidance for selecting and developing CTDG models, advancing the understanding of GRL in dynamic settings.
Understanding Players as if They Are Talking to the Game in a Customized Language: A Pilot Study
Oct 24, 2024

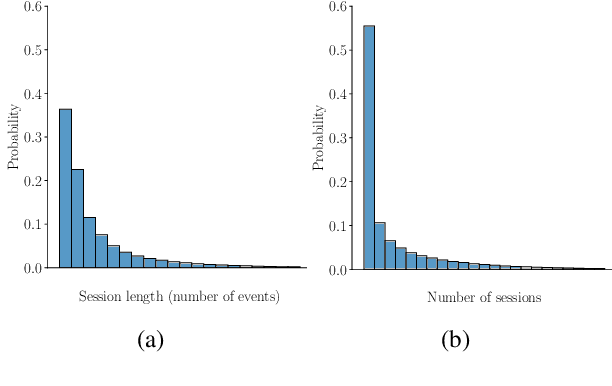

This pilot study explores the application of language models (LMs) to model game event sequences, treating them as a customized natural language. We investigate a popular mobile game, transforming raw event data into textual sequences and pretraining a Longformer model on this data. Our approach captures the rich and nuanced interactions within game sessions, effectively identifying meaningful player segments. The results demonstrate the potential of self-supervised LMs in enhancing game design and personalization without relying on ground-truth labels.