 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCramming 1568 Tokens into a Single Vector and Back Again: Exploring the Limits of Embedding Space Capacity
Feb 18, 2025A range of recent works addresses the problem of compression of sequence of tokens into a shorter sequence of real-valued vectors to be used as inputs instead of token embeddings or key-value cache. These approaches allow to reduce the amount of compute in existing language models. Despite relying on powerful models as encoders, the maximum attainable lossless compression ratio is typically not higher than x10. This fact is highly intriguing because, in theory, the maximum information capacity of large real-valued vectors is far beyond the presented rates even for 16-bit precision and a modest vector size. In this work, we explore the limits of compression by replacing the encoder with a per-sample optimization procedure. We show that vectors with compression ratios up to x1500 exist, which highlights two orders of magnitude gap between existing and practically attainable solutions. Furthermore, we empirically show that the compression limits are determined not by the length of the input but by the amount of uncertainty to be reduced, namely, the cross-entropy loss on this sequence without any conditioning. The obtained limits highlight the substantial gap between the theoretical capacity of input embeddings and their practical utilization, suggesting significant room for optimization in model design.
Kotlin ML Pack: Technical Report
May 29, 2024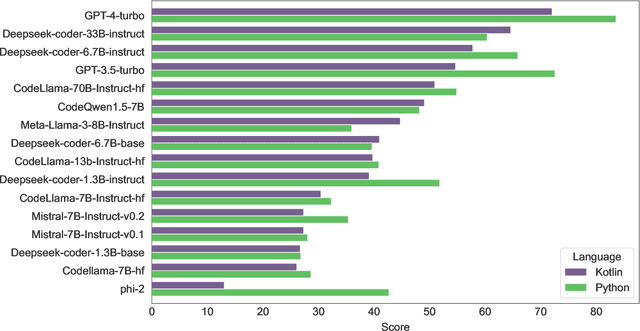
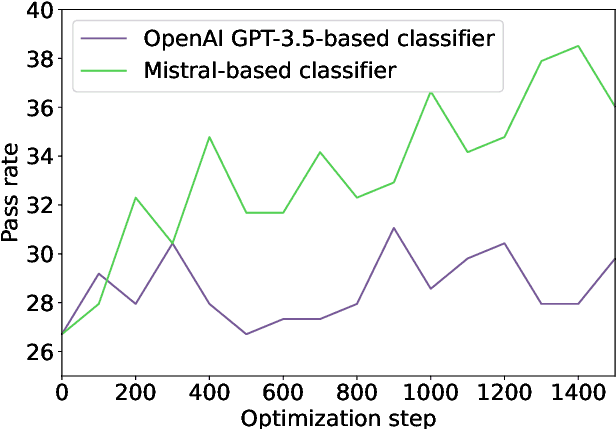
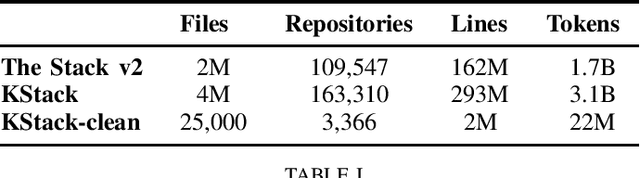
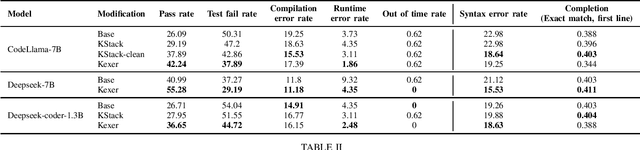
In this technical report, we present three novel datasets of Kotlin code: KStack, KStack-clean, and KExercises. We also describe the results of fine-tuning CodeLlama and DeepSeek models on this data. Additionally, we present a version of the HumanEval benchmark rewritten by human experts into Kotlin - both the solutions and the tests. Our results demonstrate that small, high-quality datasets (KStack-clean and KExercises) can significantly improve model performance on code generation tasks, achieving up to a 16-point increase in pass rate on the HumanEval benchmark. Lastly, we discuss potential future work in the field of improving language modeling for Kotlin, including the use of static analysis tools in the learning process and the introduction of more intricate and realistic benchmarks.
Neural Entity Linking: A Survey of Models based on Deep Learning
May 31, 2020
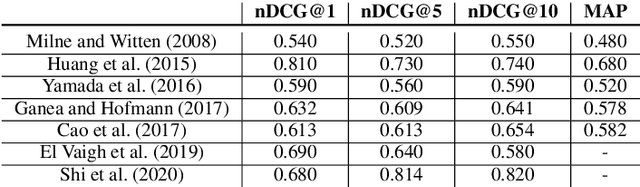
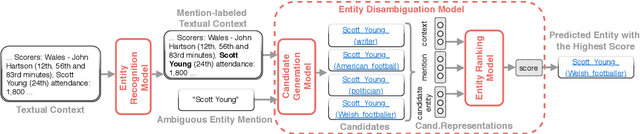
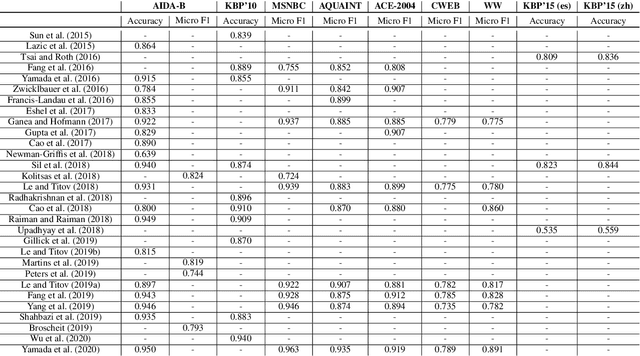
In this survey, we provide a comprehensive description of recent neural entity linking (EL) systems. We distill their generic architecture that includes candidate generation, entity ranking, and unlinkable mention prediction components. For each of them, we summarize the prominent methods and models, including approaches to mention encoding based on the self-attention architecture. Since many EL models take advantage of entity embeddings to improve their generalization capabilities, we provide an overview of the widely-used entity embedding techniques. We group the variety of EL approaches by several common research directions: joint entity recognition and linking, models for global EL, domain-independent techniques including zero-shot and distant supervision methods, and cross-lingual approaches. We also discuss the novel application of EL for enhancing word representation models like BERT. We systemize the critical design features of EL systems and provide their reported evaluation results.
Adaptation of Deep Bidirectional Multilingual Transformers for Russian Language
May 17, 2019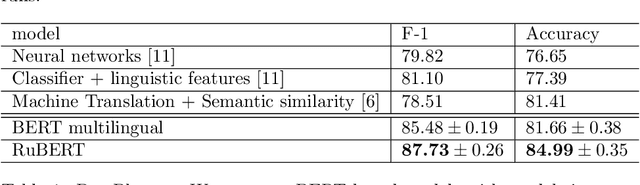
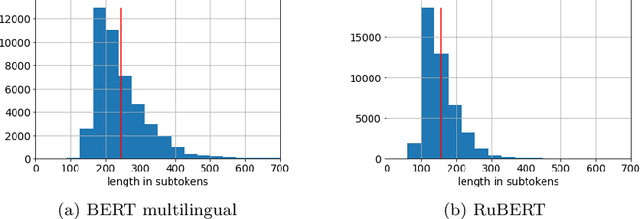
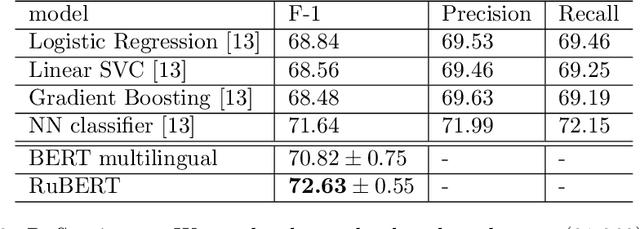
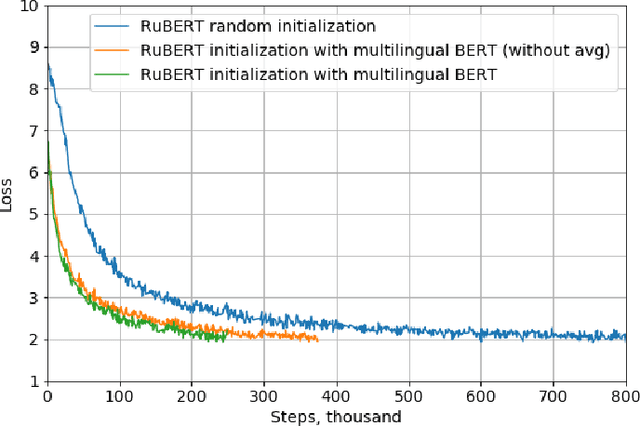
The paper introduces methods of adaptation of multilingual masked language models for a specific language. Pre-trained bidirectional language models show state-of-the-art performance on a wide range of tasks including reading comprehension, natural language inference, and sentiment analysis. At the moment there are two alternative approaches to train such models: monolingual and multilingual. While language specific models show superior performance, multilingual models allow to perform a transfer from one language to another and solve tasks for different languages simultaneously. This work shows that transfer learning from a multilingual model to monolingual model results in significant growth of performance on such tasks as reading comprehension, paraphrase detection, and sentiment analysis. Furthermore, multilingual initialization of monolingual model substantially reduces training time. Pre-trained models for the Russian language are open sourced.