 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Code Arena: a Set of Benchmarks for Long-Context Code Models
Jun 17, 2024



Nowadays, the fields of code and natural language processing are evolving rapidly. In particular, models become better at processing long context windows - supported context sizes have increased by orders of magnitude over the last few years. However, there is a shortage of benchmarks for code processing that go beyond a single file of context, while the most popular ones are limited to a single method. With this work, we aim to close this gap by introducing Long Code Arena, a suite of six benchmarks for code processing tasks that require project-wide context. These tasks cover different aspects of code processing: library-based code generation, CI builds repair, project-level code completion, commit message generation, bug localization, and module summarization. For each task, we provide a manually verified dataset for testing, an evaluation suite, and open-source baseline solutions based on popular LLMs to showcase the usage of the dataset and to simplify adoption by other researchers. We publish the benchmark page on HuggingFace Spaces with the leaderboard, links to HuggingFace Hub for all the datasets, and link to the GitHub repository with baselines: https://huggingface.co/spaces/JetBrains-Research/long-code-arena.
Kotlin ML Pack: Technical Report
May 29, 2024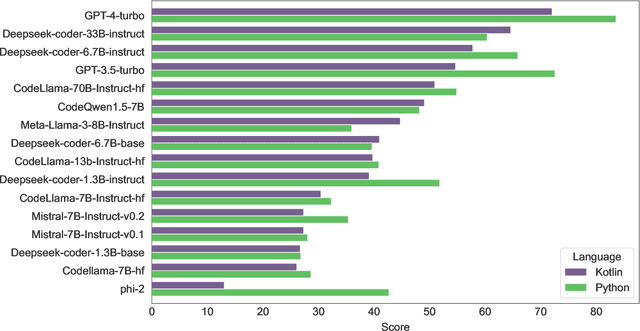
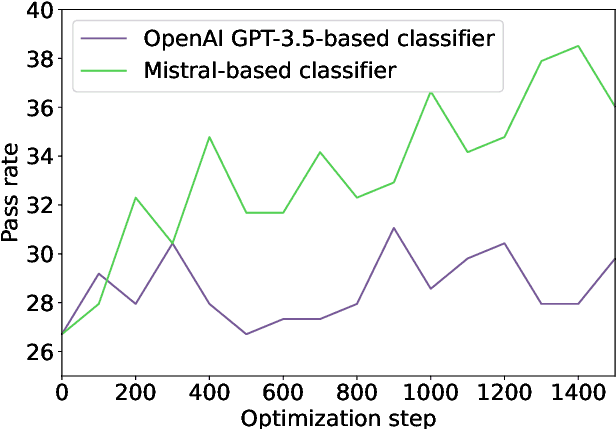
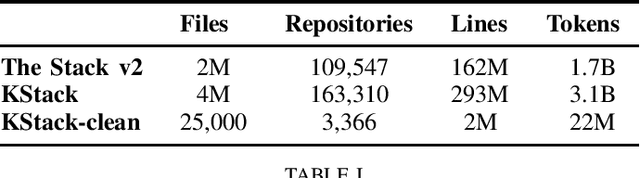
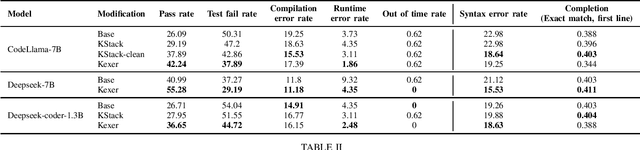
In this technical report, we present three novel datasets of Kotlin code: KStack, KStack-clean, and KExercises. We also describe the results of fine-tuning CodeLlama and DeepSeek models on this data. Additionally, we present a version of the HumanEval benchmark rewritten by human experts into Kotlin - both the solutions and the tests. Our results demonstrate that small, high-quality datasets (KStack-clean and KExercises) can significantly improve model performance on code generation tasks, achieving up to a 16-point increase in pass rate on the HumanEval benchmark. Lastly, we discuss potential future work in the field of improving language modeling for Kotlin, including the use of static analysis tools in the learning process and the introduction of more intricate and realistic benchmarks.
Entity-Augmented Code Generation
Dec 14, 2023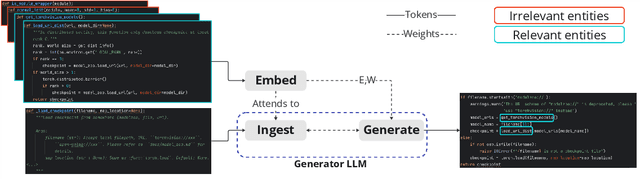
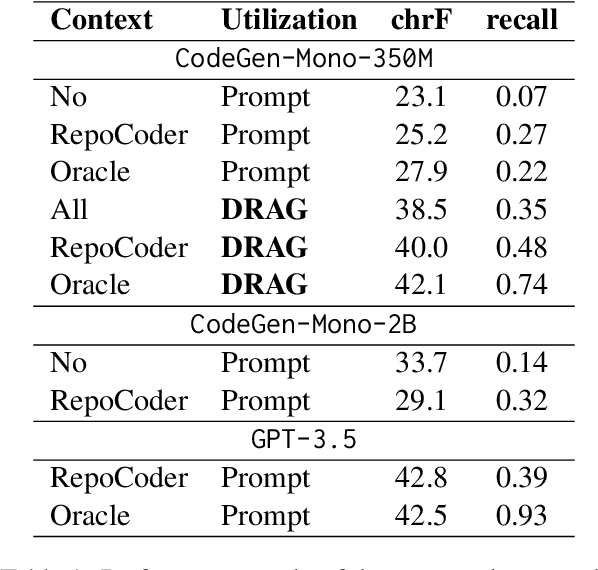
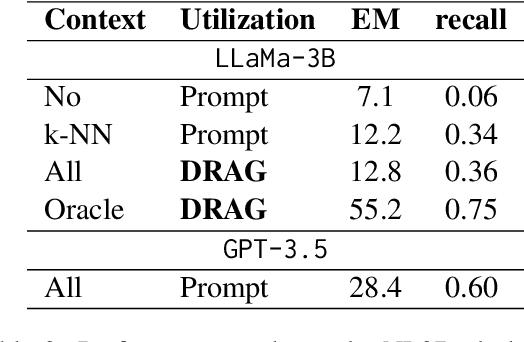
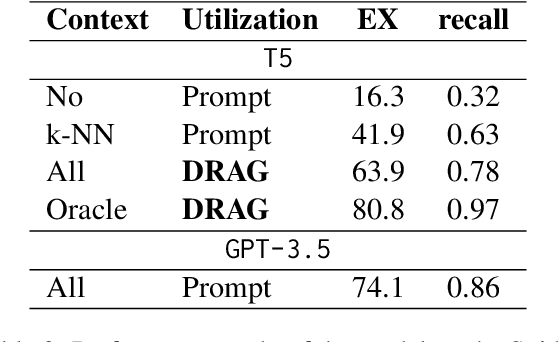
The current state-of-the-art large language models (LLMs) are effective in generating high-quality text and encapsulating a broad spectrum of world knowledge. However, these models often hallucinate during generation and are not designed to utilize external information sources. To enable requests to the external knowledge bases, also called knowledge grounding, retrieval-augmented LLMs were introduced. For now, their applications have largely involved Open Domain Question Answering, Abstractive Question Answering, and such. In this paper, we broaden the scope of retrieval-augmented LLMs by venturing into a new task - code generation using external entities. For this task, we collect and publish a new dataset for project-level code generation, where the model should reuse functions defined in the project during generation. As we show, existing retrieval-augmented LLMs fail to assign relevance scores between similar entity names, and to mitigate it, they expand entity names with description context and append it to the input. In practice, due to the limited context size they can not accommodate the indefinitely large context of the whole project. To solve this issue, we propose a novel end-to-end trainable architecture with an scalable entity retriever injected directly into the LLM decoder. We demonstrate that our model can outperform common baselines in several scenarios, including project-level code generation, as well as Bash and SQL scripting.