 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-Augmented Code Generation
Paper and Code
Dec 14, 2023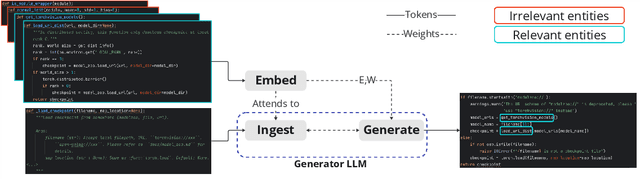
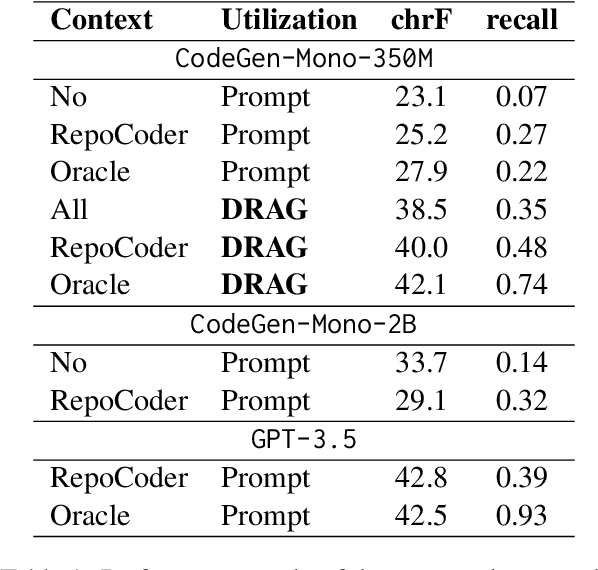
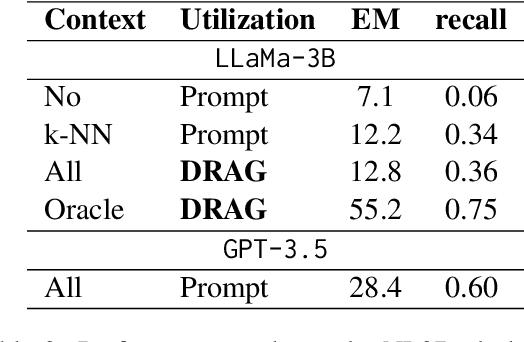
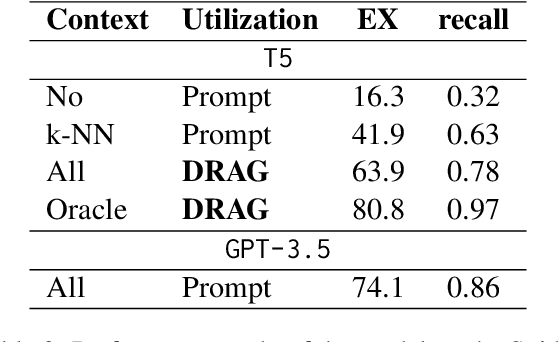
The current state-of-the-art large language models (LLMs) are effective in generating high-quality text and encapsulating a broad spectrum of world knowledge. However, these models often hallucinate during generation and are not designed to utilize external information sources. To enable requests to the external knowledge bases, also called knowledge grounding, retrieval-augmented LLMs were introduced. For now, their applications have largely involved Open Domain Question Answering, Abstractive Question Answering, and such. In this paper, we broaden the scope of retrieval-augmented LLMs by venturing into a new task - code generation using external entities. For this task, we collect and publish a new dataset for project-level code generation, where the model should reuse functions defined in the project during generation. As we show, existing retrieval-augmented LLMs fail to assign relevance scores between similar entity names, and to mitigate it, they expand entity names with description context and append it to the input. In practice, due to the limited context size they can not accommodate the indefinitely large context of the whole project. To solve this issue, we propose a novel end-to-end trainable architecture with an scalable entity retriever injected directly into the LLM decoder. We demonstrate that our model can outperform common baselines in several scenarios, including project-level code generation, as well as Bash and SQL scripting.