 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibEvoBench: Probing Temporal Knowledge Stratification in Code Generation Models
Jun 24, 2026Large software projects often depend on older versions of libraries, even as APIs continue to evolve across releases. This creates a challenge for LLMs: they must maintain knowledge of multiple API versions, not merely the latest or most common one. However, current LLMs are trained on temporally mixed corpora and lack explicit mechanisms for such version-specific reasoning, leading to anachronistic errors - calling APIs as they exist in a different library version. To systematically evaluate this phenomenon, we introduce LibEvoBench, a multi-task benchmark spanning multiple versions of widely used Python libraries, along with a new metric, the Software Evolution Understanding Score (SEUS), to measure models' consistency when working with evolving APIs. Our results show that state-of-the-art models are largely version-oblivious: performance degrades for evolving APIs, while for stable APIs it remains the same across versions. Moreover, simply specifying the target version provides no benefit, while relevant documentation significantly boosts models' accuracy. These findings highlight a systematic limitation of current training paradigms and motivate new approaches for temporally grounded knowledge in code generation.
Does In-IDE Calibration of Large Language Models work at Scale?
Oct 26, 2025



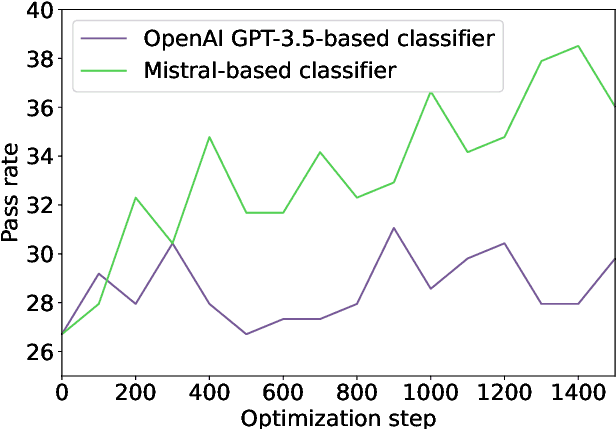
The introduction of large language models into integrated development environments (IDEs) is revolutionizing software engineering, yet it poses challenges to the usefulness and reliability of Artificial Intelligence-generated code. Post-hoc calibration of internal model confidences aims to align probabilities with an acceptability measure. Prior work suggests calibration can improve alignment, but at-scale evidence is limited. In this work, we investigate the feasibility of applying calibration of code models to an in-IDE context. We study two aspects of the problem: (1) the technical method for implementing confidence calibration and improving the reliability of code generation models, and (2) the human-centered design principles for effectively communicating reliability signal to developers. First, we develop a scalable and flexible calibration framework which can be used to obtain calibration weights for open-source models using any dataset, and evaluate whether calibrators improve the alignment between model confidence and developer acceptance behavior. Through a large-scale analysis of over 24 million real-world developer interactions across multiple programming languages, we find that a general, post-hoc calibration model based on Platt-scaling does not, on average, improve the reliability of model confidence signals. We also find that while dynamically personalizing calibration to individual users can be effective, its effectiveness is highly dependent on the volume of user interaction data. Second, we conduct a multi-phase design study with 3 expert designers and 153 professional developers, combining scenario-based design, semi-structured interviews, and survey validation, revealing a clear preference for presenting reliability signals via non-numerical, color-coded indicators within the in-editor code generation workflow.
Themisto: Jupyter-Based Runtime Benchmark
Apr 16, 2025In this work, we present a benchmark that consists of Jupyter notebooks development trajectories and allows measuring how large language models (LLMs) can leverage runtime information for predicting code output and code generation. We demonstrate that the current generation of LLMs performs poorly on these tasks and argue that there exists a significantly understudied domain in the development of code-based models, which involves incorporating the runtime context.
Drawing Pandas: A Benchmark for LLMs in Generating Plotting Code
Dec 03, 2024This paper introduces the human-curated PandasPlotBench dataset, designed to evaluate language models' effectiveness as assistants in visual data exploration. Our benchmark focuses on generating code for visualizing tabular data - such as a Pandas DataFrame - based on natural language instructions, complementing current evaluation tools and expanding their scope. The dataset includes 175 unique tasks. Our experiments assess several leading Large Language Models (LLMs) across three visualization libraries: Matplotlib, Seaborn, and Plotly. We show that the shortening of tasks has a minimal effect on plotting capabilities, allowing for the user interface that accommodates concise user input without sacrificing functionality or accuracy. Another of our findings reveals that while LLMs perform well with popular libraries like Matplotlib and Seaborn, challenges persist with Plotly, highlighting areas for improvement. We hope that the modular design of our benchmark will broaden the current studies on generating visualizations. Our benchmark is available online: https://huggingface.co/datasets/JetBrains-Research/plot_bench. The code for running the benchmark is also available: https://github.com/JetBrains-Research/PandasPlotBench.
Kotlin ML Pack: Technical Report
May 29, 2024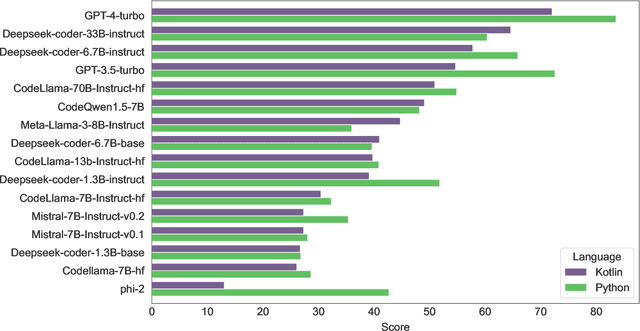
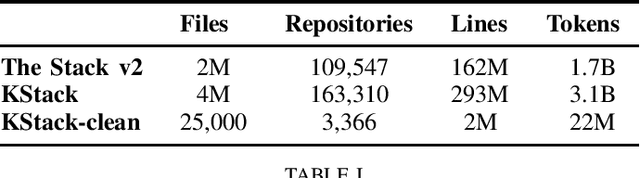
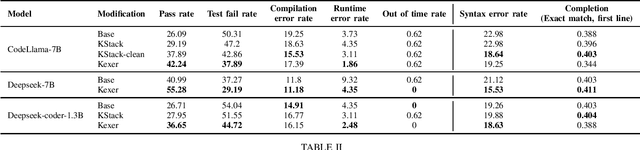
In this technical report, we present three novel datasets of Kotlin code: KStack, KStack-clean, and KExercises. We also describe the results of fine-tuning CodeLlama and DeepSeek models on this data. Additionally, we present a version of the HumanEval benchmark rewritten by human experts into Kotlin - both the solutions and the tests. Our results demonstrate that small, high-quality datasets (KStack-clean and KExercises) can significantly improve model performance on code generation tasks, achieving up to a 16-point increase in pass rate on the HumanEval benchmark. Lastly, we discuss potential future work in the field of improving language modeling for Kotlin, including the use of static analysis tools in the learning process and the introduction of more intricate and realistic benchmarks.