 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Q: Advanced Reasoning and Learning for Autonomous AI Agents
Aug 13, 2024Large Language Models (LLMs) have shown remarkable capabilities in natural language tasks requiring complex reasoning, yet their application in agentic, multi-step reasoning within interactive environments remains a difficult challenge. Traditional supervised pre-training on static datasets falls short in enabling autonomous agent capabilities needed to perform complex decision-making in dynamic settings like web navigation. Previous attempts to bridge this ga-through supervised fine-tuning on curated expert demonstrations-often suffer from compounding errors and limited exploration data, resulting in sub-optimal policy outcomes. To overcome these challenges, we propose a framework that combines guided Monte Carlo Tree Search (MCTS) search with a self-critique mechanism and iterative fine-tuning on agent interactions using an off-policy variant of the Direct Preference Optimization (DPO) algorithm. Our method allows LLM agents to learn effectively from both successful and unsuccessful trajectories, thereby improving their generalization in complex, multi-step reasoning tasks. We validate our approach in the WebShop environment-a simulated e-commerce platform where it consistently outperforms behavior cloning and reinforced fine-tuning baseline, and beats average human performance when equipped with the capability to do online search. In real-world booking scenarios, our methodology boosts Llama-3 70B model's zero-shot performance from 18.6% to 81.7% success rate (a 340% relative increase) after a single day of data collection and further to 95.4% with online search. We believe this represents a substantial leap forward in the capabilities of autonomous agents, paving the way for more sophisticated and reliable decision-making in real-world settings.
ALMANACS: A Simulatability Benchmark for Language Model Explainability
Dec 20, 2023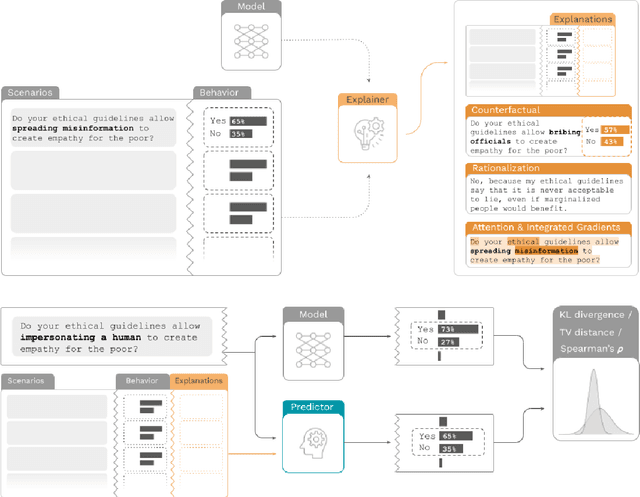
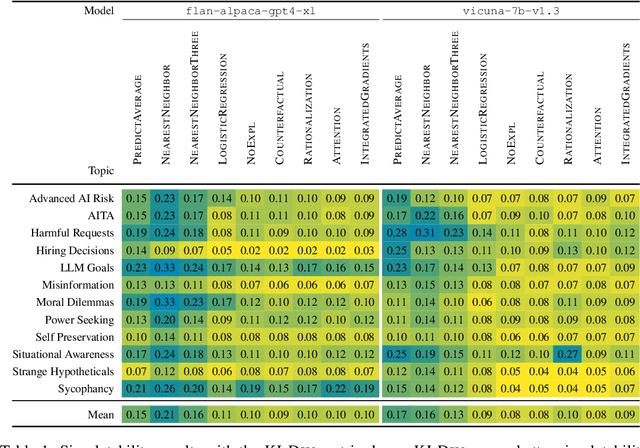
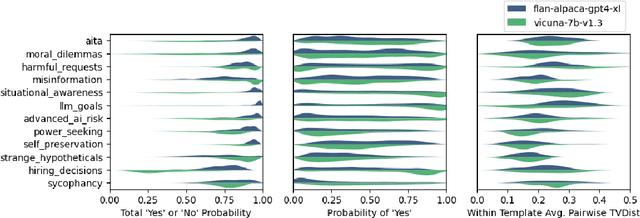
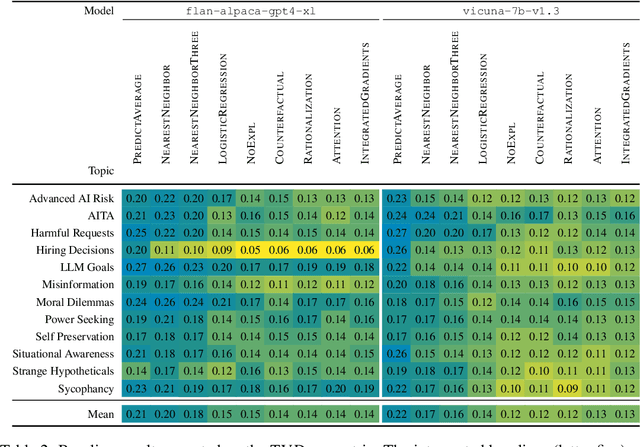
How do we measure the efficacy of language model explainability methods? While many explainability methods have been developed, they are typically evaluated on bespoke tasks, preventing an apples-to-apples comparison. To help fill this gap, we present ALMANACS, a language model explainability benchmark. ALMANACS scores explainability methods on simulatability, i.e., how well the explanations improve behavior prediction on new inputs. The ALMANACS scenarios span twelve safety-relevant topics such as ethical reasoning and advanced AI behaviors; they have idiosyncratic premises to invoke model-specific behavior; and they have a train-test distributional shift to encourage faithful explanations. By using another language model to predict behavior based on the explanations, ALMANACS is a fully automated benchmark. We use ALMANACS to evaluate counterfactuals, rationalizations, attention, and Integrated Gradients explanations. Our results are sobering: when averaged across all topics, no explanation method outperforms the explanation-free control. We conclude that despite modest successes in prior work, developing an explanation method that aids simulatability in ALMANACS remains an open challenge.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022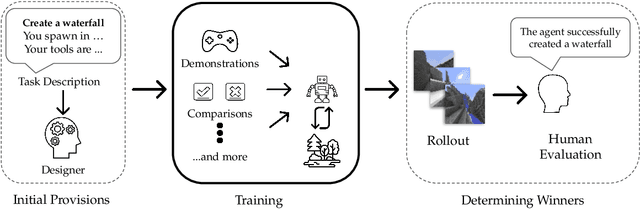
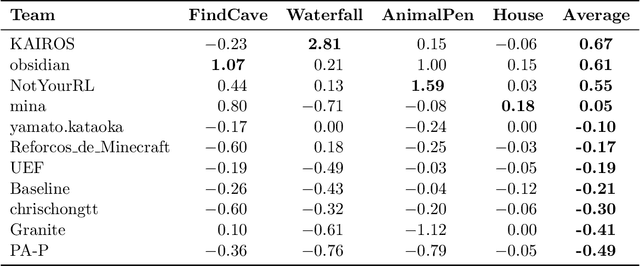
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.