 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAL: Benchmarking Autonomous Agents on Deterministic Simulations of Real Websites
Apr 15, 2025

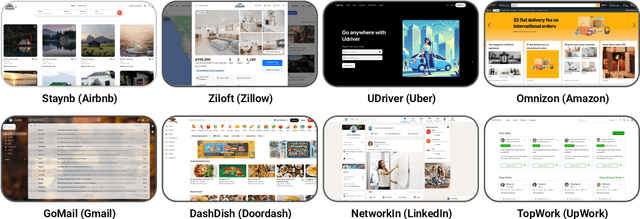

We introduce REAL, a benchmark and framework for multi-turn agent evaluations on deterministic simulations of real-world websites. REAL comprises high-fidelity, deterministic replicas of 11 widely-used websites across domains such as e-commerce, travel, communication, and professional networking. We also release a benchmark consisting of 112 practical tasks that mirror everyday complex user interactions requiring both accurate information retrieval and state-changing actions. All interactions occur within this fully controlled setting, eliminating safety risks and enabling robust, reproducible evaluation of agent capability and reliability. Our novel evaluation framework combines programmatic checks of website state for action-based tasks with rubric-guided LLM-based judgments for information retrieval. The framework supports both open-source and proprietary agent systems through a flexible evaluation harness that accommodates black-box commands within browser environments, allowing research labs to test agentic systems without modification. Our empirical results show that frontier language models achieve at most a 41% success rate on REAL, highlighting critical gaps in autonomous web navigation and task completion capabilities. Our framework supports easy integration of new tasks, reproducible evaluation, and scalable data generation for training web agents. The websites, framework, and leaderboard are available at https://realevals.xyz and https://github.com/agi-inc/REAL.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
Aug 13, 2024Large Language Models (LLMs) have shown remarkable capabilities in natural language tasks requiring complex reasoning, yet their application in agentic, multi-step reasoning within interactive environments remains a difficult challenge. Traditional supervised pre-training on static datasets falls short in enabling autonomous agent capabilities needed to perform complex decision-making in dynamic settings like web navigation. Previous attempts to bridge this ga-through supervised fine-tuning on curated expert demonstrations-often suffer from compounding errors and limited exploration data, resulting in sub-optimal policy outcomes. To overcome these challenges, we propose a framework that combines guided Monte Carlo Tree Search (MCTS) search with a self-critique mechanism and iterative fine-tuning on agent interactions using an off-policy variant of the Direct Preference Optimization (DPO) algorithm. Our method allows LLM agents to learn effectively from both successful and unsuccessful trajectories, thereby improving their generalization in complex, multi-step reasoning tasks. We validate our approach in the WebShop environment-a simulated e-commerce platform where it consistently outperforms behavior cloning and reinforced fine-tuning baseline, and beats average human performance when equipped with the capability to do online search. In real-world booking scenarios, our methodology boosts Llama-3 70B model's zero-shot performance from 18.6% to 81.7% success rate (a 340% relative increase) after a single day of data collection and further to 95.4% with online search. We believe this represents a substantial leap forward in the capabilities of autonomous agents, paving the way for more sophisticated and reliable decision-making in real-world settings.