 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALMANACS: A Simulatability Benchmark for Language Model Explainability
Paper and Code
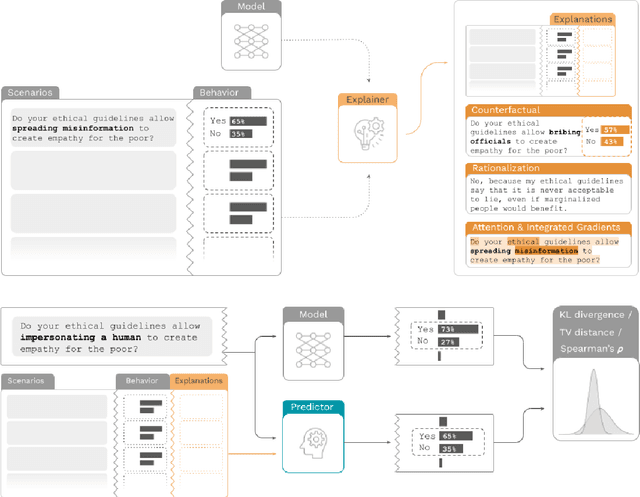
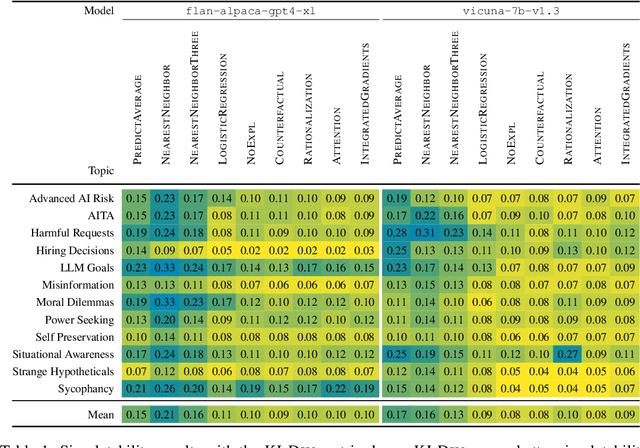
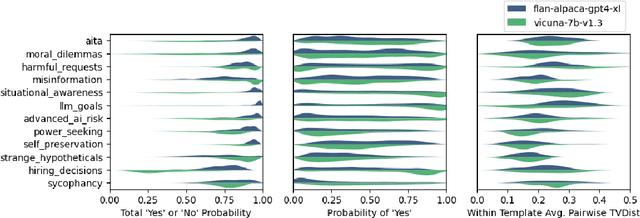
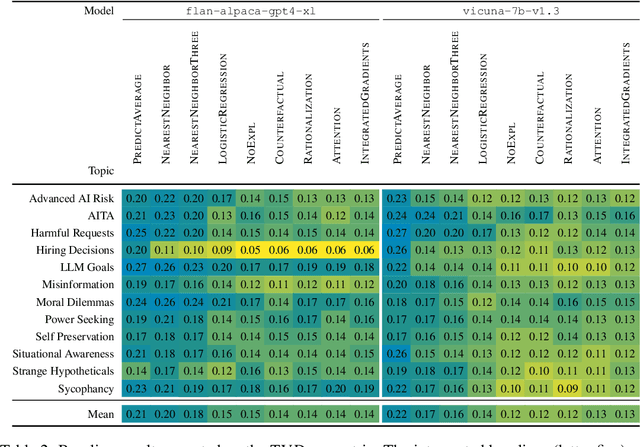
How do we measure the efficacy of language model explainability methods? While many explainability methods have been developed, they are typically evaluated on bespoke tasks, preventing an apples-to-apples comparison. To help fill this gap, we present ALMANACS, a language model explainability benchmark. ALMANACS scores explainability methods on simulatability, i.e., how well the explanations improve behavior prediction on new inputs. The ALMANACS scenarios span twelve safety-relevant topics such as ethical reasoning and advanced AI behaviors; they have idiosyncratic premises to invoke model-specific behavior; and they have a train-test distributional shift to encourage faithful explanations. By using another language model to predict behavior based on the explanations, ALMANACS is a fully automated benchmark. We use ALMANACS to evaluate counterfactuals, rationalizations, attention, and Integrated Gradients explanations. Our results are sobering: when averaged across all topics, no explanation method outperforms the explanation-free control. We conclude that despite modest successes in prior work, developing an explanation method that aids simulatability in ALMANACS remains an open challenge.