 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Explaining Hypergraph Neural Networks: From Local Explanations to Global Concepts
Oct 10, 2024

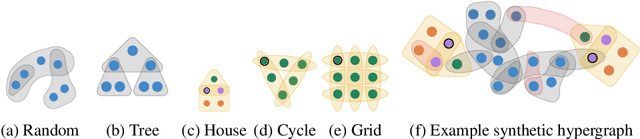

Hypergraph neural networks are a class of powerful models that leverage the message passing paradigm to learn over hypergraphs, a generalization of graphs well-suited to describing relational data with higher-order interactions. However, such models are not naturally interpretable, and their explainability has received very limited attention. We introduce SHypX, the first model-agnostic post-hoc explainer for hypergraph neural networks that provides both local and global explanations. At the instance-level, it performs input attribution by discretely sampling explanation subhypergraphs optimized to be faithful and concise. At the model-level, it produces global explanation subhypergraphs using unsupervised concept extraction. Extensive experiments across four real-world and four novel, synthetic hypergraph datasets demonstrate that our method finds high-quality explanations which can target a user-specified balance between faithfulness and concision, improving over baselines by 25 percent points in fidelity on average.
Commute-Time-Optimised Graphs for GNNs
Jul 09, 2024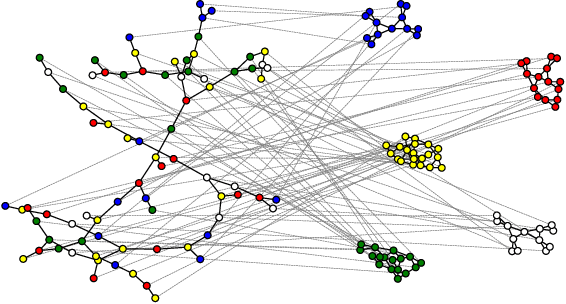
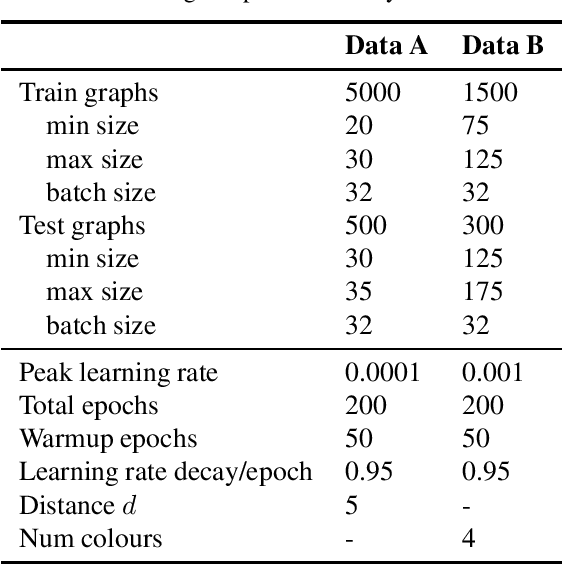
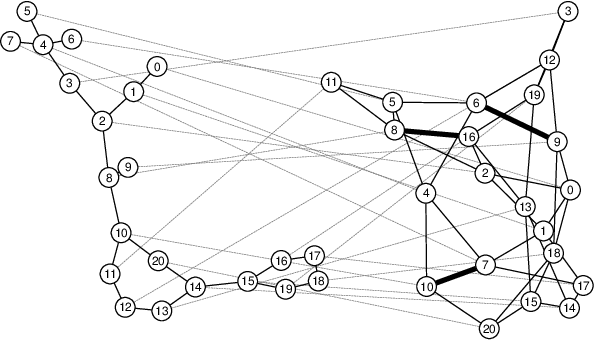

We explore graph rewiring methods that optimise commute time. Recent graph rewiring approaches facilitate long-range interactions in sparse graphs, making such rewirings commute-time-optimal $\textit{on average}$. However, when an expert prior exists on which node pairs should or should not interact, a superior rewiring would favour short commute times between these privileged node pairs. We construct two synthetic datasets with known priors reflecting realistic settings, and use these to motivate two bespoke rewiring methods that incorporate the known prior. We investigate the regimes where our rewiring improves test performance on the synthetic datasets. Finally, we perform a case study on a real-world citation graph to investigate the practical implications of our work.
ALMANACS: A Simulatability Benchmark for Language Model Explainability
Dec 20, 2023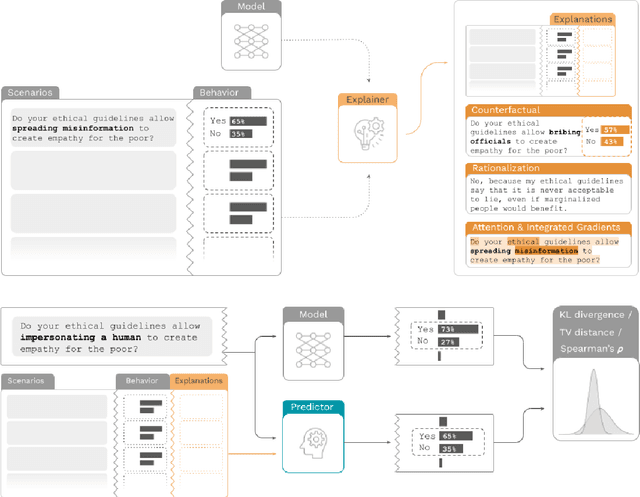
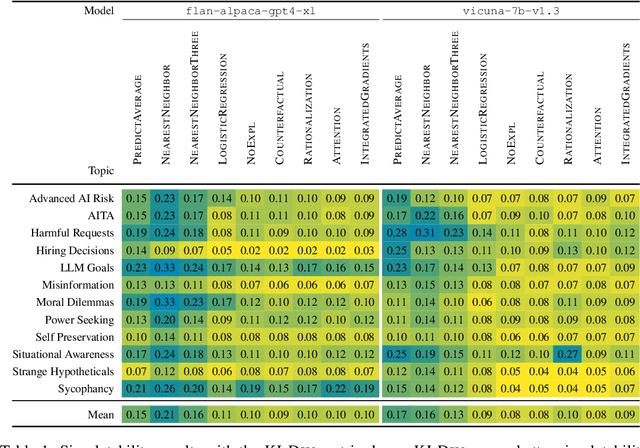
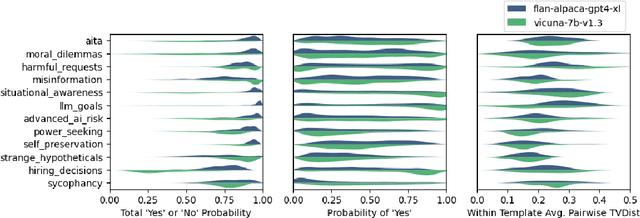
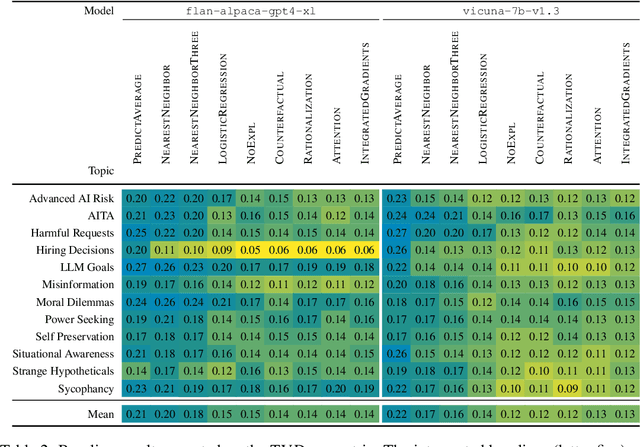
How do we measure the efficacy of language model explainability methods? While many explainability methods have been developed, they are typically evaluated on bespoke tasks, preventing an apples-to-apples comparison. To help fill this gap, we present ALMANACS, a language model explainability benchmark. ALMANACS scores explainability methods on simulatability, i.e., how well the explanations improve behavior prediction on new inputs. The ALMANACS scenarios span twelve safety-relevant topics such as ethical reasoning and advanced AI behaviors; they have idiosyncratic premises to invoke model-specific behavior; and they have a train-test distributional shift to encourage faithful explanations. By using another language model to predict behavior based on the explanations, ALMANACS is a fully automated benchmark. We use ALMANACS to evaluate counterfactuals, rationalizations, attention, and Integrated Gradients explanations. Our results are sobering: when averaged across all topics, no explanation method outperforms the explanation-free control. We conclude that despite modest successes in prior work, developing an explanation method that aids simulatability in ALMANACS remains an open challenge.