 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple View Performers for Shape Completion
Sep 13, 2022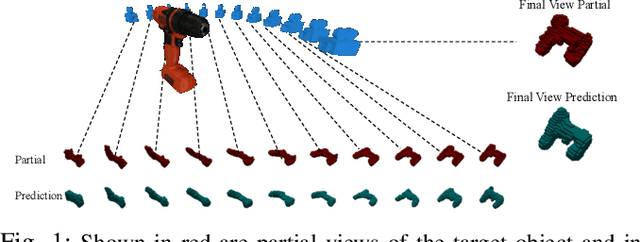
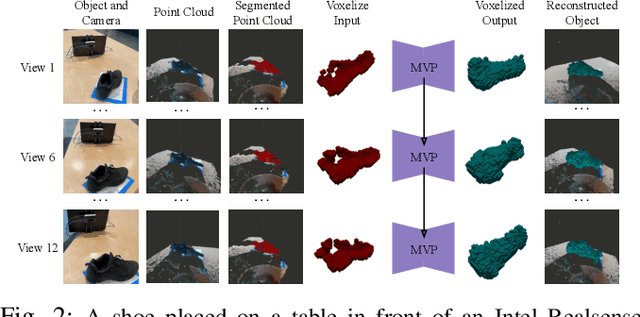
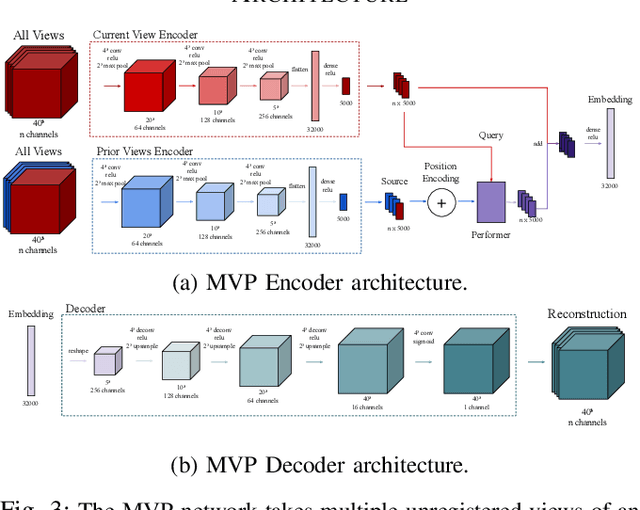
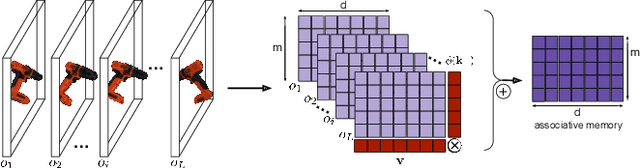
We propose the Multiple View Performer (MVP) - a new architecture for 3D shape completion from a series of temporally sequential views. MVP accomplishes this task by using linear-attention Transformers called Performers. Our model allows the current observation of the scene to attend to the previous ones for more accurate infilling. The history of past observations is compressed via the compact associative memory approximating modern continuous Hopfield memory, but crucially of size independent from the history length. We compare our model with several baselines for shape completion over time, demonstrating the generalization gains that MVP provides. To the best of our knowledge, MVP is the first multiple view voxel reconstruction method that does not require registration of multiple depth views and the first causal Transformer based model for 3D shape completion.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022
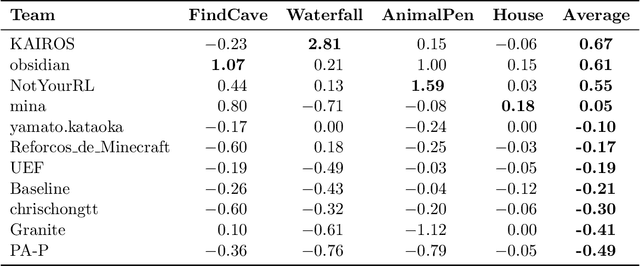
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.
Mobile Manipulation Leveraging Multiple Views
Oct 02, 2021
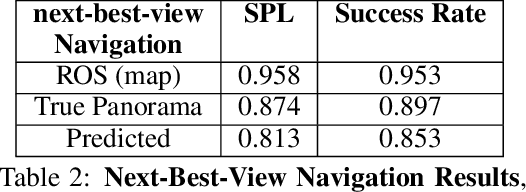

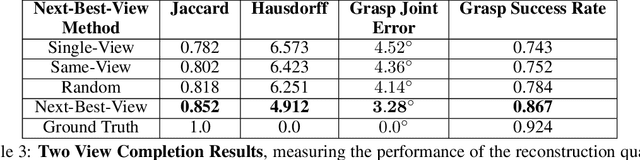
While both navigation and manipulation are challenging topics in isolation, many tasks require the ability to both navigate and manipulate in concert. To this end, we propose a mobile manipulation system that leverages novel navigation and shape completion methods to manipulate an object with a mobile robot. Our system utilizes uncertainty in the initial estimation of a manipulation target to calculate a predicted next-best-view. Without the need of localization, the robot then uses the predicted panoramic view at the next-best-view location to navigate to the desired location, capture a second view of the object, create a new model that predicts the shape of object more accurately than a single image alone, and uses this model for grasp planning. We show that the system is highly effective for mobile manipulation tasks through simulation experiments using real world data, as well as ablations on each component of our system.
Accelerated Robot Learning via Human Brain Signals
Oct 01, 2019
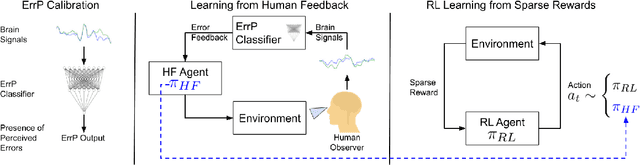
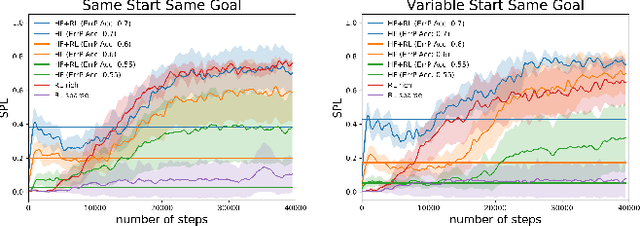

In reinforcement learning (RL), sparse rewards are a natural way to specify the task to be learned. However, most RL algorithms struggle to learn in this setting since the learning signal is mostly zeros. In contrast, humans are good at assessing and predicting the future consequences of actions and can serve as good reward/policy shapers to accelerate the robot learning process. Previous works have shown that the human brain generates an error-related signal, measurable using electroencephelography (EEG), when the human perceives the task being done erroneously. In this work, we propose a method that uses evaluative feedback obtained from human brain signals measured via scalp EEG to accelerate RL for robotic agents in sparse reward settings. As the robot learns the task, the EEG of a human observer watching the robot attempts is recorded and decoded into noisy error feedback signal. From this feedback, we use supervised learning to obtain a policy that subsequently augments the behavior policy and guides exploration in the early stages of RL. This bootstraps the RL learning process to enable learning from sparse reward. Using a robotic navigation task as a test bed, we show that our method achieves a stable obstacle-avoidance policy with high success rate, outperforming learning from sparse rewards only that struggles to achieve obstacle avoidance behavior or fails to advance to the goal.
Learning Your Way Without Map or Compass: Panoramic Target Driven Visual Navigation
Sep 20, 2019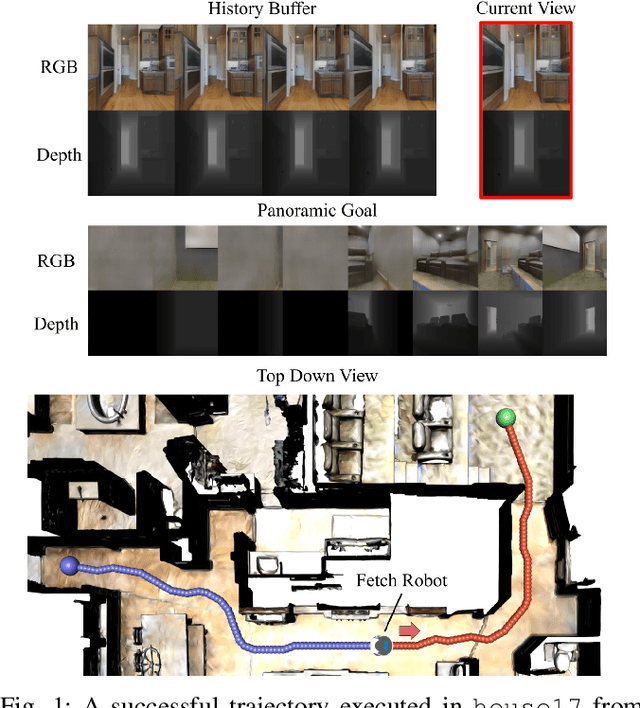
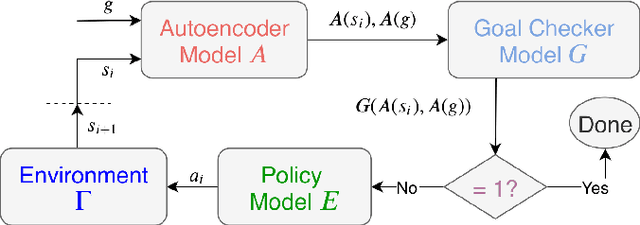

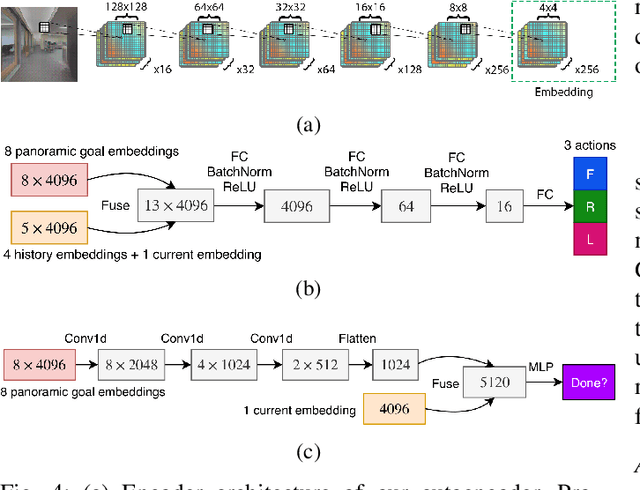
We present a robot navigation system that uses an imitation learning framework to successfully navigate in complex environments. Our framework takes a pre-built 3D scan of a real environment and trains an agent from pre-generated expert trajectories to navigate to any position given a panoramic view of the goal and the current visual input without relying on map, compass, odometry, GPS or relative position of the target at runtime. Our end-to-end trained agent uses RGB and depth (RGBD) information and can handle large environments (up to $1031m^2$) across multiple rooms (up to $40$) and generalizes to unseen targets. We show that when compared to several baselines using deep reinforcement learning and RGBD SLAM, our method (1) requires fewer training examples and less training time, (2) reaches the goal location with higher accuracy, (3) produces better solutions with shorter paths for long-range navigation tasks, and (4) generalizes to unseen environments given an RGBD map of the environment.
Multi-Modal Geometric Learning for Grasping and Manipulation
Feb 27, 2019
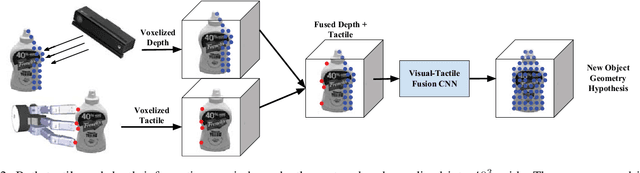
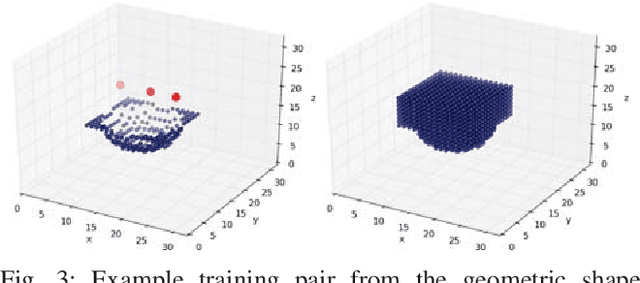

This work provides an architecture that incorporates depth and tactile information to create rich and accurate 3D models useful for robotic manipulation tasks. This is accomplished through the use of a 3D convolutional neural network (CNN). Offline, the network is provided with both depth and tactile information and trained to predict the object's geometry, thus filling in regions of occlusion. At runtime, the network is provided a partial view of an object. Tactile information is acquired to augment the captured depth information. The network can then reason about the object's geometry by utilizing both the collected tactile and depth information. We demonstrate that even small amounts of additional tactile information can be incredibly helpful in reasoning about object geometry. This is particularly true when information from depth alone fails to produce an accurate geometric prediction. Our method is benchmarked against and outperforms other visual-tactile approaches to general geometric reasoning. We also provide experimental results comparing grasping success with our method.
Human Robot Interface for Assistive Grasping
Apr 06, 2018
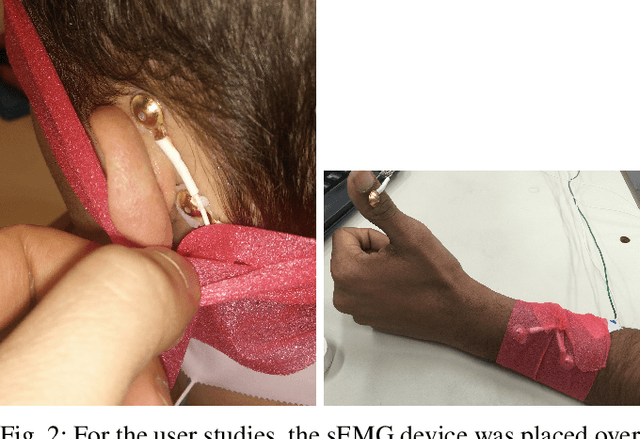

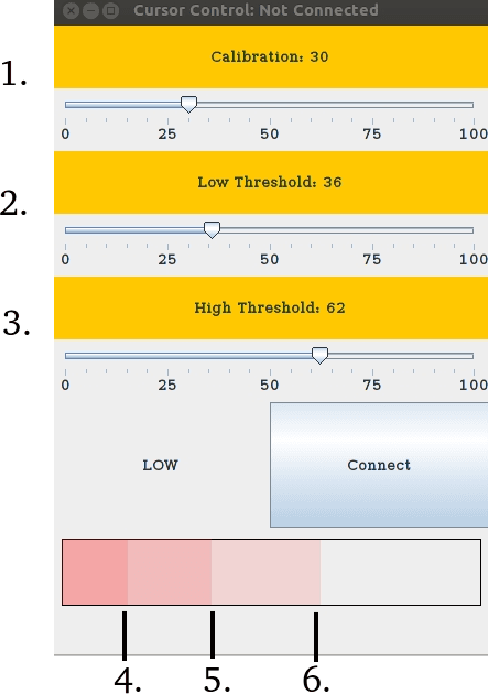
This work describes a new human-in-the-loop (HitL) assistive grasping system for individuals with varying levels of physical capabilities. We investigated the feasibility of using four potential input devices with our assistive grasping system interface, using able-bodied individuals to define a set of quantitative metrics that could be used to assess an assistive grasping system. We then took these measurements and created a generalized benchmark for evaluating the effectiveness of any arbitrary input device into a HitL grasping system. The four input devices were a mouse, a speech recognition device, an assistive switch, and a novel sEMG device developed by our group that was connected either to the forearm or behind the ear of the subject. These preliminary results provide insight into how different interface devices perform for generalized assistive grasping tasks and also highlight the potential of sEMG based control for severely disabled individuals.