 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Geometric Learning for Grasping and Manipulation
Paper and Code

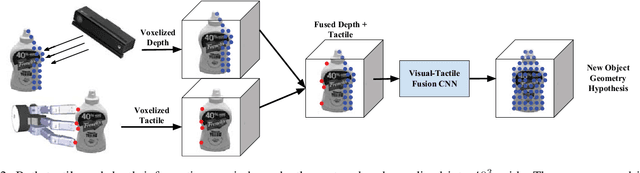
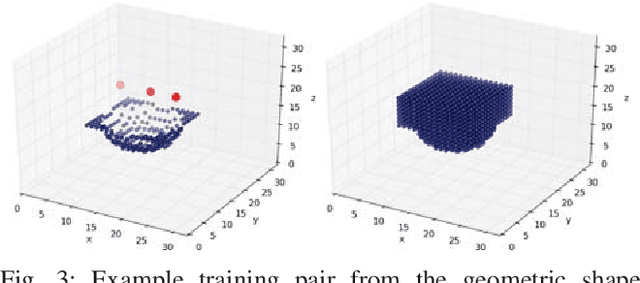

This work provides an architecture that incorporates depth and tactile information to create rich and accurate 3D models useful for robotic manipulation tasks. This is accomplished through the use of a 3D convolutional neural network (CNN). Offline, the network is provided with both depth and tactile information and trained to predict the object's geometry, thus filling in regions of occlusion. At runtime, the network is provided a partial view of an object. Tactile information is acquired to augment the captured depth information. The network can then reason about the object's geometry by utilizing both the collected tactile and depth information. We demonstrate that even small amounts of additional tactile information can be incredibly helpful in reasoning about object geometry. This is particularly true when information from depth alone fails to produce an accurate geometric prediction. Our method is benchmarked against and outperforms other visual-tactile approaches to general geometric reasoning. We also provide experimental results comparing grasping success with our method.