 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the Real World with High-Density Visual Particle Dynamics
Jun 28, 2024



We present High-Density Visual Particle Dynamics (HD-VPD), a learned world model that can emulate the physical dynamics of real scenes by processing massive latent point clouds containing 100K+ particles. To enable efficiency at this scale, we introduce a novel family of Point Cloud Transformers (PCTs) called Interlacers leveraging intertwined linear-attention Performer layers and graph-based neighbour attention layers. We demonstrate the capabilities of HD-VPD by modeling the dynamics of high degree-of-freedom bi-manual robots with two RGB-D cameras. Compared to the previous graph neural network approach, our Interlacer dynamics is twice as fast with the same prediction quality, and can achieve higher quality using 4x as many particles. We illustrate how HD-VPD can evaluate motion plan quality with robotic box pushing and can grasping tasks. See videos and particle dynamics rendered by HD-VPD at https://sites.google.com/view/hd-vpd.
Multiple View Performers for Shape Completion
Sep 13, 2022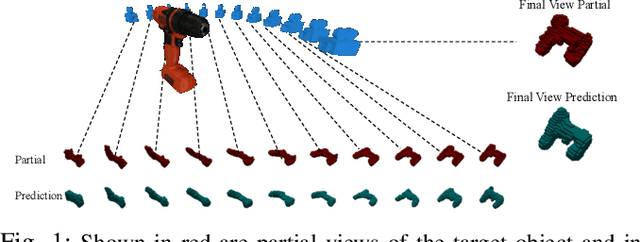
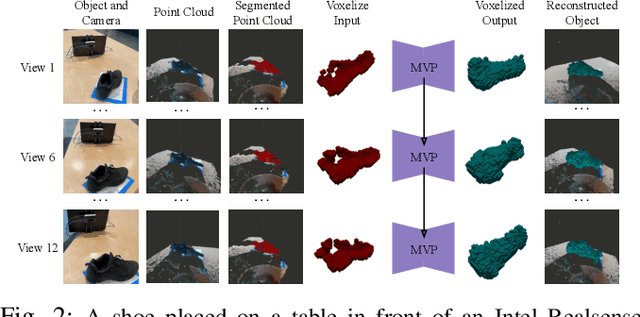
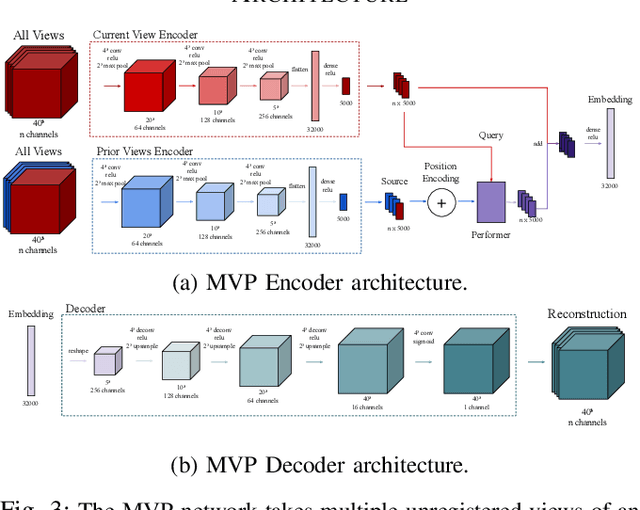
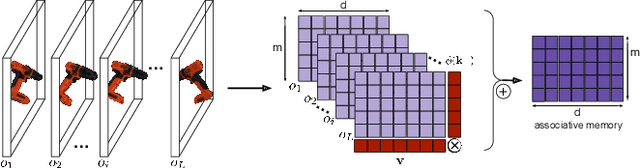
We propose the Multiple View Performer (MVP) - a new architecture for 3D shape completion from a series of temporally sequential views. MVP accomplishes this task by using linear-attention Transformers called Performers. Our model allows the current observation of the scene to attend to the previous ones for more accurate infilling. The history of past observations is compressed via the compact associative memory approximating modern continuous Hopfield memory, but crucially of size independent from the history length. We compare our model with several baselines for shape completion over time, demonstrating the generalization gains that MVP provides. To the best of our knowledge, MVP is the first multiple view voxel reconstruction method that does not require registration of multiple depth views and the first causal Transformer based model for 3D shape completion.
Multiscale Sensor Fusion and Continuous Control with Neural CDEs
Mar 16, 2022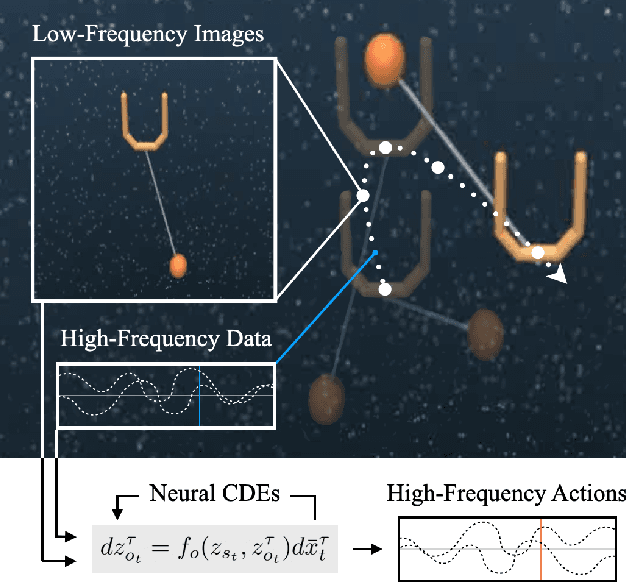
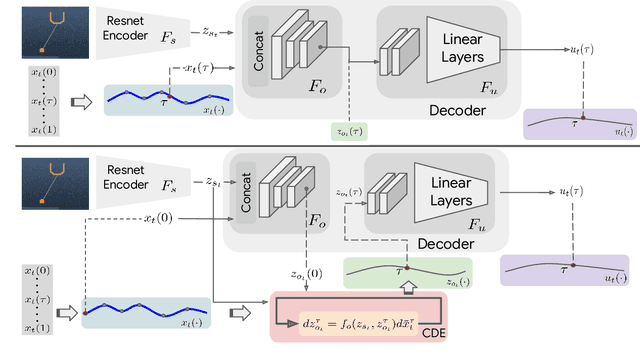
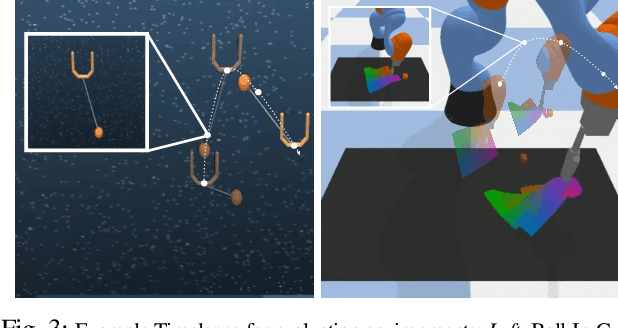
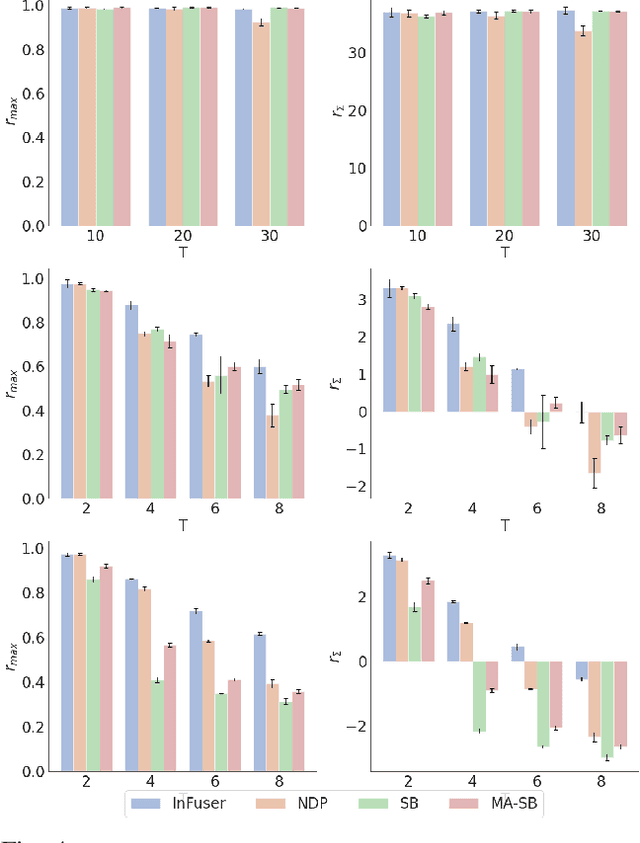
Though robot learning is often formulated in terms of discrete-time Markov decision processes (MDPs), physical robots require near-continuous multiscale feedback control. Machines operate on multiple asynchronous sensing modalities, each with different frequencies, e.g., video frames at 30Hz, proprioceptive state at 100Hz, force-torque data at 500Hz, etc. While the classic approach is to batch observations into fixed-time windows then pass them through feed-forward encoders (e.g., with deep networks), we show that there exists a more elegant approach -- one that treats policy learning as modeling latent state dynamics in continuous-time. Specifically, we present 'InFuser', a unified architecture that trains continuous time-policies with Neural Controlled Differential Equations (CDEs). InFuser evolves a single latent state representation over time by (In)tegrating and (Fus)ing multi-sensory observations (arriving at different frequencies), and inferring actions in continuous-time. This enables policies that can react to multi-frequency multi sensory feedback for truly end-to-end visuomotor control, without discrete-time assumptions. Behavior cloning experiments demonstrate that InFuser learns robust policies for dynamic tasks (e.g., swinging a ball into a cup) notably outperforming several baselines in settings where observations from one sensing modality can arrive at much sparser intervals than others.
Mobile Manipulation Leveraging Multiple Views
Oct 02, 2021
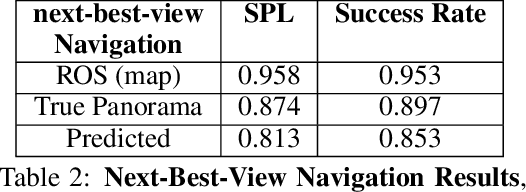

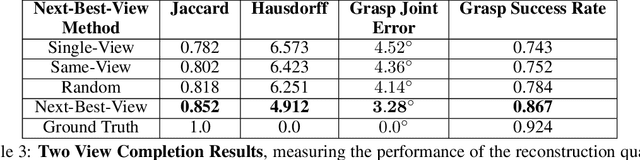
While both navigation and manipulation are challenging topics in isolation, many tasks require the ability to both navigate and manipulate in concert. To this end, we propose a mobile manipulation system that leverages novel navigation and shape completion methods to manipulate an object with a mobile robot. Our system utilizes uncertainty in the initial estimation of a manipulation target to calculate a predicted next-best-view. Without the need of localization, the robot then uses the predicted panoramic view at the next-best-view location to navigate to the desired location, capture a second view of the object, create a new model that predicts the shape of object more accurately than a single image alone, and uses this model for grasp planning. We show that the system is highly effective for mobile manipulation tasks through simulation experiments using real world data, as well as ablations on each component of our system.
MT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale
Apr 27, 2021
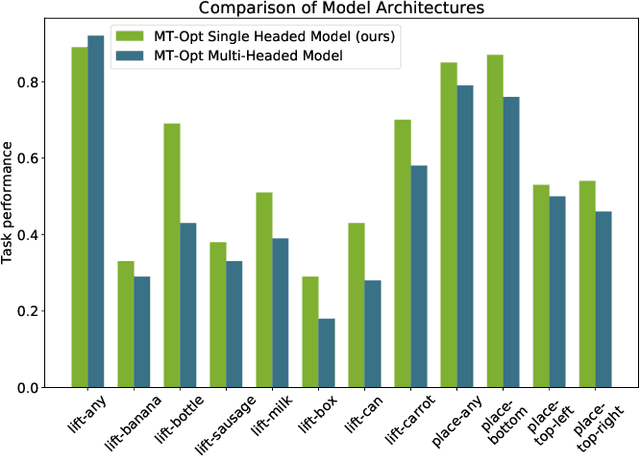
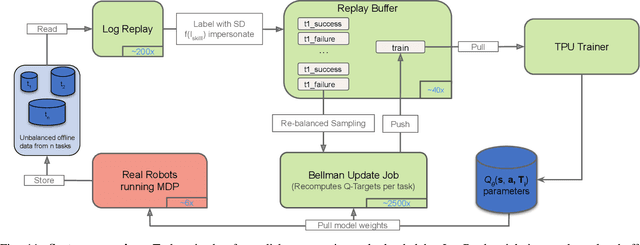
General-purpose robotic systems must master a large repertoire of diverse skills to be useful in a range of daily tasks. While reinforcement learning provides a powerful framework for acquiring individual behaviors, the time needed to acquire each skill makes the prospect of a generalist robot trained with RL daunting. In this paper, we study how a large-scale collective robotic learning system can acquire a repertoire of behaviors simultaneously, sharing exploration, experience, and representations across tasks. In this framework new tasks can be continuously instantiated from previously learned tasks improving overall performance and capabilities of the system. To instantiate this system, we develop a scalable and intuitive framework for specifying new tasks through user-provided examples of desired outcomes, devise a multi-robot collective learning system for data collection that simultaneously collects experience for multiple tasks, and develop a scalable and generalizable multi-task deep reinforcement learning method, which we call MT-Opt. We demonstrate how MT-Opt can learn a wide range of skills, including semantic picking (i.e., picking an object from a particular category), placing into various fixtures (e.g., placing a food item onto a plate), covering, aligning, and rearranging. We train and evaluate our system on a set of 12 real-world tasks with data collected from 7 robots, and demonstrate the performance of our system both in terms of its ability to generalize to structurally similar new tasks, and acquire distinct new tasks more quickly by leveraging past experience. We recommend viewing the videos at https://karolhausman.github.io/mt-opt/
Visionary: Vision architecture discovery for robot learning
Mar 26, 2021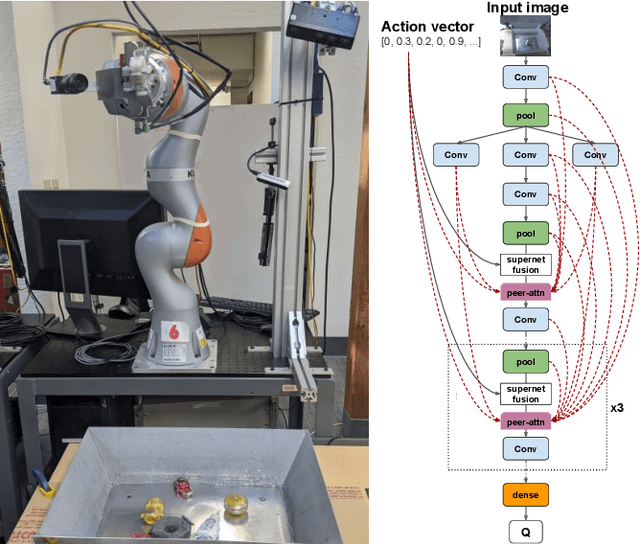
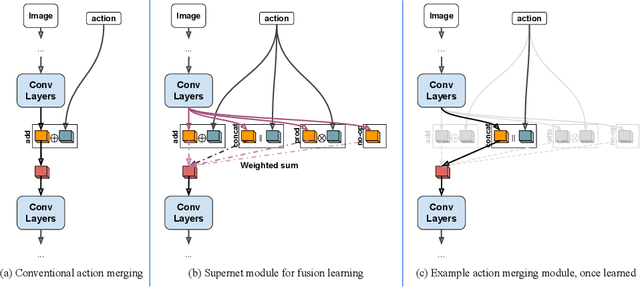
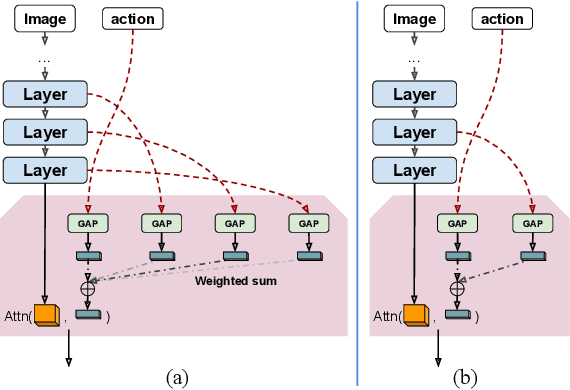

We propose a vision-based architecture search algorithm for robot manipulation learning, which discovers interactions between low dimension action inputs and high dimensional visual inputs. Our approach automatically designs architectures while training on the task - discovering novel ways of combining and attending image feature representations with actions as well as features from previous layers. The obtained new architectures demonstrate better task success rates, in some cases with a large margin, compared to a recent high performing baseline. Our real robot experiments also confirm that it improves grasping performance by 6%. This is the first approach to demonstrate a successful neural architecture search and attention connectivity search for a real-robot task.
Disentangled Planning and Control in Vision Based Robotics via Reward Machines
Dec 28, 2020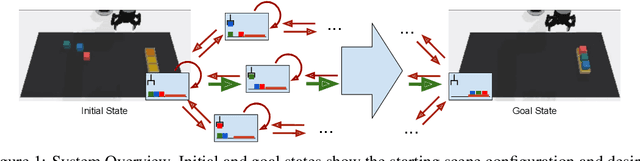
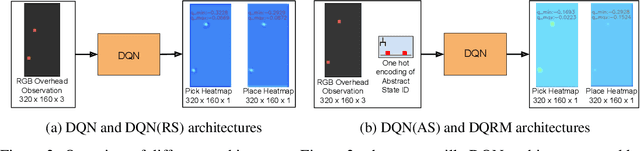
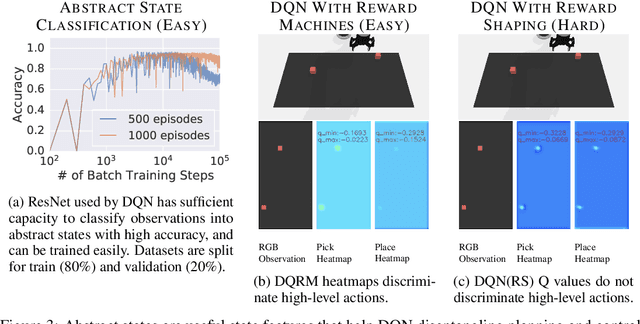
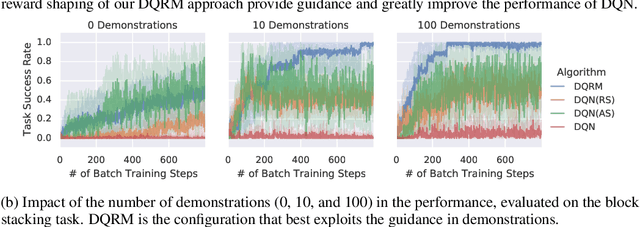
In this work we augment a Deep Q-Learning agent with a Reward Machine (DQRM) to increase speed of learning vision-based policies for robot tasks, and overcome some of the limitations of DQN that prevent it from converging to good-quality policies. A reward machine (RM) is a finite state machine that decomposes a task into a discrete planning graph and equips the agent with a reward function to guide it toward task completion. The reward machine can be used for both reward shaping, and informing the policy what abstract state it is currently at. An abstract state is a high level simplification of the current state, defined in terms of task relevant features. These two supervisory signals of reward shaping and knowledge of current abstract state coming from the reward machine complement each other and can both be used to improve policy performance as demonstrated on several vision based robotic pick and place tasks. Particularly for vision based robotics applications, it is often easier to build a reward machine than to try and get a policy to learn the task without this structure.
An Ode to an ODE
Jun 23, 2020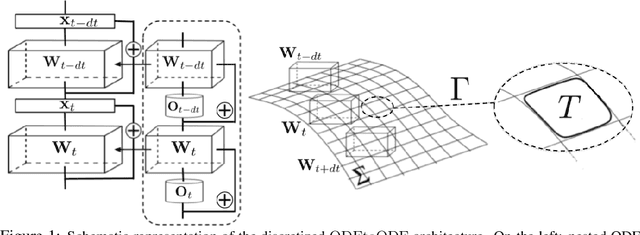

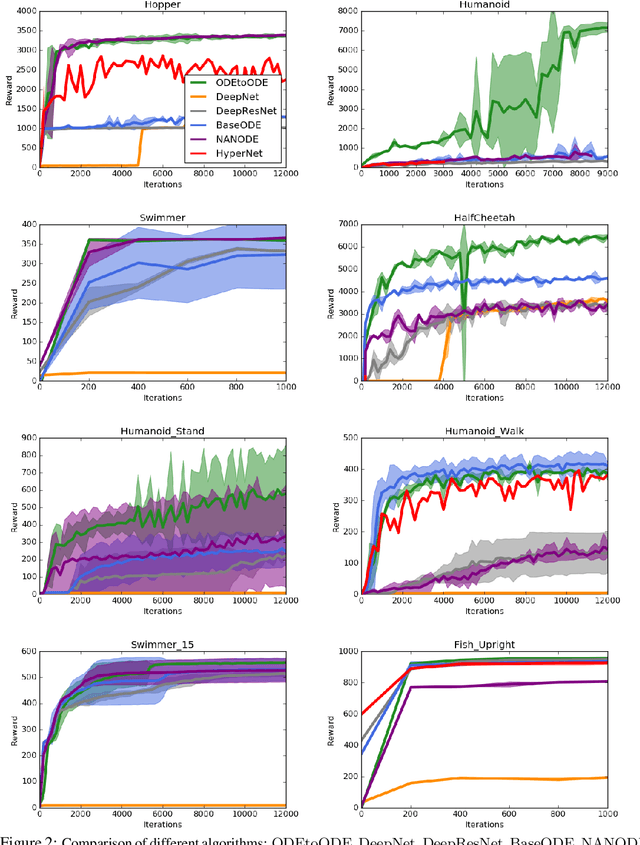
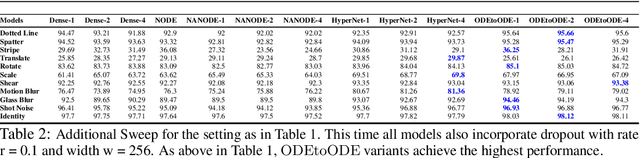
We present a new paradigm for Neural ODE algorithms, called ODEtoODE, where time-dependent parameters of the main flow evolve according to a matrix flow on the orthogonal group O(d). This nested system of two flows, where the parameter-flow is constrained to lie on the compact manifold, provides stability and effectiveness of training and provably solves the gradient vanishing-explosion problem which is intrinsically related to training deep neural network architectures such as Neural ODEs. Consequently, it leads to better downstream models, as we show on the example of training reinforcement learning policies with evolution strategies, and in the supervised learning setting, by comparing with previous SOTA baselines. We provide strong convergence results for our proposed mechanism that are independent of the depth of the network, supporting our empirical studies. Our results show an intriguing connection between the theory of deep neural networks and the field of matrix flows on compact manifolds.
Learning Precise 3D Manipulation from Multiple Uncalibrated Cameras
Feb 21, 2020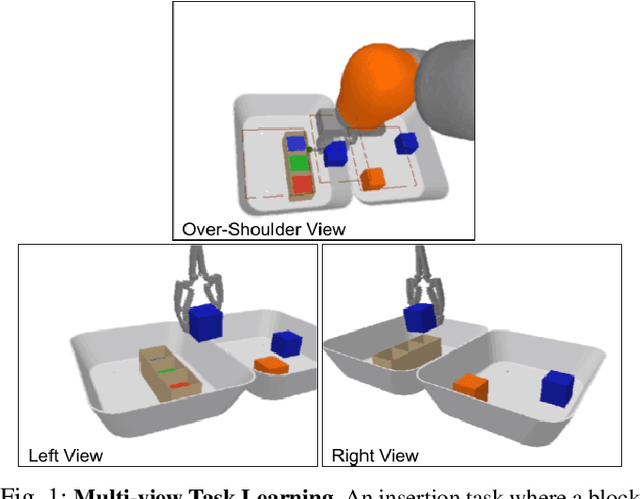
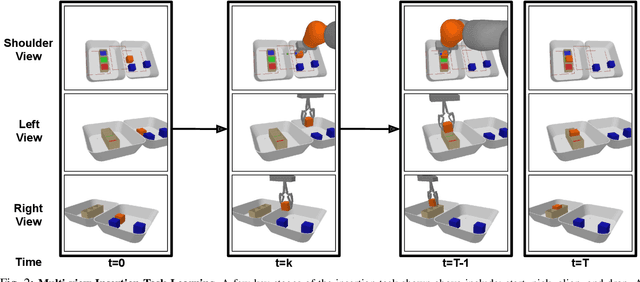
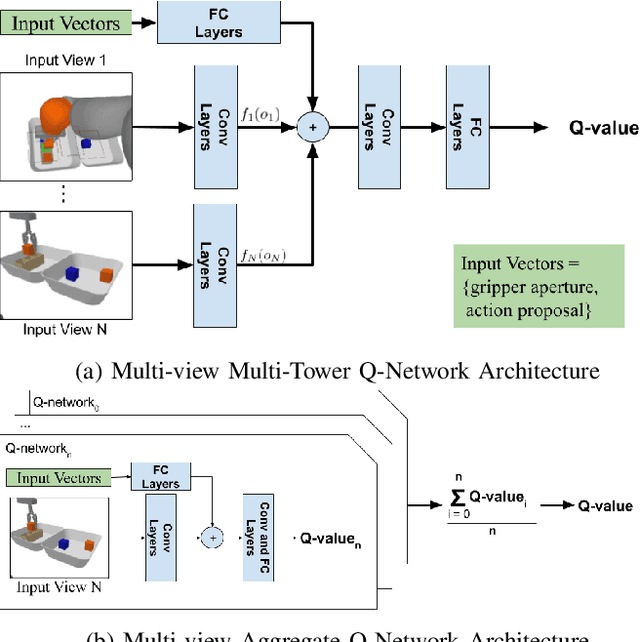
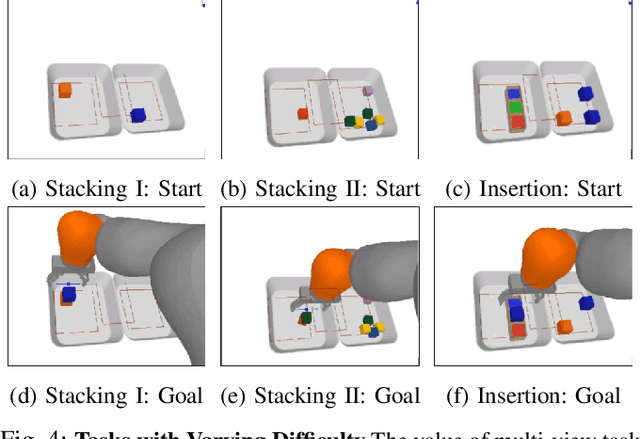
In this work, we present an effective multi-view approach to closed-loop end-to-end learning of precise manipulation tasks that are 3D in nature. Our method learns to accomplish these tasks using multiple statically placed but uncalibrated RGB camera views without building an explicit 3D representation such as a pointcloud or voxel grid. This multi-camera approach achieves superior task performance on difficult stacking and insertion tasks compared to single-view baselines. Single view robotic agents struggle from occlusion and challenges in estimating relative poses between points of interest. While full 3D scene representations (voxels or pointclouds) are obtainable from registered output of multiple depth sensors, several challenges complicate operating off such explicit 3D representations. These challenges include imperfect camera calibration, poor depth maps due to object properties such as reflective surfaces, and slower inference speeds over 3D representations compared to 2D images. Our use of static but uncalibrated cameras does not require camera-robot or camera-camera calibration making the proposed approach easy to setup and our use of \textit{sensor dropout} during training makes it resilient to the loss of camera-views after deployment.
MAT: Multi-Fingered Adaptive Tactile Grasping via Deep Reinforcement Learning
Oct 10, 2019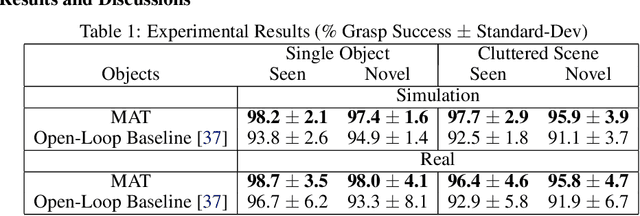

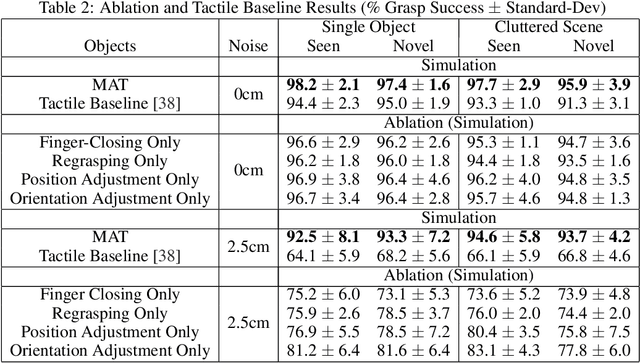

Vision-based grasping systems typically adopt an open-loop execution of a planned grasp. This policy can fail due to many reasons, including ubiquitous calibration error. Recovery from a failed grasp is further complicated by visual occlusion, as the hand is usually occluding the vision sensor as it attempts another open-loop regrasp. This work presents MAT, a tactile closed-loop method capable of realizing grasps provided by a coarse initial positioning of the hand above an object. Our algorithm is a deep reinforcement learning (RL) policy optimized through the clipped surrogate objective within a maximum entropy RL framework to balance exploitation and exploration. The method utilizes tactile and proprioceptive information to act through both fine finger motions and larger regrasp movements to execute stable grasps. A novel curriculum of action motion magnitude makes learning more tractable and helps turn common failure cases into successes. Careful selection of features that exhibit small sim-to-real gaps enables this tactile grasping policy, trained purely in simulation, to transfer well to real world environments without the need for additional learning. Experimentally, this methodology improves over a vision-only grasp success rate substantially on a multi-fingered robot hand. When this methodology is used to realize grasps from coarse initial positions provided by a vision-only planner, the system is made dramatically more robust to calibration errors in the camera-robot transform.