 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale
Apr 27, 2021
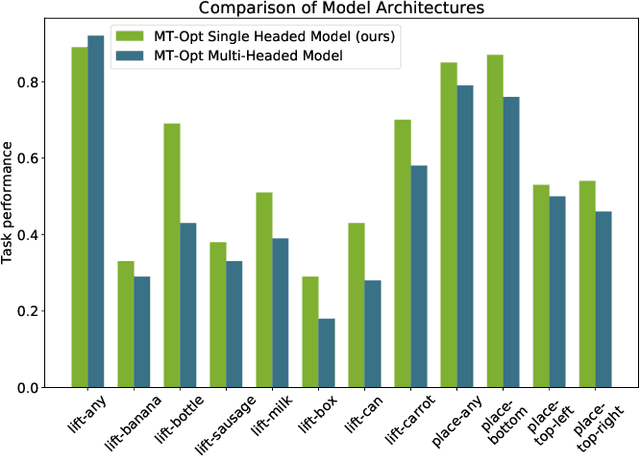
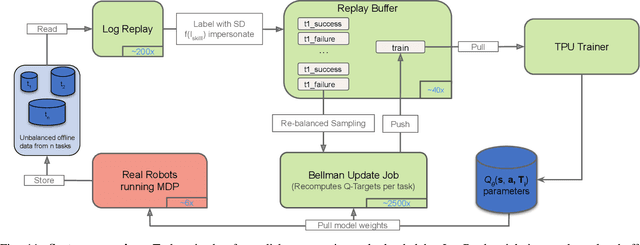
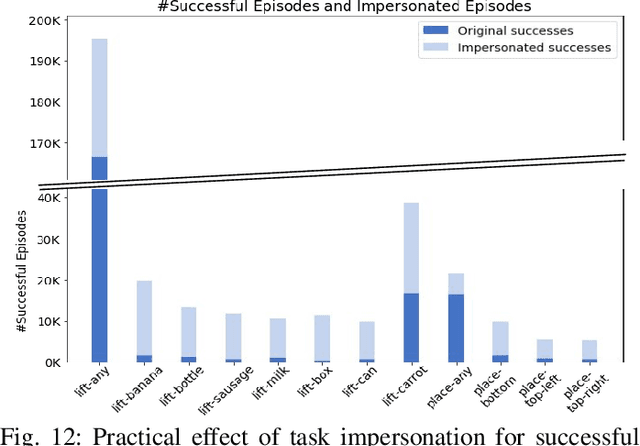
General-purpose robotic systems must master a large repertoire of diverse skills to be useful in a range of daily tasks. While reinforcement learning provides a powerful framework for acquiring individual behaviors, the time needed to acquire each skill makes the prospect of a generalist robot trained with RL daunting. In this paper, we study how a large-scale collective robotic learning system can acquire a repertoire of behaviors simultaneously, sharing exploration, experience, and representations across tasks. In this framework new tasks can be continuously instantiated from previously learned tasks improving overall performance and capabilities of the system. To instantiate this system, we develop a scalable and intuitive framework for specifying new tasks through user-provided examples of desired outcomes, devise a multi-robot collective learning system for data collection that simultaneously collects experience for multiple tasks, and develop a scalable and generalizable multi-task deep reinforcement learning method, which we call MT-Opt. We demonstrate how MT-Opt can learn a wide range of skills, including semantic picking (i.e., picking an object from a particular category), placing into various fixtures (e.g., placing a food item onto a plate), covering, aligning, and rearranging. We train and evaluate our system on a set of 12 real-world tasks with data collected from 7 robots, and demonstrate the performance of our system both in terms of its ability to generalize to structurally similar new tasks, and acquire distinct new tasks more quickly by leveraging past experience. We recommend viewing the videos at https://karolhausman.github.io/mt-opt/
Efficient Adaptation for End-to-End Vision-Based Robotic Manipulation
Apr 21, 2020

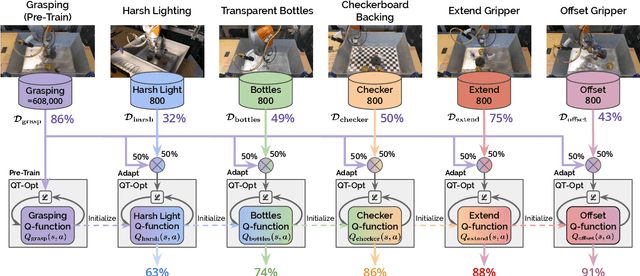
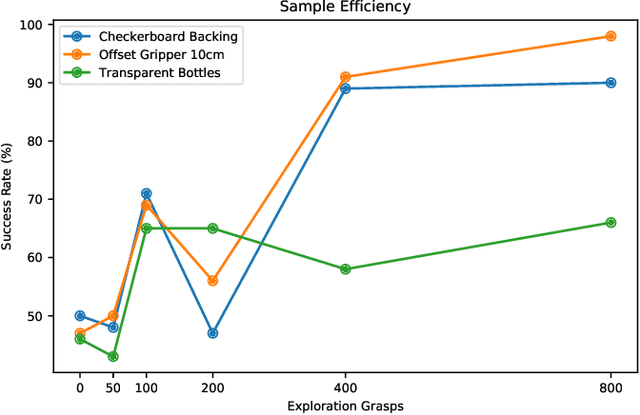
One of the great promises of robot learning systems is that they will be able to learn from their mistakes and continuously adapt to ever-changing environments. Despite this potential, most of the robot learning systems today are deployed as a fixed policy and they are not being adapted after their deployment. Can we efficiently adapt previously learned behaviors to new environments, objects and percepts in the real world? In this paper, we present a method and empirical evidence towards a robot learning framework that facilitates continuous adaption. In particular, we demonstrate how to adapt vision-based robotic manipulation policies to new variations by fine-tuning via off-policy reinforcement learning, including changes in background, object shape and appearance, lighting conditions, and robot morphology. Further, this adaptation uses less than 0.2% of the data necessary to learn the task from scratch. We find that our approach of adapting pre-trained policies leads to substantial performance gains over the course of fine-tuning, and that pre-training via RL is essential: training from scratch or adapting from supervised ImageNet features are both unsuccessful with such small amounts of data. We also find that these positive results hold in a limited continual learning setting, in which we repeatedly fine-tune a single lineage of policies using data from a succession of new tasks. Our empirical conclusions are consistently supported by experiments on simulated manipulation tasks, and by 52 unique fine-tuning experiments on a real robotic grasping system pre-trained on 580,000 grasps.