 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Planning and Control in Vision Based Robotics via Reward Machines
Dec 28, 2020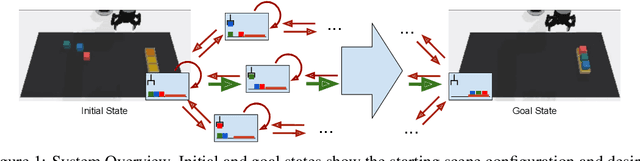
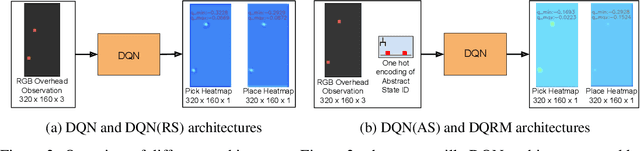
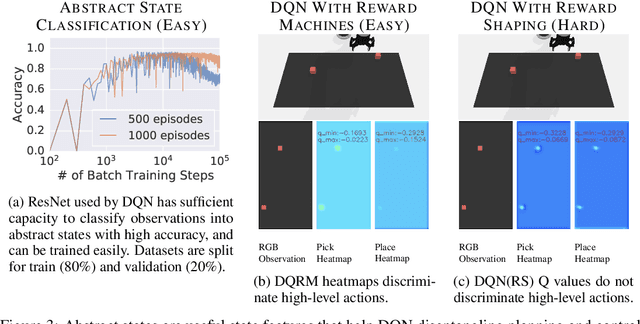
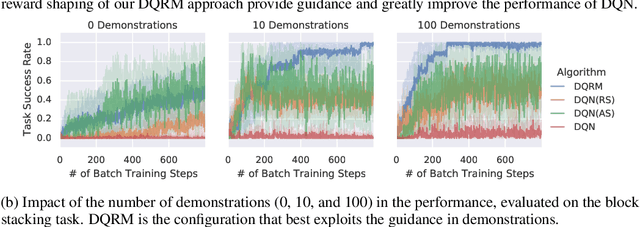
In this work we augment a Deep Q-Learning agent with a Reward Machine (DQRM) to increase speed of learning vision-based policies for robot tasks, and overcome some of the limitations of DQN that prevent it from converging to good-quality policies. A reward machine (RM) is a finite state machine that decomposes a task into a discrete planning graph and equips the agent with a reward function to guide it toward task completion. The reward machine can be used for both reward shaping, and informing the policy what abstract state it is currently at. An abstract state is a high level simplification of the current state, defined in terms of task relevant features. These two supervisory signals of reward shaping and knowledge of current abstract state coming from the reward machine complement each other and can both be used to improve policy performance as demonstrated on several vision based robotic pick and place tasks. Particularly for vision based robotics applications, it is often easier to build a reward machine than to try and get a policy to learn the task without this structure.
Towards Neural-Guided Program Synthesis for Linear Temporal Logic Specifications
Dec 31, 2019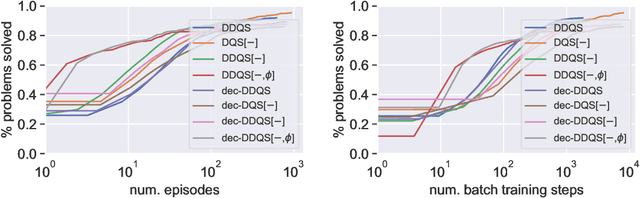
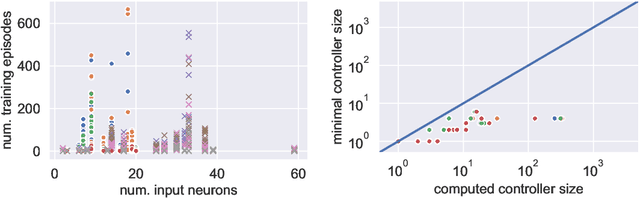
Synthesizing a program that realizes a logical specification is a classical problem in computer science. We examine a particular type of program synthesis, where the objective is to synthesize a strategy that reacts to a potentially adversarial environment while ensuring that all executions satisfy a Linear Temporal Logic (LTL) specification. Unfortunately, exact methods to solve so-called LTL synthesis via logical inference do not scale. In this work, we cast LTL synthesis as an optimization problem. We employ a neural network to learn a Q-function that is then used to guide search, and to construct programs that are subsequently verified for correctness. Our method is unique in combining search with deep learning to realize LTL synthesis. In our experiments the learned Q-function provides effective guidance for synthesis problems with relatively small specifications.
Finite LTL Synthesis with Environment Assumptions and Quality Measures
Aug 31, 2018In this paper, we investigate the problem of synthesizing strategies for linear temporal logic (LTL) specifications that are interpreted over finite traces -- a problem that is central to the automated construction of controllers, robot programs, and business processes. We study a natural variant of the finite LTL synthesis problem in which strategy guarantees are predicated on specified environment behavior. We further explore a quantitative extension of LTL that supports specification of quality measures, utilizing it to synthesize high-quality strategies. We propose new notions of optimality and associated algorithms that yield strategies that best satisfy specified quality measures. Our algorithms utilize an automata-game approach, positioning them well for future implementation via existing state-of-the-art techniques.
Finite LTL Synthesis is EXPTIME-complete
Nov 17, 2016
LTL synthesis -- the construction of a function to satisfy a logical specification formulated in Linear Temporal Logic -- is a 2EXPTIME-complete problem with relevant applications in controller synthesis and a myriad of artificial intelligence applications. In this research note we consider De Giacomo and Vardi's variant of the synthesis problem for LTL formulas interpreted over finite rather than infinite traces. Rather surprisingly, given the existing claims on complexity, we establish that LTL synthesis is EXPTIME-complete for the finite interpretation, and not 2EXPTIME-complete as previously reported. Our result coincides nicely with the planning perspective where non-deterministic planning with full observability is EXPTIME-complete and partial observability increases the complexity to 2EXPTIME-complete; a recent related result for LTL synthesis shows that in the finite case with partial observability, the problem is 2EXPTIME-complete.