 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Precise 3D Manipulation from Multiple Uncalibrated Cameras
Paper and Code
Feb 21, 2020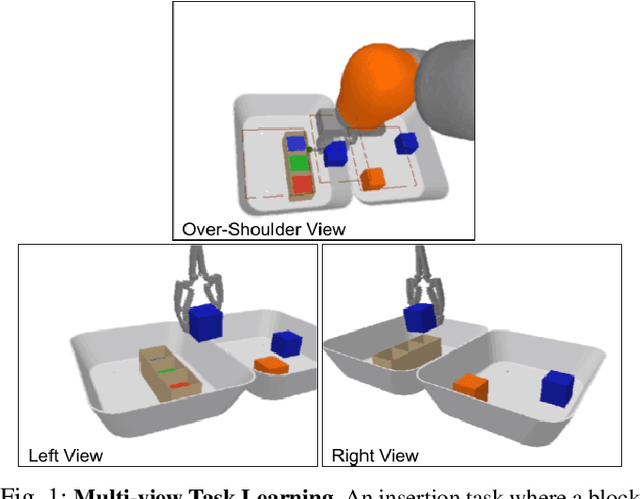
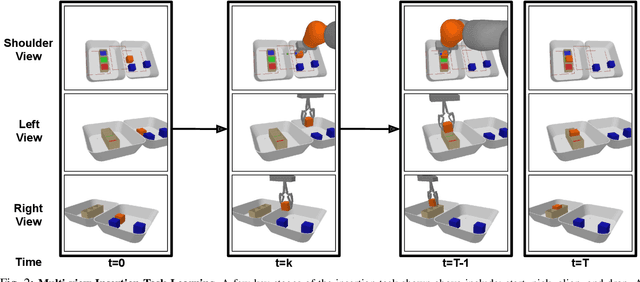
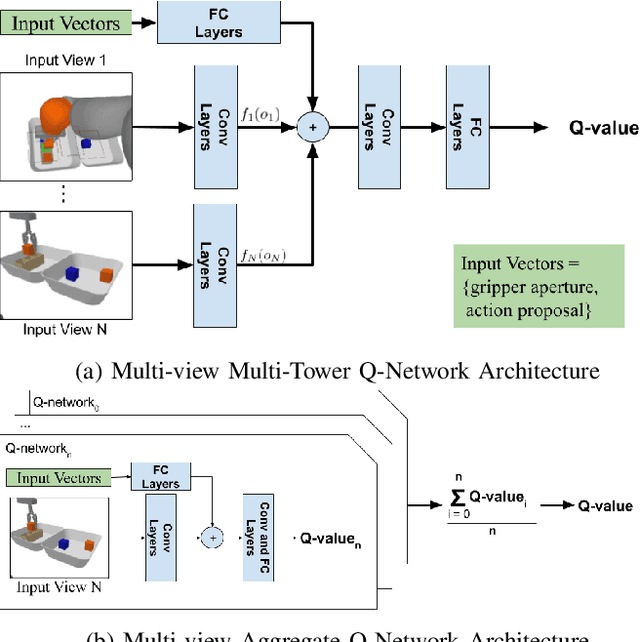
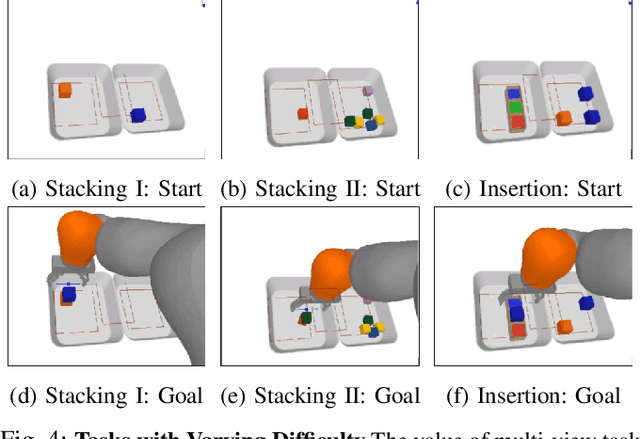
In this work, we present an effective multi-view approach to closed-loop end-to-end learning of precise manipulation tasks that are 3D in nature. Our method learns to accomplish these tasks using multiple statically placed but uncalibrated RGB camera views without building an explicit 3D representation such as a pointcloud or voxel grid. This multi-camera approach achieves superior task performance on difficult stacking and insertion tasks compared to single-view baselines. Single view robotic agents struggle from occlusion and challenges in estimating relative poses between points of interest. While full 3D scene representations (voxels or pointclouds) are obtainable from registered output of multiple depth sensors, several challenges complicate operating off such explicit 3D representations. These challenges include imperfect camera calibration, poor depth maps due to object properties such as reflective surfaces, and slower inference speeds over 3D representations compared to 2D images. Our use of static but uncalibrated cameras does not require camera-robot or camera-camera calibration making the proposed approach easy to setup and our use of \textit{sensor dropout} during training makes it resilient to the loss of camera-views after deployment.