 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Law of Iterated Expectations for Heuristic Estimators
Oct 02, 2024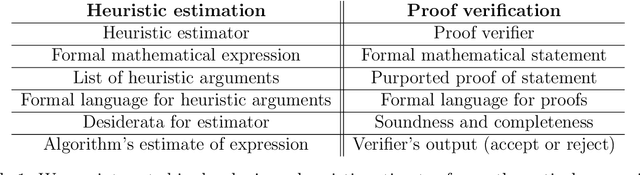

Christiano et al. (2022) define a *heuristic estimator* to be a hypothetical algorithm that estimates the values of mathematical expressions from arguments. In brief, a heuristic estimator $\mathbb{G}$ takes as input a mathematical expression $Y$ and a formal "heuristic argument" $\pi$, and outputs an estimate $\mathbb{G}(Y \mid \pi)$ of $Y$. In this work, we argue for the informal principle that a heuristic estimator ought not to be able to predict its own errors, and we explore approaches to formalizing this principle. Most simply, the principle suggests that $\mathbb{G}(Y - \mathbb{G}(Y \mid \pi) \mid \pi)$ ought to equal zero for all $Y$ and $\pi$. We argue that an ideal heuristic estimator ought to satisfy two stronger properties in this vein, which we term *iterated estimation* (by analogy to the law of iterated expectations) and *error orthogonality*. Although iterated estimation and error orthogonality are intuitively appealing, it can be difficult to determine whether a given heuristic estimator satisfies the properties. As an alternative approach, we explore *accuracy*: a property that (roughly) states that $\mathbb{G}$ has zero average error over a distribution of mathematical expressions. However, in the context of two estimation problems, we demonstrate barriers to creating an accurate heuristic estimator. We finish by discussing challenges and potential paths forward for finding a heuristic estimator that accords with our intuitive understanding of how such an estimator ought to behave, as well as the potential applications of heuristic estimators to understanding the behavior of neural networks.