 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining language models to follow instructions with human feedback
Mar 04, 2022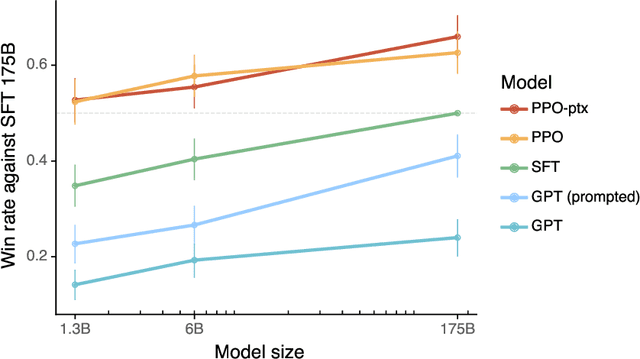

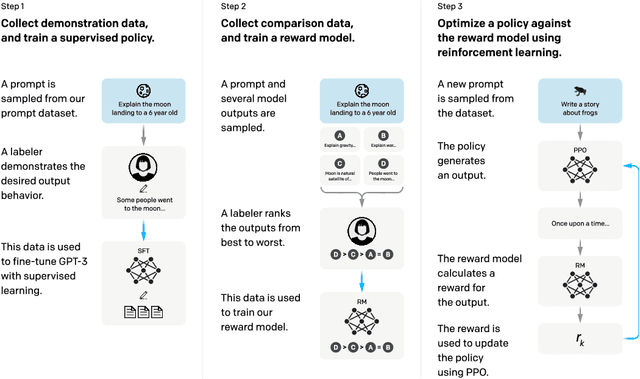

Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.
SafeLife 1.0: Exploring Side Effects in Complex Environments
Dec 03, 2019


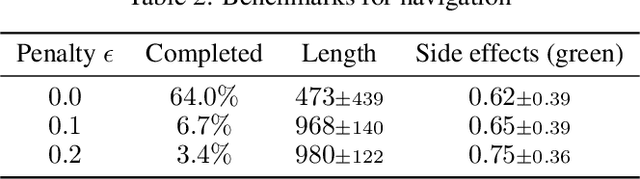
We present SafeLife, a publicly available reinforcement learning environment that tests the safety of reinforcement learning agents. It contains complex, dynamic, tunable, procedurally generated levels with many opportunities for unsafe behavior. Agents are graded both on their ability to maximize their explicit reward and on their ability to operate safely without unnecessary side effects. We train agents to maximize rewards using proximal policy optimization and score them on a suite of benchmark levels. The resulting agents are performant but not safe---they tend to cause large side effects in their environments---but they form a baseline against which future safety research can be measured.