 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling laws for single-agent reinforcement learning
Paper and Code

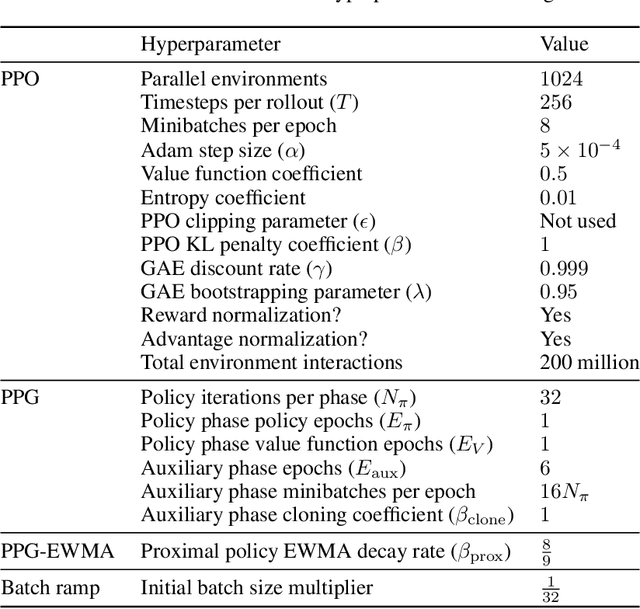

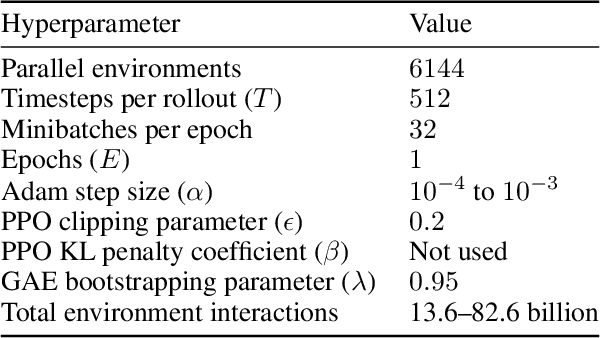
Recent work has shown that, in generative modeling, cross-entropy loss improves smoothly with model size and training compute, following a power law plus constant scaling law. One challenge in extending these results to reinforcement learning is that the main performance objective of interest, mean episode return, need not vary smoothly. To overcome this, we introduce *intrinsic performance*, a monotonic function of the return defined as the minimum compute required to achieve the given return across a family of models of different sizes. We find that, across a range of environments, intrinsic performance scales as a power law in model size and environment interactions. Consequently, as in generative modeling, the optimal model size scales as a power law in the training compute budget. Furthermore, we study how this relationship varies with the environment and with other properties of the training setup. In particular, using a toy MNIST-based environment, we show that varying the "horizon length" of the task mostly changes the coefficient but not the exponent of this relationship.