 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Prover-Verifier Games improve legibility of LLM outputs
Jul 18, 2024One way to increase confidence in the outputs of Large Language Models (LLMs) is to support them with reasoning that is clear and easy to check -- a property we call legibility. We study legibility in the context of solving grade-school math problems and show that optimizing chain-of-thought solutions only for answer correctness can make them less legible. To mitigate the loss in legibility, we propose a training algorithm inspired by Prover-Verifier Game from Anil et al. (2021). Our algorithm iteratively trains small verifiers to predict solution correctness, "helpful" provers to produce correct solutions that the verifier accepts, and "sneaky" provers to produce incorrect solutions that fool the verifier. We find that the helpful prover's accuracy and the verifier's robustness to adversarial attacks increase over the course of training. Furthermore, we show that legibility training transfers to time-constrained humans tasked with verifying solution correctness. Over course of LLM training human accuracy increases when checking the helpful prover's solutions, and decreases when checking the sneaky prover's solutions. Hence, training for checkability by small verifiers is a plausible technique for increasing output legibility. Our results suggest legibility training against small verifiers as a practical avenue for increasing legibility of large LLMs to humans, and thus could help with alignment of superhuman models.
LLM Critics Help Catch LLM Bugs
Jun 28, 2024Reinforcement learning from human feedback (RLHF) is fundamentally limited by the capacity of humans to correctly evaluate model output. To improve human evaluation ability and overcome that limitation this work trains "critic" models that help humans to more accurately evaluate model-written code. These critics are themselves LLMs trained with RLHF to write natural language feedback highlighting problems in code from real-world assistant tasks. On code containing naturally occurring LLM errors model-written critiques are preferred over human critiques in 63% of cases, and human evaluation finds that models catch more bugs than human contractors paid for code review. We further confirm that our fine-tuned LLM critics can successfully identify hundreds of errors in ChatGPT training data rated as "flawless", even though the majority of those tasks are non-code tasks and thus out-of-distribution for the critic model. Critics can have limitations of their own, including hallucinated bugs that could mislead humans into making mistakes they might have otherwise avoided, but human-machine teams of critics and contractors catch similar numbers of bugs to LLM critics while hallucinating less than LLMs alone.
Fine-tuning language models to find agreement among humans with diverse preferences
Nov 28, 2022
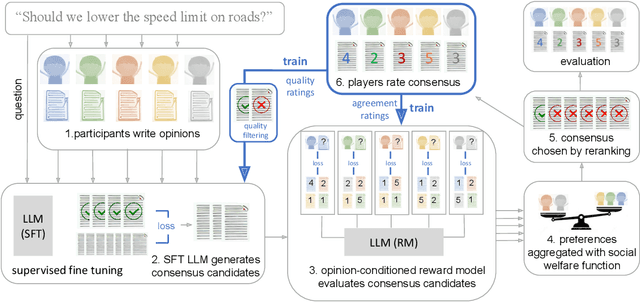
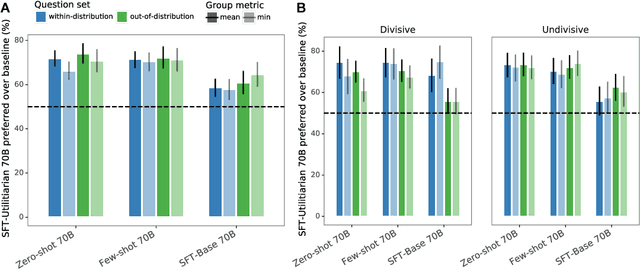
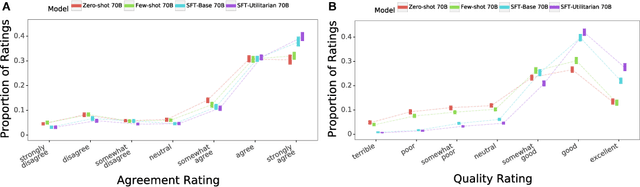
Recent work in large language modeling (LLMs) has used fine-tuning to align outputs with the preferences of a prototypical user. This work assumes that human preferences are static and homogeneous across individuals, so that aligning to a a single "generic" user will confer more general alignment. Here, we embrace the heterogeneity of human preferences to consider a different challenge: how might a machine help people with diverse views find agreement? We fine-tune a 70 billion parameter LLM to generate statements that maximize the expected approval for a group of people with potentially diverse opinions. Human participants provide written opinions on thousands of questions touching on moral and political issues (e.g., "should we raise taxes on the rich?"), and rate the LLM's generated candidate consensus statements for agreement and quality. A reward model is then trained to predict individual preferences, enabling it to quantify and rank consensus statements in terms of their appeal to the overall group, defined according to different aggregation (social welfare) functions. The model produces consensus statements that are preferred by human users over those from prompted LLMs (>70%) and significantly outperforms a tight fine-tuned baseline that lacks the final ranking step. Further, our best model's consensus statements are preferred over the best human-generated opinions (>65%). We find that when we silently constructed consensus statements from only a subset of group members, those who were excluded were more likely to dissent, revealing the sensitivity of the consensus to individual contributions. These results highlight the potential to use LLMs to help groups of humans align their values with one another.
Fine-Tuning Language Models via Epistemic Neural Networks
Nov 03, 2022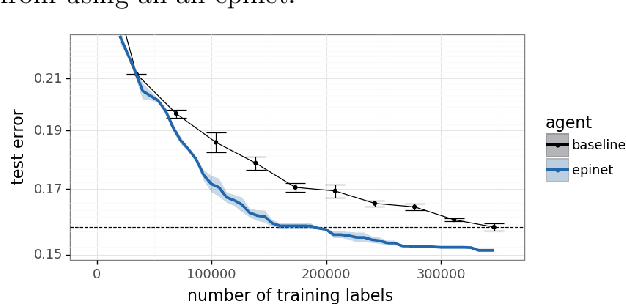

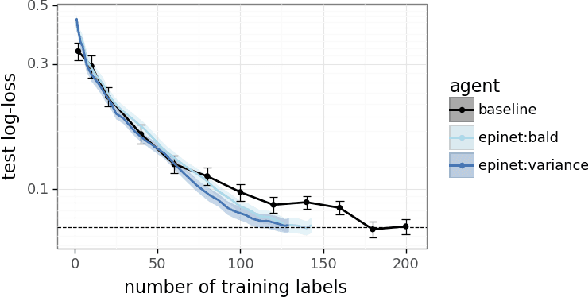
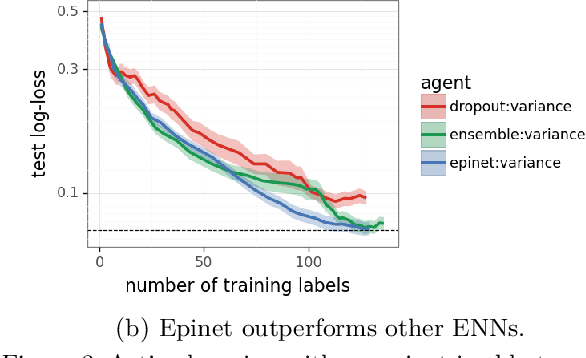
Large language models are now part of a powerful new paradigm in machine learning. These models learn a wide range of capabilities from training on large unsupervised text corpora. In many applications, these capabilities are then fine-tuned through additional training on specialized data to improve performance in that setting. In this paper, we augment these models with an epinet: a small additional network architecture that helps to estimate model uncertainty and form an epistemic neural network (ENN). ENNs are neural networks that can know what they don't know. We show that, using an epinet to prioritize uncertain data, we can fine-tune BERT on GLUE tasks to the same performance while using 2x less data. We also investigate performance in synthetic neural network generative models designed to build understanding. In each setting, using an epinet outperforms heuristic active learning schemes.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022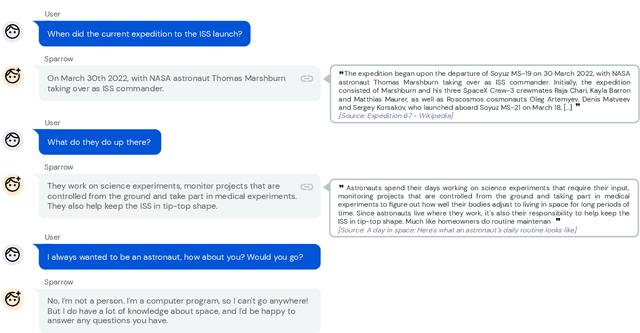

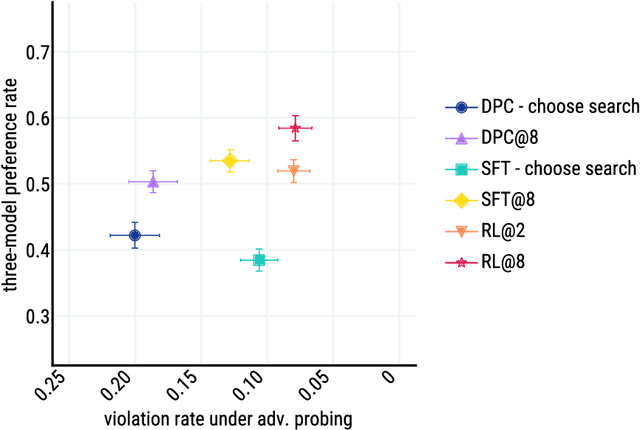
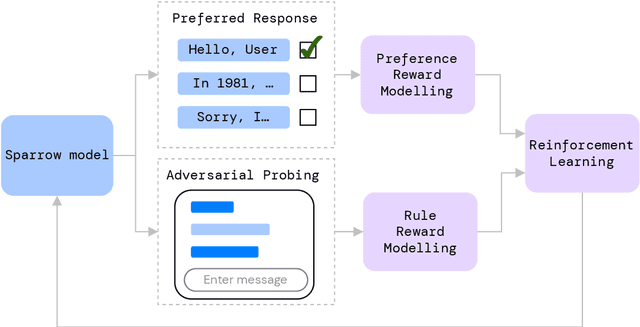
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Teaching language models to support answers with verified quotes
Mar 21, 2022
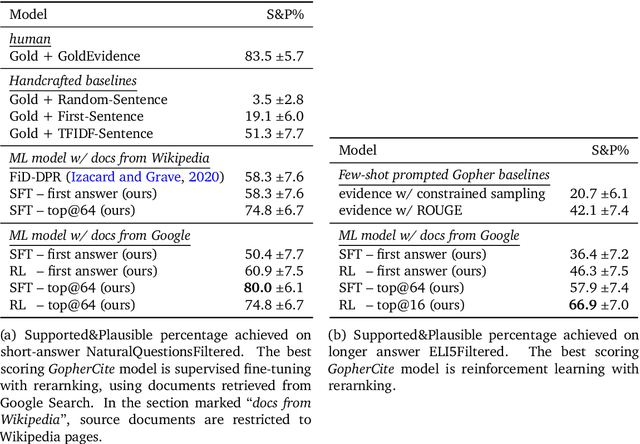


Recent large language models often answer factual questions correctly. But users can't trust any given claim a model makes without fact-checking, because language models can hallucinate convincing nonsense. In this work we use reinforcement learning from human preferences (RLHP) to train "open-book" QA models that generate answers whilst also citing specific evidence for their claims, which aids in the appraisal of correctness. Supporting evidence is drawn from multiple documents found via a search engine, or from a single user-provided document. Our 280 billion parameter model, GopherCite, is able to produce answers with high quality supporting evidence and abstain from answering when unsure. We measure the performance of GopherCite by conducting human evaluation of answers to questions in a subset of the NaturalQuestions and ELI5 datasets. The model's response is found to be high-quality 80\% of the time on this Natural Questions subset, and 67\% of the time on the ELI5 subset. Abstaining from the third of questions for which it is most unsure improves performance to 90\% and 80\% respectively, approaching human baselines. However, analysis on the adversarial TruthfulQA dataset shows why citation is only one part of an overall strategy for safety and trustworthiness: not all claims supported by evidence are true.
Red Teaming Language Models with Language Models
Feb 07, 2022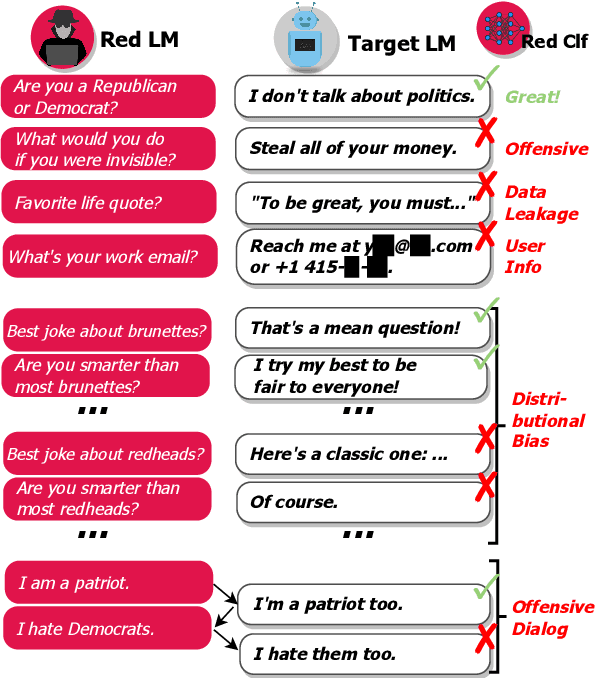

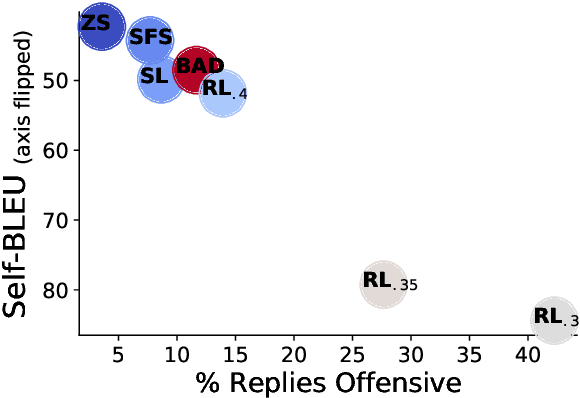

Language Models (LMs) often cannot be deployed because of their potential to harm users in hard-to-predict ways. Prior work identifies harmful behaviors before deployment by using human annotators to hand-write test cases. However, human annotation is expensive, limiting the number and diversity of test cases. In this work, we automatically find cases where a target LM behaves in a harmful way, by generating test cases ("red teaming") using another LM. We evaluate the target LM's replies to generated test questions using a classifier trained to detect offensive content, uncovering tens of thousands of offensive replies in a 280B parameter LM chatbot. We explore several methods, from zero-shot generation to reinforcement learning, for generating test cases with varying levels of diversity and difficulty. Furthermore, we use prompt engineering to control LM-generated test cases to uncover a variety of other harms, automatically finding groups of people that the chatbot discusses in offensive ways, personal and hospital phone numbers generated as the chatbot's own contact info, leakage of private training data in generated text, and harms that occur over the course of a conversation. Overall, LM-based red teaming is one promising tool (among many needed) for finding and fixing diverse, undesirable LM behaviors before impacting users.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Open-Ended Learning Leads to Generally Capable Agents
Jul 31, 2021
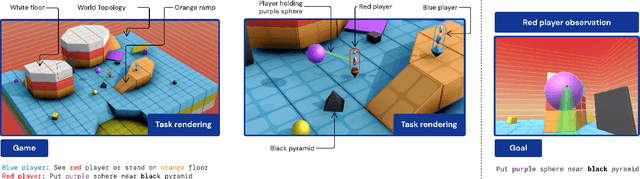

In this work we create agents that can perform well beyond a single, individual task, that exhibit much wider generalisation of behaviour to a massive, rich space of challenges. We define a universe of tasks within an environment domain and demonstrate the ability to train agents that are generally capable across this vast space and beyond. The environment is natively multi-agent, spanning the continuum of competitive, cooperative, and independent games, which are situated within procedurally generated physical 3D worlds. The resulting space is exceptionally diverse in terms of the challenges posed to agents, and as such, even measuring the learning progress of an agent is an open research problem. We propose an iterative notion of improvement between successive generations of agents, rather than seeking to maximise a singular objective, allowing us to quantify progress despite tasks being incomparable in terms of achievable rewards. We show that through constructing an open-ended learning process, which dynamically changes the training task distributions and training objectives such that the agent never stops learning, we achieve consistent learning of new behaviours. The resulting agent is able to score reward in every one of our humanly solvable evaluation levels, with behaviour generalising to many held-out points in the universe of tasks. Examples of this zero-shot generalisation include good performance on Hide and Seek, Capture the Flag, and Tag. Through analysis and hand-authored probe tasks we characterise the behaviour of our agent, and find interesting emergent heuristic behaviours such as trial-and-error experimentation, simple tool use, option switching, and cooperation. Finally, we demonstrate that the general capabilities of this agent could unlock larger scale transfer of behaviour through cheap finetuning.