 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Language Models via Epistemic Neural Networks
Paper and Code
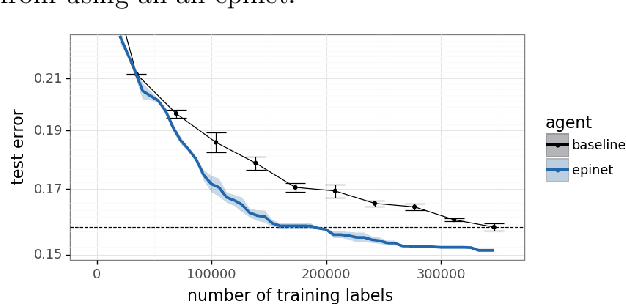

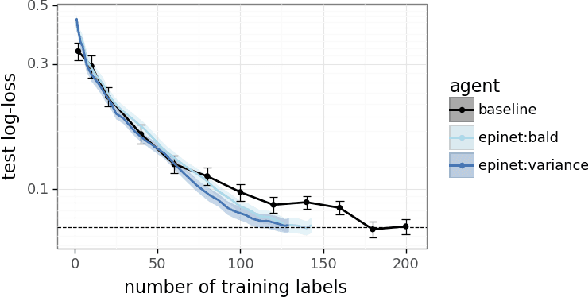
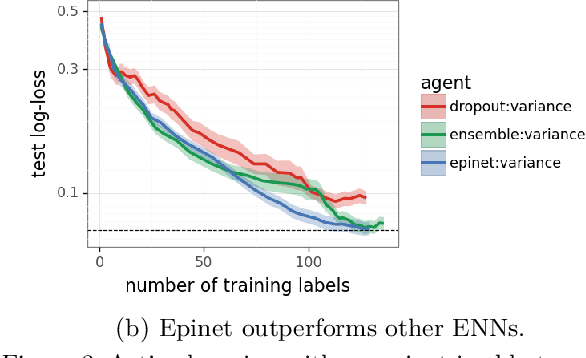
Large language models are now part of a powerful new paradigm in machine learning. These models learn a wide range of capabilities from training on large unsupervised text corpora. In many applications, these capabilities are then fine-tuned through additional training on specialized data to improve performance in that setting. In this paper, we augment these models with an epinet: a small additional network architecture that helps to estimate model uncertainty and form an epistemic neural network (ENN). ENNs are neural networks that can know what they don't know. We show that, using an epinet to prioritize uncertain data, we can fine-tune BERT on GLUE tasks to the same performance while using 2x less data. We also investigate performance in synthetic neural network generative models designed to build understanding. In each setting, using an epinet outperforms heuristic active learning schemes.