 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCadVLM: Bridging Language and Vision in the Generation of Parametric CAD Sketches
Sep 26, 2024



Parametric Computer-Aided Design (CAD) is central to contemporary mechanical design. However, it encounters challenges in achieving precise parametric sketch modeling and lacks practical evaluation metrics suitable for mechanical design. We harness the capabilities of pre-trained foundation models, renowned for their successes in natural language processing and computer vision, to develop generative models specifically for CAD. These models are adept at understanding complex geometries and design reasoning, a crucial advancement in CAD technology. In this paper, we propose CadVLM, an end-to-end vision language model for CAD generation. Our approach involves adapting pre-trained foundation models to manipulate engineering sketches effectively, integrating both sketch primitive sequences and sketch images. Extensive experiments demonstrate superior performance on multiple CAD sketch generation tasks such as CAD autocompletion, CAD autoconstraint, and image conditional generation. To our knowledge, this is the first instance of a multimodal Large Language Model (LLM) being successfully applied to parametric CAD generation, representing a pioneering step in the field of computer-aided mechanical design.
Scaling Laws for Autoregressive Generative Modeling
Nov 06, 2020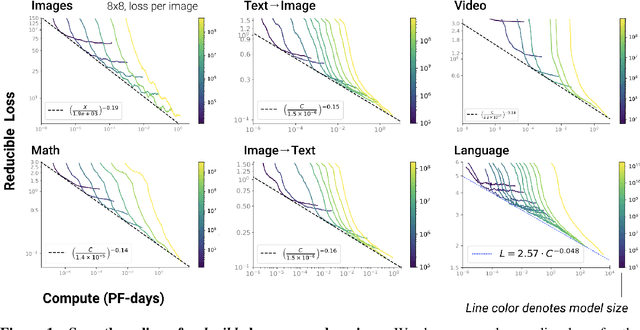
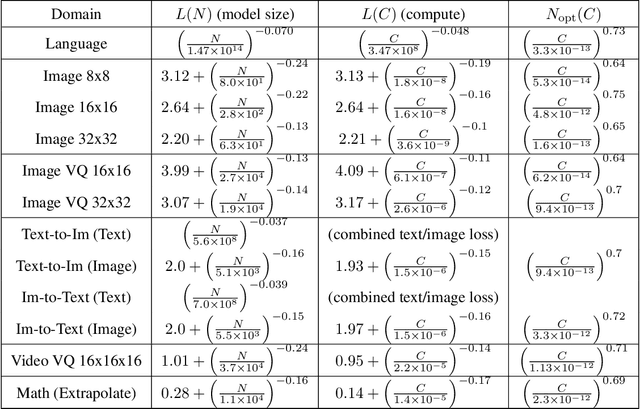
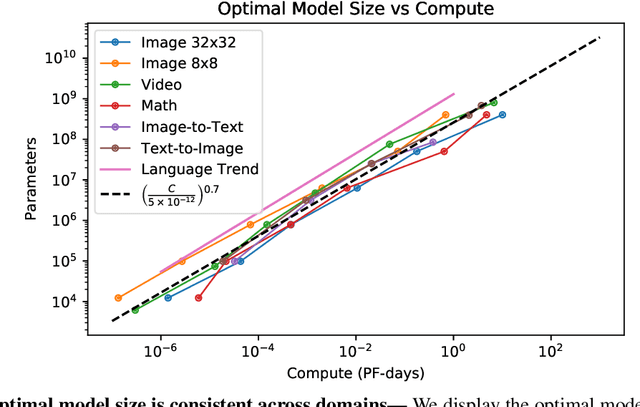

We identify empirical scaling laws for the cross-entropy loss in four domains: generative image modeling, video modeling, multimodal image$\leftrightarrow$text models, and mathematical problem solving. In all cases autoregressive Transformers smoothly improve in performance as model size and compute budgets increase, following a power-law plus constant scaling law. The optimal model size also depends on the compute budget through a power-law, with exponents that are nearly universal across all data domains. The cross-entropy loss has an information theoretic interpretation as $S($True$) + D_{\mathrm{KL}}($True$||$Model$)$, and the empirical scaling laws suggest a prediction for both the true data distribution's entropy and the KL divergence between the true and model distributions. With this interpretation, billion-parameter Transformers are nearly perfect models of the YFCC100M image distribution downsampled to an $8\times 8$ resolution, and we can forecast the model size needed to achieve any given reducible loss (ie $D_{\mathrm{KL}}$) in nats/image for other resolutions. We find a number of additional scaling laws in specific domains: (a) we identify a scaling relation for the mutual information between captions and images in multimodal models, and show how to answer the question "Is a picture worth a thousand words?"; (b) in the case of mathematical problem solving, we identify scaling laws for model performance when extrapolating beyond the training distribution; (c) we finetune generative image models for ImageNet classification and find smooth scaling of the classification loss and error rate, even as the generative loss levels off. Taken together, these results strengthen the case that scaling laws have important implications for neural network performance, including on downstream tasks.