 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Supervised Speaker Diarization
Paper and Code
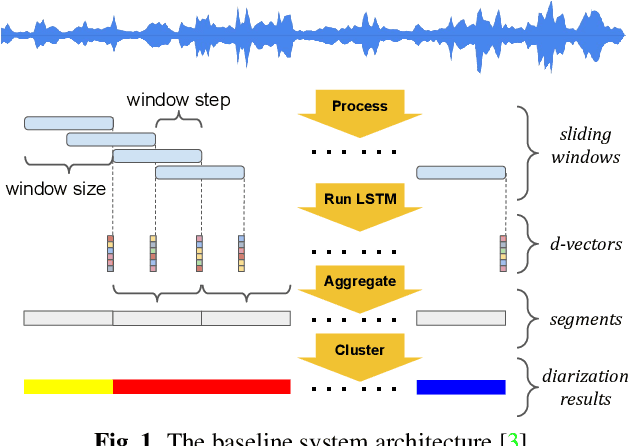
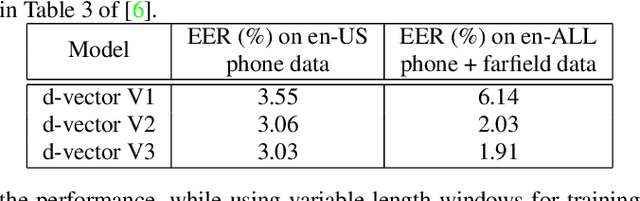
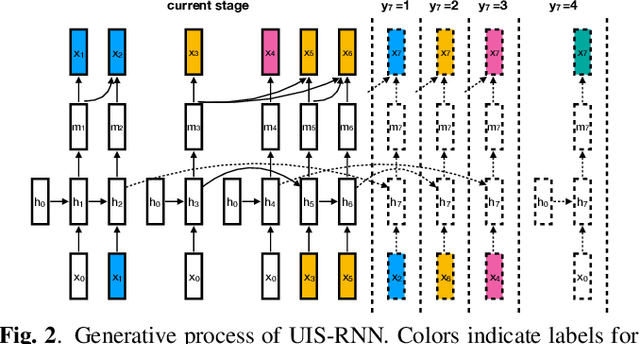

In this paper, we propose a fully supervised speaker diarization approach, named unbounded interleaved-state recurrent neural networks (UIS-RNN). Given extracted speaker-discriminative embeddings (a.k.a. d-vectors) from input utterances, each individual speaker is modeled by a parameter-sharing RNN, while the RNN states for different speakers interleave in the time domain. This RNN is naturally integrated with a distance-dependent Chinese restaurant process (ddCRP) to accommodate an unknown number of speakers. Our system is fully supervised and is able to learn from examples where time-stamped speaker labels are annotated. We achieved a 7.6% diarization error rate on NIST SRE 2000 CALLHOME, which is better than the state-of-the-art method using spectral clustering. Moreover, our method decodes in an online fashion while most state-of-the-art systems rely on offline clustering.