 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multiscale Features Directly From Waveforms
Apr 05, 2016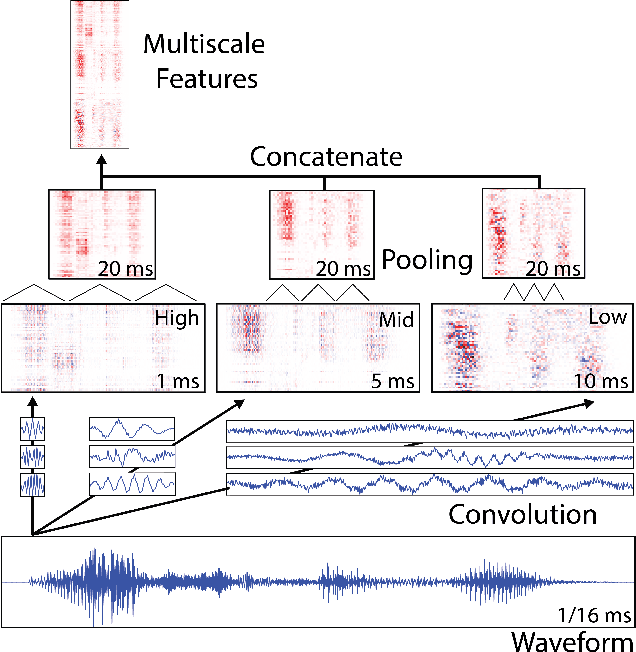



Deep learning has dramatically improved the performance of speech recognition systems through learning hierarchies of features optimized for the task at hand. However, true end-to-end learning, where features are learned directly from waveforms, has only recently reached the performance of hand-tailored representations based on the Fourier transform. In this paper, we detail an approach to use convolutional filters to push past the inherent tradeoff of temporal and frequency resolution that exists for spectral representations. At increased computational cost, we show that increasing temporal resolution via reduced stride and increasing frequency resolution via additional filters delivers significant performance improvements. Further, we find more efficient representations by simultaneously learning at multiple scales, leading to an overall decrease in word error rate on a difficult internal speech test set by 20.7% relative to networks with the same number of parameters trained on spectrograms.