 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Form Last Layer Optimization
Oct 06, 2025Neural networks are typically optimized with variants of stochastic gradient descent. Under a squared loss, however, the optimal solution to the linear last layer weights is known in closed-form. We propose to leverage this during optimization, treating the last layer as a function of the backbone parameters, and optimizing solely for these parameters. We show this is equivalent to alternating between gradient descent steps on the backbone and closed-form updates on the last layer. We adapt the method for the setting of stochastic gradient descent, by trading off the loss on the current batch against the accumulated information from previous batches. Further, we prove that, in the Neural Tangent Kernel regime, convergence of this method to an optimal solution is guaranteed. Finally, we demonstrate the effectiveness of our approach compared with standard SGD on a squared loss in several supervised tasks -- both regression and classification -- including Fourier Neural Operators and Instrumental Variable Regression.
Density Ratio-Free Doubly Robust Proxy Causal Learning
May 26, 2025We study the problem of causal function estimation in the Proxy Causal Learning (PCL) framework, where confounders are not observed but proxies for the confounders are available. Two main approaches have been proposed: outcome bridge-based and treatment bridge-based methods. In this work, we propose two kernel-based doubly robust estimators that combine the strengths of both approaches, and naturally handle continuous and high-dimensional variables. Our identification strategy builds on a recent density ratio-free method for treatment bridge-based PCL; furthermore, in contrast to previous approaches, it does not require indicator functions or kernel smoothing over the treatment variable. These properties make it especially well-suited for continuous or high-dimensional treatments. By using kernel mean embeddings, we have closed-form solutions and strong consistency guarantees. Our estimators outperform existing methods on PCL benchmarks, including a prior doubly robust method that requires both kernel smoothing and density ratio estimation.
Density Ratio-based Proxy Causal Learning Without Density Ratios
Mar 11, 2025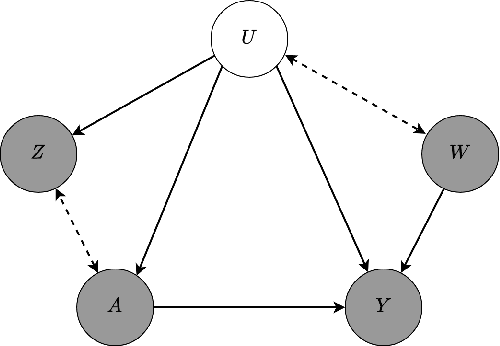
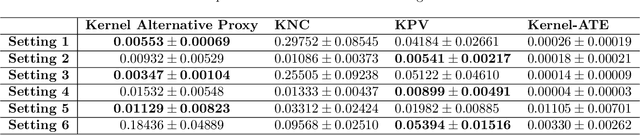
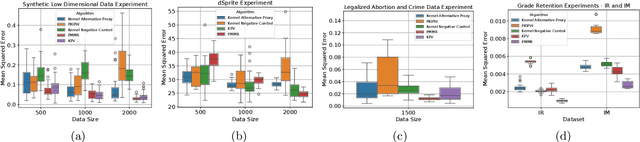
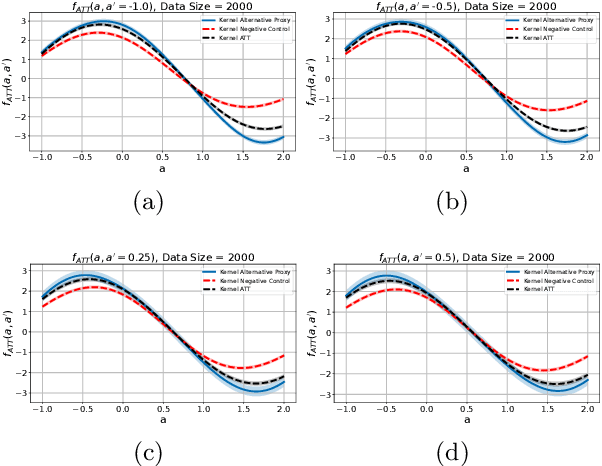
We address the setting of Proxy Causal Learning (PCL), which has the goal of estimating causal effects from observed data in the presence of hidden confounding. Proxy methods accomplish this task using two proxy variables related to the latent confounder: a treatment proxy (related to the treatment) and an outcome proxy (related to the outcome). Two approaches have been proposed to perform causal effect estimation given proxy variables; however only one of these has found mainstream acceptance, since the other was understood to require density ratio estimation - a challenging task in high dimensions. In the present work, we propose a practical and effective implementation of the second approach, which bypasses explicit density ratio estimation and is suitable for continuous and high-dimensional treatments. We employ kernel ridge regression to derive estimators, resulting in simple closed-form solutions for dose-response and conditional dose-response curves, along with consistency guarantees. Our methods empirically demonstrate superior or comparable performance to existing frameworks on synthetic and real-world datasets.
Kernel Single Proxy Control for Deterministic Confounding
Aug 08, 2023We consider the problem of causal effect estimation with an unobserved confounder, where we observe a proxy variable that is associated with the confounder. Although Proxy Causal Learning (PCL) uses two proxy variables to recover the true causal effect, we show that a single proxy variable is sufficient for causal estimation if the outcome is generated deterministically, generalizing Control Outcome Calibration Approach (COCA). We propose two kernel-based methods for this setting: the first based on the two-stage regression approach, and the second based on a maximum moment restriction approach. We prove that both approaches can consistently estimate the causal effect, and we empirically demonstrate that we can successfully recover the causal effect on a synthetic dataset.
A Neural Mean Embedding Approach for Back-door and Front-door Adjustment
Oct 12, 2022


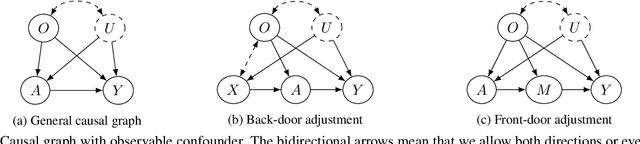
We consider the estimation of average and counterfactual treatment effects, under two settings: back-door adjustment and front-door adjustment. The goal in both cases is to recover the treatment effect without having an access to a hidden confounder. This objective is attained by first estimating the conditional mean of the desired outcome variable given relevant covariates (the "first stage" regression), and then taking the (conditional) expectation of this function as a "second stage" procedure. We propose to compute these conditional expectations directly using a regression function to the learned input features of the first stage, thus avoiding the need for sampling or density estimation. All functions and features (and in particular, the output features in the second stage) are neural networks learned adaptively from data, with the sole requirement that the final layer of the first stage should be linear. The proposed method is shown to converge to the true causal parameter, and outperforms the recent state-of-the-art methods on challenging causal benchmarks, including settings involving high-dimensional image data.
Importance Weighting Approach in Kernel Bayes' Rule
Feb 05, 2022

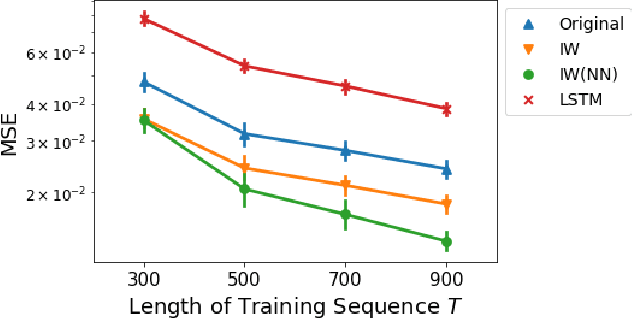
We study a nonparametric approach to Bayesian computation via feature means, where the expectation of prior features is updated to yield expected posterior features, based on regression from kernel or neural net features of the observations. All quantities involved in the Bayesian update are learned from observed data, making the method entirely model-free. The resulting algorithm is a novel instance of a kernel Bayes' rule (KBR). Our approach is based on importance weighting, which results in superior numerical stability to the existing approach to KBR, which requires operator inversion. We show the convergence of the estimator using a novel consistency analysis on the importance weighting estimator in the infinity norm. We evaluate our KBR on challenging synthetic benchmarks, including a filtering problem with a state-space model involving high dimensional image observations. The proposed method yields uniformly better empirical performance than the existing KBR, and competitive performance with other competing methods.
Kernel Methods for Multistage Causal Inference: Mediation Analysis and Dynamic Treatment Effects
Nov 06, 2021


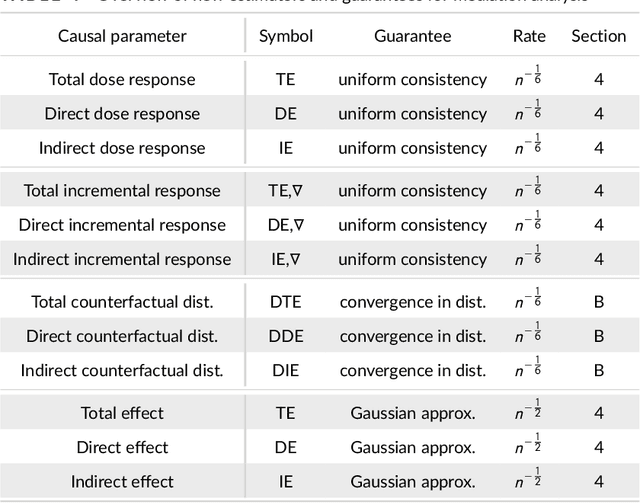
We propose kernel ridge regression estimators for mediation analysis and dynamic treatment effects over short horizons. We allow treatments, covariates, and mediators to be discrete or continuous, and low, high, or infinite dimensional. We propose estimators of means, increments, and distributions of counterfactual outcomes with closed form solutions in terms of kernel matrix operations. For the continuous treatment case, we prove uniform consistency with finite sample rates. For the discrete treatment case, we prove root-n consistency, Gaussian approximation, and semiparametric efficiency. We conduct simulations then estimate mediated and dynamic treatment effects of the US Job Corps program for disadvantaged youth.
Deep Proxy Causal Learning and its Application to Confounded Bandit Policy Evaluation
Jun 07, 2021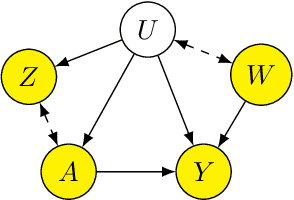
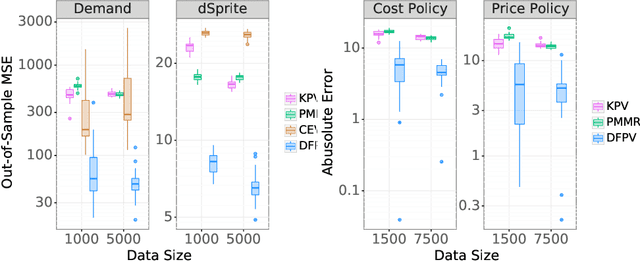

Proxy causal learning (PCL) is a method for estimating the causal effect of treatments on outcomes in the presence of unobserved confounding, using proxies (structured side information) for the confounder. This is achieved via two-stage regression: in the first stage, we model relations among the treatment and proxies; in the second stage, we use this model to learn the effect of treatment on the outcome, given the context provided by the proxies. PCL guarantees recovery of the true causal effect, subject to identifiability conditions. We propose a novel method for PCL, the deep feature proxy variable method (DFPV), to address the case where the proxies, treatments, and outcomes are high-dimensional and have nonlinear complex relationships, as represented by deep neural network features. We show that DFPV outperforms recent state-of-the-art PCL methods on challenging synthetic benchmarks, including settings involving high dimensional image data. Furthermore, we show that PCL can be applied to off-policy evaluation for the confounded bandit problem, in which DFPV also exhibits competitive performance.
On Instrumental Variable Regression for Deep Offline Policy Evaluation
May 21, 2021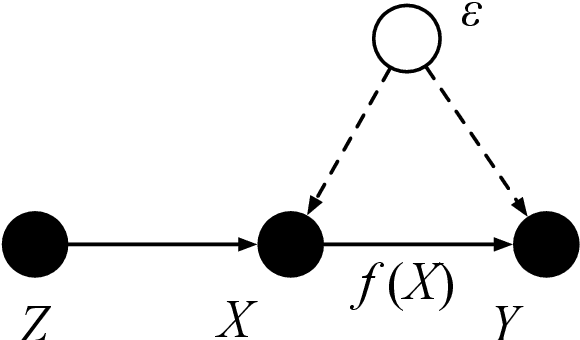
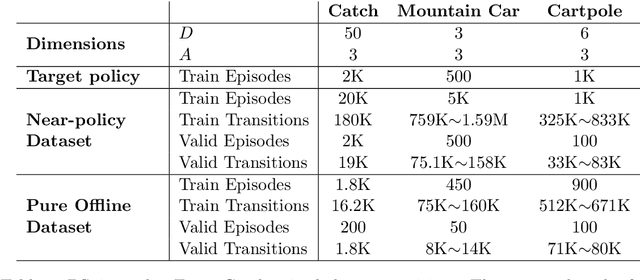
We show that the popular reinforcement learning (RL) strategy of estimating the state-action value (Q-function) by minimizing the mean squared Bellman error leads to a regression problem with confounding, the inputs and output noise being correlated. Hence, direct minimization of the Bellman error can result in significantly biased Q-function estimates. We explain why fixing the target Q-network in Deep Q-Networks and Fitted Q Evaluation provides a way of overcoming this confounding, thus shedding new light on this popular but not well understood trick in the deep RL literature. An alternative approach to address confounding is to leverage techniques developed in the causality literature, notably instrumental variables (IV). We bring together here the literature on IV and RL by investigating whether IV approaches can lead to improved Q-function estimates. This paper analyzes and compares a wide range of recent IV methods in the context of offline policy evaluation (OPE), where the goal is to estimate the value of a policy using logged data only. By applying different IV techniques to OPE, we are not only able to recover previously proposed OPE methods such as model-based techniques but also to obtain competitive new techniques. We find empirically that state-of-the-art OPE methods are closely matched in performance by some IV methods such as AGMM, which were not developed for OPE. We open-source all our code and datasets at https://github.com/liyuan9988/IVOPEwithACME.
Learning Deep Features in Instrumental Variable Regression
Nov 01, 2020
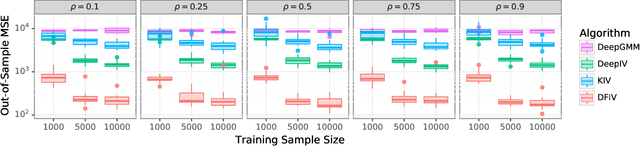

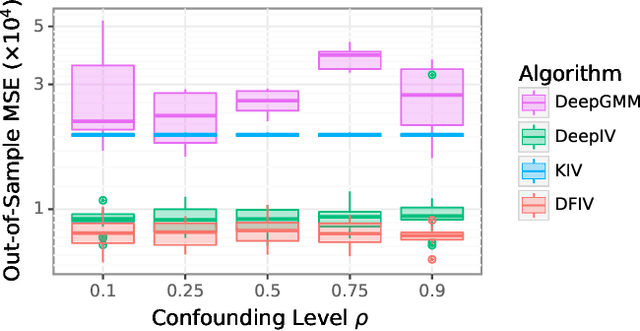
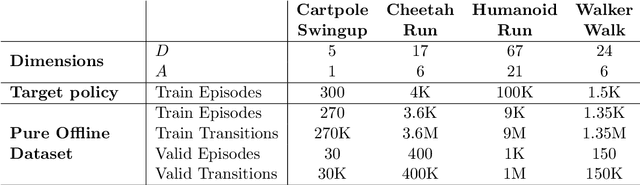
Instrumental variable (IV) regression is a standard strategy for learning causal relationships between confounded treatment and outcome variables from observational data by utilizing an instrumental variable, which affects the outcome only through the treatment. In classical IV regression, learning proceeds in two stages: stage 1 performs linear regression from the instrument to the treatment; and stage 2 performs linear regression from the treatment to the outcome, conditioned on the instrument. We propose a novel method, deep feature instrumental variable regression (DFIV), to address the case where relations between instruments, treatments, and outcomes may be nonlinear. In this case, deep neural nets are trained to define informative nonlinear features on the instruments and treatments. We propose an alternating training regime for these features to ensure good end-to-end performance when composing stages 1 and 2, thus obtaining highly flexible feature maps in a computationally efficient manner. DFIV outperforms recent state-of-the-art methods on challenging IV benchmarks, including settings involving high dimensional image data. DFIV also exhibits competitive performance in off-policy policy evaluation for reinforcement learning, which can be understood as an IV regression task.