 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Probability Bounds for SGD under the Polyak-Lojasiewicz Condition with Markovian Noise
Mar 15, 2026We present the first uniform-in-time high-probability bound for SGD under the PL condition, where the gradient noise contains both Markovian and martingale difference components. This significantly broadens the scope of finite-time guarantees, as the PL condition arises in many machine learning and deep learning models while Markovian noise naturally arises in decentralized optimization and online system identification problems. We further allow the magnitude of noise to grow with the function value, enabling the analysis of many practical sampling strategies. In addition to the high-probability guarantee, we establish a matching $1/k$ decay rate for the expected suboptimality. Our proof technique relies on the Poisson equation to handle the Markovian noise and a probabilistic induction argument to address the lack of almost-sure bounds on the objective. Finally, we demonstrate the applicability of our framework by analyzing three practical optimization problems: token-based decentralized linear regression, supervised learning with subsampling for privacy amplification, and online system identification.
Regret and Sample Complexity of Online Q-Learning via Concentration of Stochastic Approximation with Time-Inhomogeneous Markov Chains
Feb 18, 2026We present the first high-probability regret bound for classical online Q-learning in infinite-horizon discounted Markov decision processes, without relying on optimism or bonus terms. We first analyze Boltzmann Q-learning with decaying temperature and show that its regret depends critically on the suboptimality gap of the MDP: for sufficiently large gaps, the regret is sublinear, while for small gaps it deteriorates and can approach linear growth. To address this limitation, we study a Smoothed $ε_n$-Greedy exploration scheme that combines $ε_n$-greedy and Boltzmann exploration, for which we prove a gap-robust regret bound of near-$\tilde{O}(N^{9/10})$. To analyze these algorithms, we develop a high-probability concentration bound for contractive Markovian stochastic approximation with iterate- and time-dependent transition dynamics. This bound may be of independent interest as the contraction factor in our bound is governed by the mixing time and is allowed to converge to one asymptotically.
Cross-Frequency Bispectral EEG Analysis of Reach-to-Grasp Planning and Execution
Feb 03, 2026Neural control of grasping arises from nonlinear interactions across multiple brain rhythms, yet EEG-based motor decoding has largely relied on linear, second-order spectral features. Here, we examine whether higher-order cross-frequency dynamics distinguish motor planning from execution during natural reach-to-grasp behavior. EEG was recorded in a cue-based paradigm during executed precision and power grips, enabling stage-resolved analysis of preparatory and execution-related neural activity. Cross-frequency bispectral analysis was used to compute bicoherence matrices across canonical frequency band pairs, from which magnitude- and phase-based features were extracted. Classification, permutation-based feature selection, and within-subject statistical testing showed that execution is characterized by substantially stronger and more discriminative nonlinear coupling than planning, with dominant contributions from beta- and gamma-driven interactions. In contrast, decoding of precision versus power grips achieved comparable performance during planning and execution, indicating that grasp-type representations emerge during planning and persist into execution. Spatial and spectral analyses further revealed that informative bispectral features reflect coordinated activity across prefrontal, central, and occipital regions. Despite substantial feature redundancy, effective dimensionality reduction preserved decoding performance. Together, these findings demonstrate that nonlinear cross-frequency coupling provides an interpretable and robust marker of motor planning and execution, extending bispectral EEG analysis to ecologically valid grasping and supporting its relevance for brain-computer interfaces and neuroprosthetic control.
Canonical correlation regression with noisy data
Dec 27, 2025We study instrumental variable regression in data rich environments. The goal is to estimate a linear model from many noisy covariates and many noisy instruments. Our key assumption is that true covariates and true instruments are repetitive, though possibly different in nature; they each reflect a few underlying factors, however those underlying factors may be misaligned. We analyze a family of estimators based on two stage least squares with spectral regularization: canonical correlations between covariates and instruments are learned in the first stage, which are used as regressors in the second stage. As a theoretical contribution, we derive upper and lower bounds on estimation error, proving optimality of the method with noisy data. As a practical contribution, we provide guidance on which types of spectral regularization to use in different regimes.
Revealing Temporal Label Noise in Multimodal Hateful Video Classification
Aug 06, 2025The rapid proliferation of online multimedia content has intensified the spread of hate speech, presenting critical societal and regulatory challenges. While recent work has advanced multimodal hateful video detection, most approaches rely on coarse, video-level annotations that overlook the temporal granularity of hateful content. This introduces substantial label noise, as videos annotated as hateful often contain long non-hateful segments. In this paper, we investigate the impact of such label ambiguity through a fine-grained approach. Specifically, we trim hateful videos from the HateMM and MultiHateClip English datasets using annotated timestamps to isolate explicitly hateful segments. We then conduct an exploratory analysis of these trimmed segments to examine the distribution and characteristics of both hateful and non-hateful content. This analysis highlights the degree of semantic overlap and the confusion introduced by coarse, video-level annotations. Finally, controlled experiments demonstrated that time-stamp noise fundamentally alters model decision boundaries and weakens classification confidence, highlighting the inherent context dependency and temporal continuity of hate speech expression. Our findings provide new insights into the temporal dynamics of multimodal hateful videos and highlight the need for temporally aware models and benchmarks for improved robustness and interpretability. Code and data are available at https://github.com/Multimodal-Intelligence-Lab-MIL/HatefulVideoLabelNoise.
GVPT -- A software for guided visual pitch tracking
May 01, 2025GVPT (Guided visual pitch tracking) is a publicly available, real-time pitch tracking software designed to guide and evaluate vocal pitch control using visual feedback. Developed for clinical and research applications, the system presents various visual target pitch contour and overlays the subject's pitch in real-time to promote accurate vocal reproduction. GVPT supports difficulty modification, session logging, and precise pitch tracking. The software enables voice pitch control exercise in both experimental and therapeutic settings.
Model Risk Management for Generative AI In Financial Institutions
Mar 19, 2025The success of OpenAI's ChatGPT in 2023 has spurred financial enterprises into exploring Generative AI applications to reduce costs or drive revenue within different lines of businesses in the Financial Industry. While these applications offer strong potential for efficiencies, they introduce new model risks, primarily hallucinations and toxicity. As highly regulated entities, financial enterprises (primarily large US banks) are obligated to enhance their model risk framework with additional testing and controls to ensure safe deployment of such applications. This paper outlines the key aspects for model risk management of generative AI model with a special emphasis on additional practices required in model validation.
Program Evaluation with Remotely Sensed Outcomes
Nov 17, 2024While traditional program evaluations typically rely on surveys to measure outcomes, certain economic outcomes such as living standards or environmental quality may be infeasible or costly to collect. As a result, recent empirical work estimates treatment effects using remotely sensed variables (RSVs), such mobile phone activity or satellite images, instead of ground-truth outcome measurements. Common practice predicts the economic outcome from the RSV, using an auxiliary sample of labeled RSVs, and then uses such predictions as the outcome in the experiment. We prove that this approach leads to biased estimates of treatment effects when the RSV is a post-outcome variable. We nonparametrically identify the treatment effect, using an assumption that reflects the logic of recent empirical research: the conditional distribution of the RSV remains stable across both samples, given the outcome and treatment. Our results do not require researchers to know or consistently estimate the relationship between the RSV, outcome, and treatment, which is typically mis-specified with unstructured data. We form a representation of the RSV for downstream causal inference by predicting the outcome and predicting the treatment, with better predictions leading to more precise causal estimates. We re-evaluate the efficacy of a large-scale public program in India, showing that the program's measured effects on local consumption and poverty can be replicated using satellite
Provably Adaptive Average Reward Reinforcement Learning for Metric Spaces
Oct 25, 2024We study infinite-horizon average-reward reinforcement learning (RL) for Lipschitz MDPs and develop an algorithm ZoRL that discretizes the state-action space adaptively and zooms into promising regions of the state-action space. We show that its regret can be bounded as $\mathcal{\tilde{O}}\big(T^{1 - d_{\text{eff.}}^{-1}}\big)$, where $d_{\text{eff.}} = 2d_\mathcal{S} + d_z + 3$, $d_\mathcal{S}$ is the dimension of the state space, and $d_z$ is the zooming dimension. $d_z$ is a problem-dependent quantity, which allows us to conclude that if MDP is benign, then its regret will be small. We note that the existing notion of zooming dimension for average reward RL is defined in terms of policy coverings, and hence it can be huge when the policy class is rich even though the underlying MDP is simple, so that the regret upper bound is nearly $O(T)$. The zooming dimension proposed in the current work is bounded above by $d$, the dimension of the state-action space, and hence is truly adaptive, i.e., shows how to capture adaptivity gains for infinite-horizon average-reward RL. ZoRL outperforms other state-of-the-art algorithms in experiments; thereby demonstrating the gains arising due to adaptivity.
Latent Representation Learning for Multimodal Brain Activity Translation
Sep 27, 2024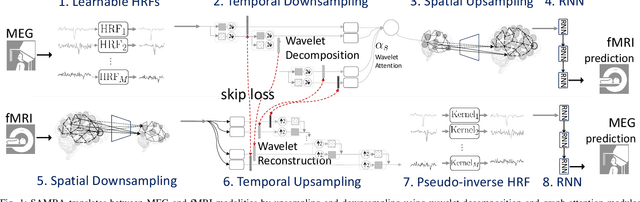
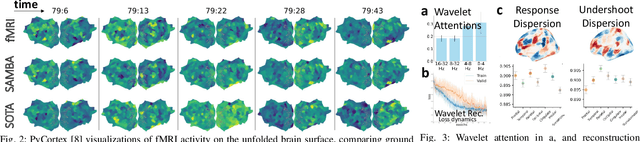
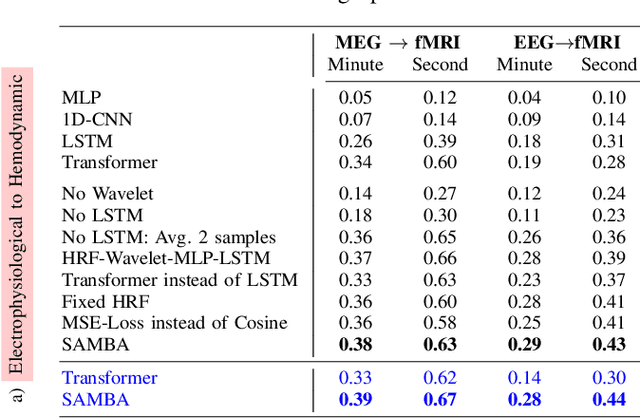
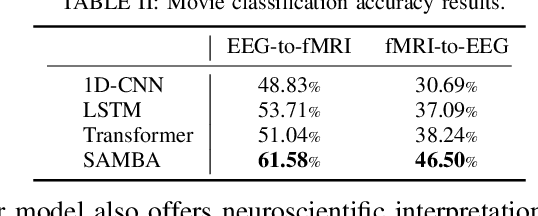
Neuroscience employs diverse neuroimaging techniques, each offering distinct insights into brain activity, from electrophysiological recordings such as EEG, which have high temporal resolution, to hemodynamic modalities such as fMRI, which have increased spatial precision. However, integrating these heterogeneous data sources remains a challenge, which limits a comprehensive understanding of brain function. We present the Spatiotemporal Alignment of Multimodal Brain Activity (SAMBA) framework, which bridges the spatial and temporal resolution gaps across modalities by learning a unified latent space free of modality-specific biases. SAMBA introduces a novel attention-based wavelet decomposition for spectral filtering of electrophysiological recordings, graph attention networks to model functional connectivity between functional brain units, and recurrent layers to capture temporal autocorrelations in brain signal. We show that the training of SAMBA, aside from achieving translation, also learns a rich representation of brain information processing. We showcase this classify external stimuli driving brain activity from the representation learned in hidden layers of SAMBA, paving the way for broad downstream applications in neuroscience research and clinical contexts.