 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Probability Bounds for SGD under the Polyak-Lojasiewicz Condition with Markovian Noise
Mar 15, 2026We present the first uniform-in-time high-probability bound for SGD under the PL condition, where the gradient noise contains both Markovian and martingale difference components. This significantly broadens the scope of finite-time guarantees, as the PL condition arises in many machine learning and deep learning models while Markovian noise naturally arises in decentralized optimization and online system identification problems. We further allow the magnitude of noise to grow with the function value, enabling the analysis of many practical sampling strategies. In addition to the high-probability guarantee, we establish a matching $1/k$ decay rate for the expected suboptimality. Our proof technique relies on the Poisson equation to handle the Markovian noise and a probabilistic induction argument to address the lack of almost-sure bounds on the objective. Finally, we demonstrate the applicability of our framework by analyzing three practical optimization problems: token-based decentralized linear regression, supervised learning with subsampling for privacy amplification, and online system identification.
Provably Adaptive Average Reward Reinforcement Learning for Metric Spaces
Oct 25, 2024We study infinite-horizon average-reward reinforcement learning (RL) for Lipschitz MDPs and develop an algorithm ZoRL that discretizes the state-action space adaptively and zooms into promising regions of the state-action space. We show that its regret can be bounded as $\mathcal{\tilde{O}}\big(T^{1 - d_{\text{eff.}}^{-1}}\big)$, where $d_{\text{eff.}} = 2d_\mathcal{S} + d_z + 3$, $d_\mathcal{S}$ is the dimension of the state space, and $d_z$ is the zooming dimension. $d_z$ is a problem-dependent quantity, which allows us to conclude that if MDP is benign, then its regret will be small. We note that the existing notion of zooming dimension for average reward RL is defined in terms of policy coverings, and hence it can be huge when the policy class is rich even though the underlying MDP is simple, so that the regret upper bound is nearly $O(T)$. The zooming dimension proposed in the current work is bounded above by $d$, the dimension of the state-action space, and hence is truly adaptive, i.e., shows how to capture adaptivity gains for infinite-horizon average-reward RL. ZoRL outperforms other state-of-the-art algorithms in experiments; thereby demonstrating the gains arising due to adaptivity.
Adaptive Discretization-based Non-Episodic Reinforcement Learning in Metric Spaces
May 29, 2024We study non-episodic Reinforcement Learning for Lipschitz MDPs in which state-action space is a metric space, and the transition kernel and rewards are Lipschitz functions. We develop computationally efficient UCB-based algorithm, $\textit{ZoRL-}\epsilon$ that adaptively discretizes the state-action space and show that their regret as compared with $\epsilon$-optimal policy is bounded as $\mathcal{O}(\epsilon^{-(2 d_\mathcal{S} + d^\epsilon_z + 1)}\log{(T)})$, where $d^\epsilon_z$ is the $\epsilon$-zooming dimension. In contrast, if one uses the vanilla $\textit{UCRL-}2$ on a fixed discretization of the MDP, the regret w.r.t. a $\epsilon$-optimal policy scales as $\mathcal{O}(\epsilon^{-(2 d_\mathcal{S} + d + 1)}\log{(T)})$ so that the adaptivity gains are huge when $d^\epsilon_z \ll d$. Note that the absolute regret of any 'uniformly good' algorithm for a large family of continuous MDPs asymptotically scales as at least $\Omega(\log{(T)})$. Though adaptive discretization has been shown to yield $\mathcal{\tilde{O}}(H^{2.5}K^\frac{d_z + 1}{d_z + 2})$ regret in episodic RL, an attempt to extend this to the non-episodic case by employing constant duration episodes whose duration increases with $T$, is futile since $d_z \to d$ as $T \to \infty$. The current work shows how to obtain adaptivity gains for non-episodic RL. The theoretical results are supported by simulations on two systems where the performance of $\textit{ZoRL-}\epsilon$ is compared with that of '$\textit{UCRL-C}$,' the fixed discretization-based extension of $\textit{UCRL-}2$ for systems with continuous state-action spaces.
Finite Time Regret Bounds for Minimum Variance Control of Autoregressive Systems with Exogenous Inputs
May 26, 2023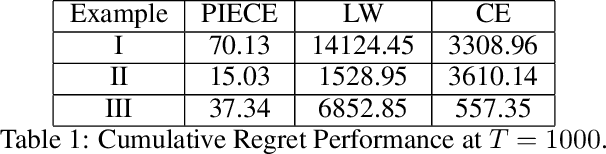

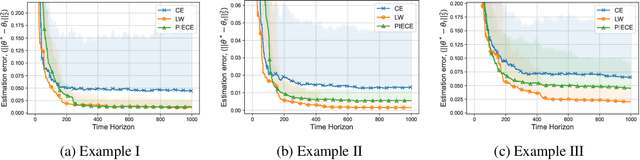

Minimum variance controllers have been employed in a wide-range of industrial applications. A key challenge experienced by many adaptive controllers is their poor empirical performance in the initial stages of learning. In this paper, we address the problem of initializing them so that they provide acceptable transients, and also provide an accompanying finite-time regret analysis, for adaptive minimum variance control of an auto-regressive system with exogenous inputs (ARX). Following [3], we consider a modified version of the Certainty Equivalence (CE) adaptive controller, which we call PIECE, that utilizes probing inputs for exploration. We show that it has a $C \log T$ bound on the regret after $T$ time-steps for bounded noise, and $C\log^2 T$ in the case of sub-Gaussian noise. The simulation results demonstrate the advantage of PIECE over the algorithm proposed in [3] as well as the standard Certainty Equivalence controller especially in the initial learning phase. To the best of our knowledge, this is the first work that provides finite-time regret bounds for an adaptive minimum variance controller.