 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Behavioral Test Cases For Natural Language Processing Using Clustering and Prompting
Paper and Code
Jul 31, 2024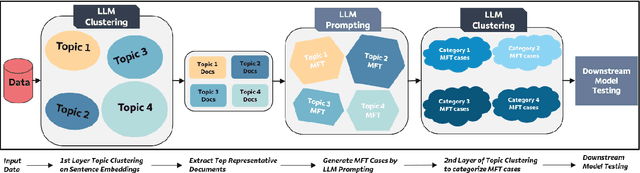
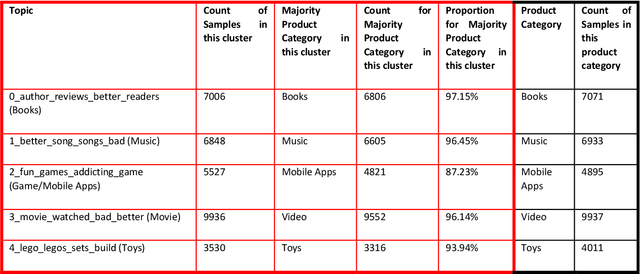
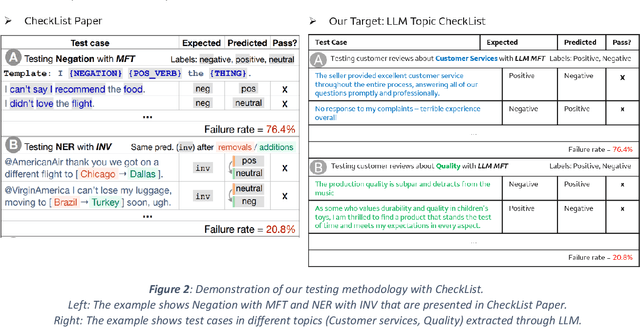
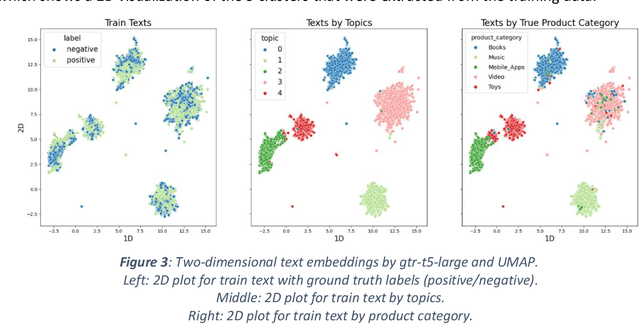
Recent work in behavioral testing for natural language processing (NLP) models, such as Checklist, is inspired by related paradigms in software engineering testing. They allow evaluation of general linguistic capabilities and domain understanding, hence can help evaluate conceptual soundness and identify model weaknesses. However, a major challenge is the creation of test cases. The current packages rely on semi-automated approach using manual development which requires domain expertise and can be time consuming. This paper introduces an automated approach to develop test cases by exploiting the power of large language models and statistical techniques. It clusters the text representations to carefully construct meaningful groups and then apply prompting techniques to automatically generate Minimal Functionality Tests (MFT). The well-known Amazon Reviews corpus is used to demonstrate our approach. We analyze the behavioral test profiles across four different classification algorithms and discuss the limitations and strengths of those models.