 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Risk Management for Generative AI In Financial Institutions
Mar 19, 2025The success of OpenAI's ChatGPT in 2023 has spurred financial enterprises into exploring Generative AI applications to reduce costs or drive revenue within different lines of businesses in the Financial Industry. While these applications offer strong potential for efficiencies, they introduce new model risks, primarily hallucinations and toxicity. As highly regulated entities, financial enterprises (primarily large US banks) are obligated to enhance their model risk framework with additional testing and controls to ensure safe deployment of such applications. This paper outlines the key aspects for model risk management of generative AI model with a special emphasis on additional practices required in model validation.
Human-Calibrated Automated Testing and Validation of Generative Language Models
Nov 25, 2024This paper introduces a comprehensive framework for the evaluation and validation of generative language models (GLMs), with a focus on Retrieval-Augmented Generation (RAG) systems deployed in high-stakes domains such as banking. GLM evaluation is challenging due to open-ended outputs and subjective quality assessments. Leveraging the structured nature of RAG systems, where generated responses are grounded in a predefined document collection, we propose the Human-Calibrated Automated Testing (HCAT) framework. HCAT integrates a) automated test generation using stratified sampling, b) embedding-based metrics for explainable assessment of functionality, risk and safety attributes, and c) a two-stage calibration approach that aligns machine-generated evaluations with human judgments through probability calibration and conformal prediction. In addition, the framework includes robustness testing to evaluate model performance against adversarial, out-of-distribution, and varied input conditions, as well as targeted weakness identification using marginal and bivariate analysis to pinpoint specific areas for improvement. This human-calibrated, multi-layered evaluation framework offers a scalable, transparent, and interpretable approach to GLM assessment, providing a practical and reliable solution for deploying GLMs in applications where accuracy, transparency, and regulatory compliance are paramount.
Downstream bias mitigation is all you need
Aug 01, 2024The advent of transformer-based architectures and large language models (LLMs) have significantly advanced the performance of natural language processing (NLP) models. Since these LLMs are trained on huge corpuses of data from the web and other sources, there has been a major concern about harmful prejudices that may potentially be transferred from the data. In many applications, these pre-trained LLMs are fine-tuned on task specific datasets, which can further contribute to biases. This paper studies the extent of biases absorbed by LLMs during pre-training as well as task-specific behaviour after fine-tuning. We found that controlled interventions on pre-trained LLMs, prior to fine-tuning, have minimal effect on lowering biases in classifiers. However, the biases present in domain-specific datasets play a much bigger role, and hence mitigating them at this stage has a bigger impact. While pre-training does matter, but after the model has been pre-trained, even slight changes to co-occurrence rates in the fine-tuning dataset has a significant effect on the bias of the model.
Automatic Generation of Behavioral Test Cases For Natural Language Processing Using Clustering and Prompting
Jul 31, 2024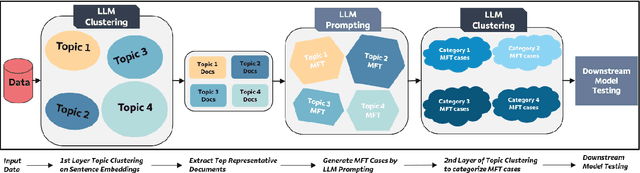
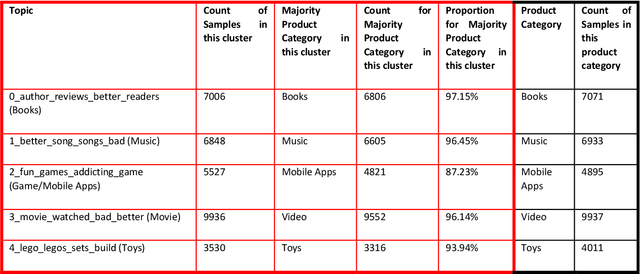
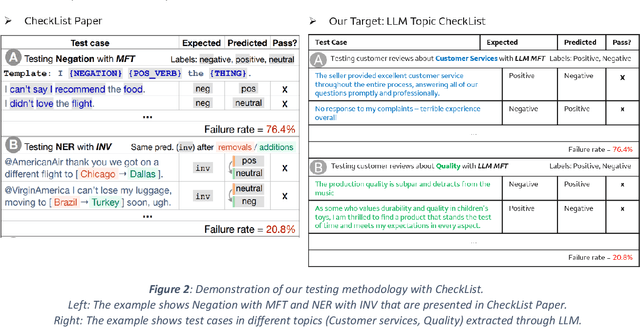
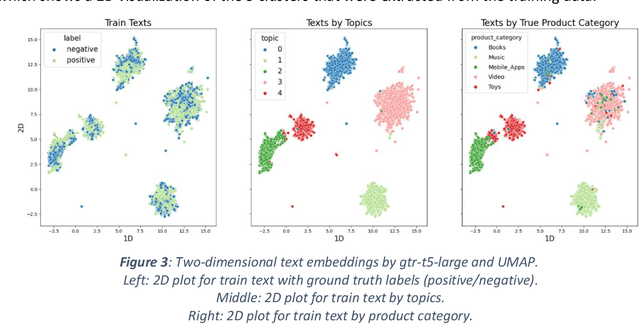
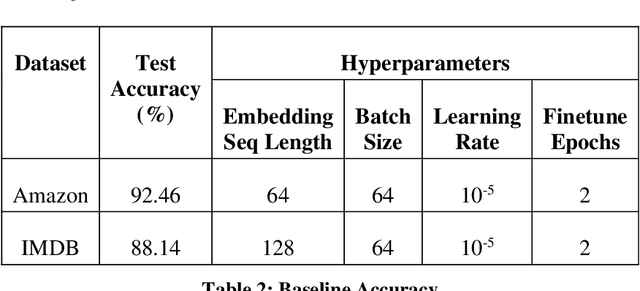
Recent work in behavioral testing for natural language processing (NLP) models, such as Checklist, is inspired by related paradigms in software engineering testing. They allow evaluation of general linguistic capabilities and domain understanding, hence can help evaluate conceptual soundness and identify model weaknesses. However, a major challenge is the creation of test cases. The current packages rely on semi-automated approach using manual development which requires domain expertise and can be time consuming. This paper introduces an automated approach to develop test cases by exploiting the power of large language models and statistical techniques. It clusters the text representations to carefully construct meaningful groups and then apply prompting techniques to automatically generate Minimal Functionality Tests (MFT). The well-known Amazon Reviews corpus is used to demonstrate our approach. We analyze the behavioral test profiles across four different classification algorithms and discuss the limitations and strengths of those models.
Document Automation Architectures: Updated Survey in Light of Large Language Models
Aug 18, 2023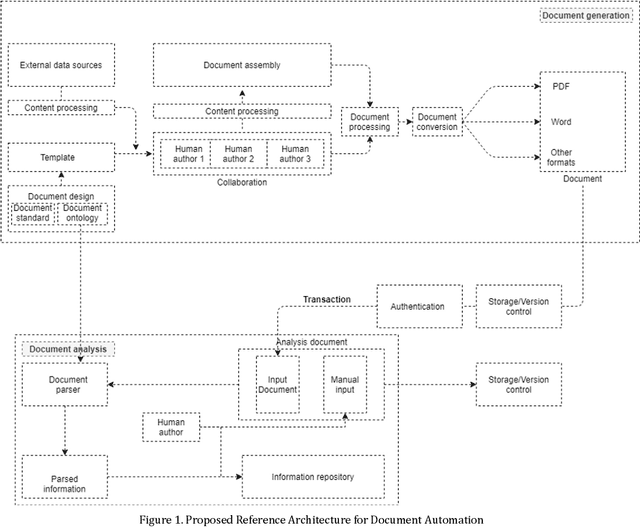
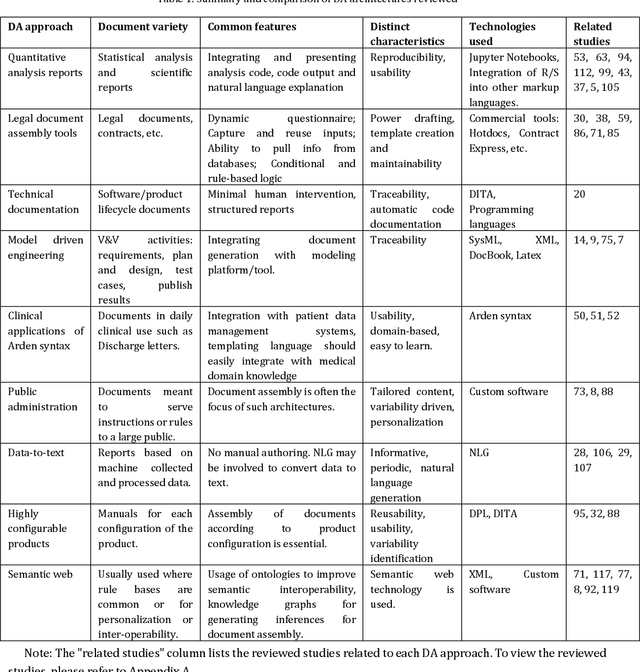
This paper surveys the current state of the art in document automation (DA). The objective of DA is to reduce the manual effort during the generation of documents by automatically creating and integrating input from different sources and assembling documents conforming to defined templates. There have been reviews of commercial solutions of DA, particularly in the legal domain, but to date there has been no comprehensive review of the academic research on DA architectures and technologies. The current survey of DA reviews the academic literature and provides a clearer definition and characterization of DA and its features, identifies state-of-the-art DA architectures and technologies in academic research, and provides ideas that can lead to new research opportunities within the DA field in light of recent advances in generative AI and large language models.
Understanding Metrics for Paraphrasing
May 26, 2022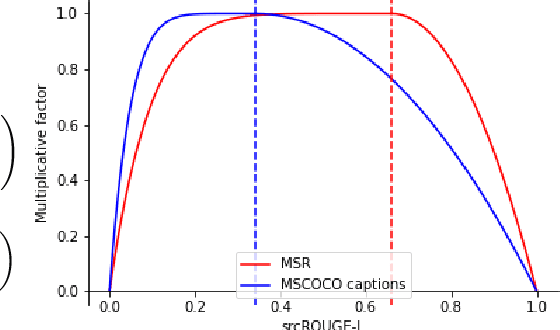
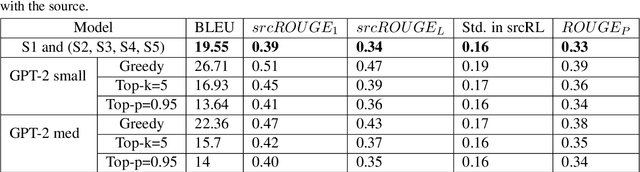


Paraphrase generation is a difficult problem. This is not only because of the limitations in text generation capabilities but also due that to the lack of a proper definition of what qualifies as a paraphrase and corresponding metrics to measure how good it is. Metrics for evaluation of paraphrasing quality is an on going research problem. Most of the existing metrics in use having been borrowed from other tasks do not capture the complete essence of a good paraphrase, and often fail at borderline-cases. In this work, we propose a novel metric $ROUGE_P$ to measure the quality of paraphrases along the dimensions of adequacy, novelty and fluency. We also provide empirical evidence to show that the current natural language generation metrics are insufficient to measure these desired properties of a good paraphrase. We look at paraphrase model fine-tuning and generation from the lens of metrics to gain a deeper understanding of what it takes to generate and evaluate a good paraphrase.
Pruning Attention Heads of Transformer Models Using A* Search: A Novel Approach to Compress Big NLP Architectures
Nov 17, 2021


Recent years have seen a growing adoption of Transformer models such as BERT in Natural Language Processing and even in Computer Vision. However, due to their size, there has been limited adoption of such models within resource-constrained computing environments. This paper proposes novel pruning algorithm to compress transformer models by eliminating redundant Attention Heads. We apply the A* search algorithm to obtain a pruned model with strict accuracy guarantees. Our results indicate that the method could eliminate as much as 40% of the attention heads in the BERT transformer model with no loss in accuracy.
Document Automation Architectures and Technologies: A Survey
Sep 23, 2021

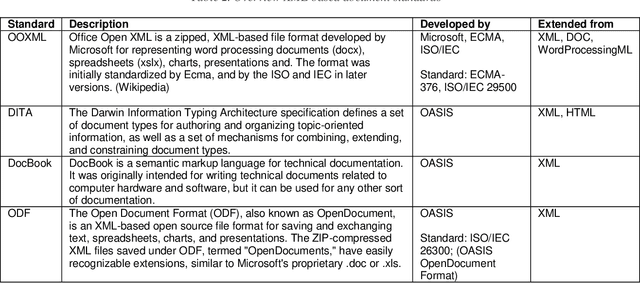
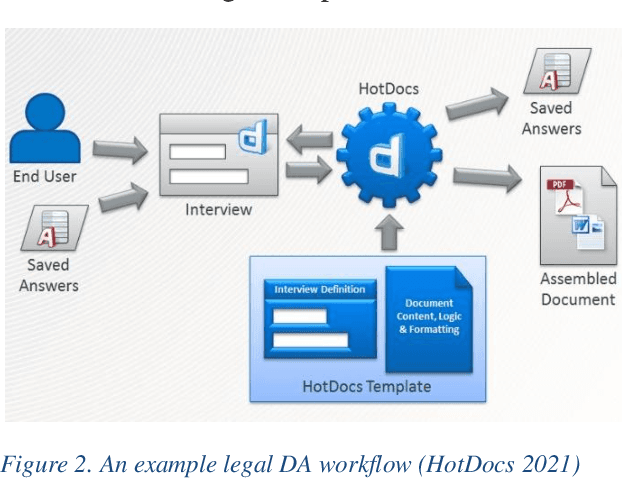
This paper surveys the current state of the art in document automation (DA). The objective of DA is to reduce the manual effort during the generation of documents by automatically integrating input from different sources and assembling documents conforming to defined templates. There have been reviews of commercial solutions of DA, particularly in the legal domain, but to date there has been no comprehensive review of the academic research on DA architectures and technologies. The current survey of DA reviews the academic literature and provides a clearer definition and characterization of DA and its features, identifies state-of-the-art DA architectures and technologies in academic research, and provides ideas that can lead to new research opportunities within the DA field in light of recent advances in artificial intelligence and deep neural networks.
Self-interpretable Convolutional Neural Networks for Text Classification
May 18, 2021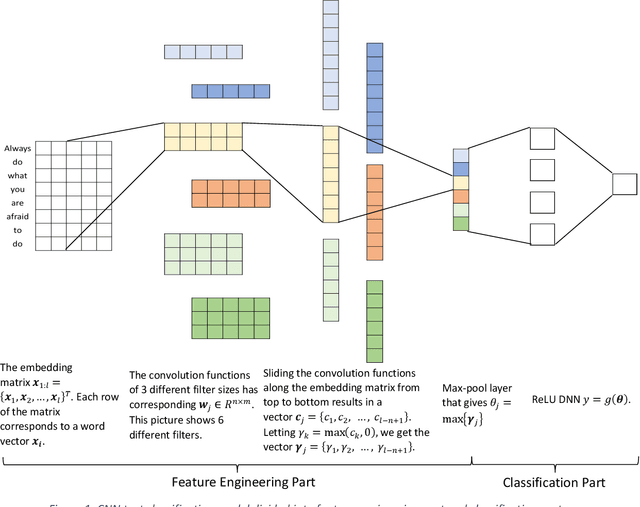
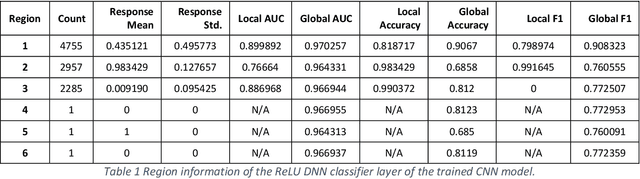
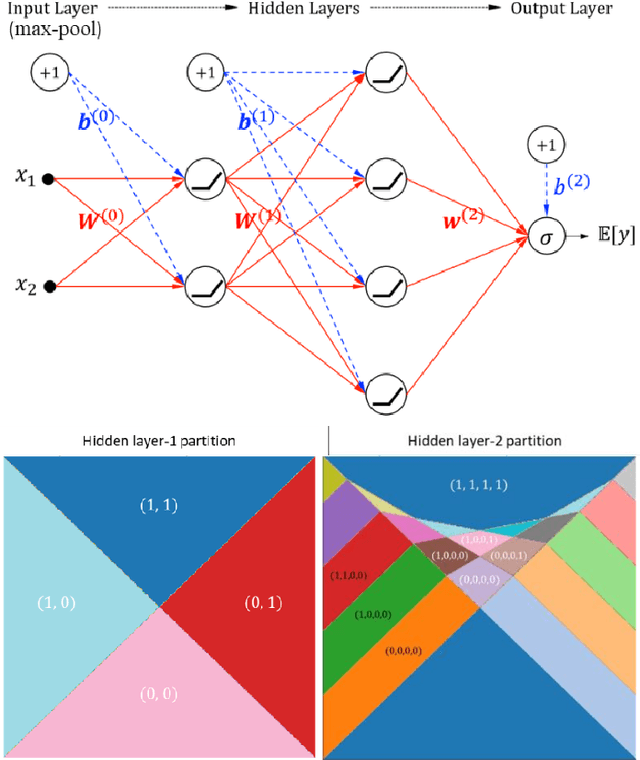

Deep learning models for natural language processing (NLP) are inherently complex and often viewed as black box in nature. This paper develops an approach for interpreting convolutional neural networks for text classification problems by exploiting the local-linear models inherent in ReLU-DNNs. The CNN model combines the word embedding through convolutional layers, filters them using max-pooling, and optimizes using a ReLU-DNN for classification. To get an overall self-interpretable model, the system of local linear models from the ReLU DNN are mapped back through the max-pool filter to the appropriate n-grams. Our results on experimental datasets demonstrate that our proposed technique produce parsimonious models that are self-interpretable and have comparable performance with respect to a more complex CNN model. We also study the impact of the complexity of the convolutional layers and the classification layers on the model performance.
Robustness Tests of NLP Machine Learning Models: Search and Semantically Replace
Apr 20, 2021
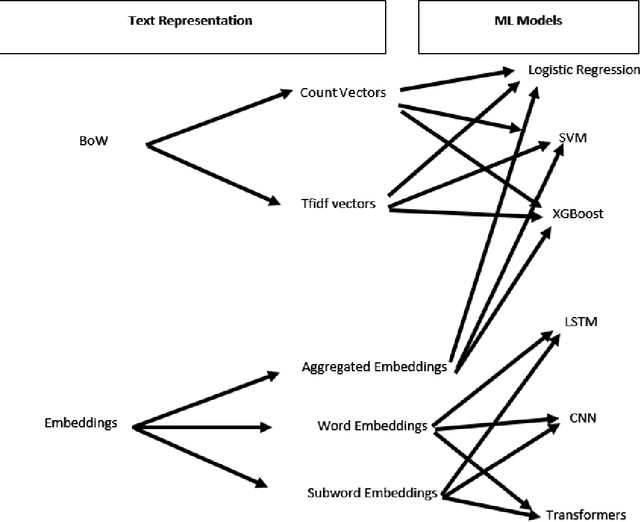
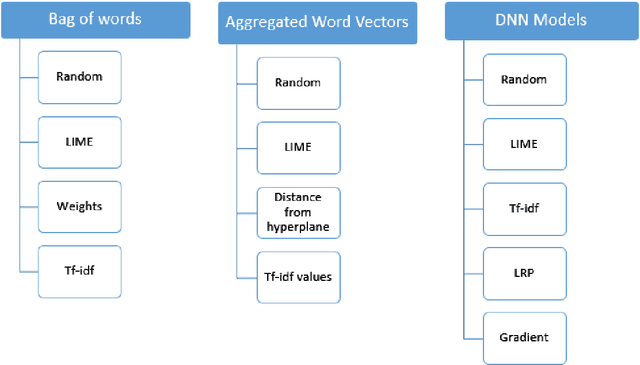
This paper proposes a strategy to assess the robustness of different machine learning models that involve natural language processing (NLP). The overall approach relies upon a Search and Semantically Replace strategy that consists of two steps: (1) Search, which identifies important parts in the text; (2) Semantically Replace, which finds replacements for the important parts, and constrains the replaced tokens with semantically similar words. We introduce different types of Search and Semantically Replace methods designed specifically for particular types of machine learning models. We also investigate the effectiveness of this strategy and provide a general framework to assess a variety of machine learning models. Finally, an empirical comparison is provided of robustness performance among three different model types, each with a different text representation.