 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Metrics for Paraphrasing
Paper and Code
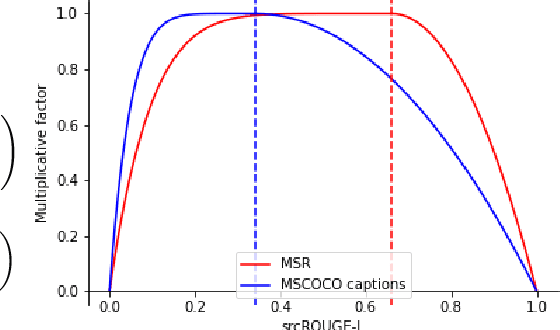
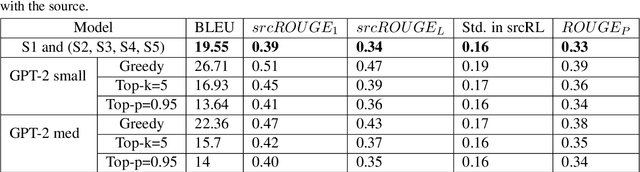


Paraphrase generation is a difficult problem. This is not only because of the limitations in text generation capabilities but also due that to the lack of a proper definition of what qualifies as a paraphrase and corresponding metrics to measure how good it is. Metrics for evaluation of paraphrasing quality is an on going research problem. Most of the existing metrics in use having been borrowed from other tasks do not capture the complete essence of a good paraphrase, and often fail at borderline-cases. In this work, we propose a novel metric $ROUGE_P$ to measure the quality of paraphrases along the dimensions of adequacy, novelty and fluency. We also provide empirical evidence to show that the current natural language generation metrics are insufficient to measure these desired properties of a good paraphrase. We look at paraphrase model fine-tuning and generation from the lens of metrics to gain a deeper understanding of what it takes to generate and evaluate a good paraphrase.