 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Enhancement for Cloud-Based Few-Shot Learning
May 10, 2022
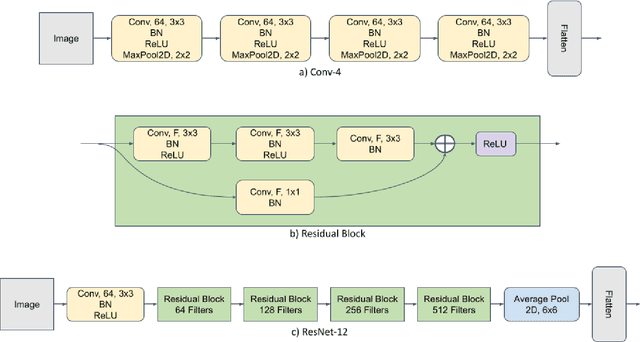
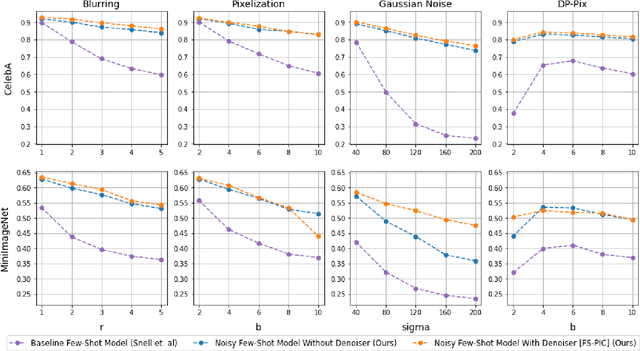
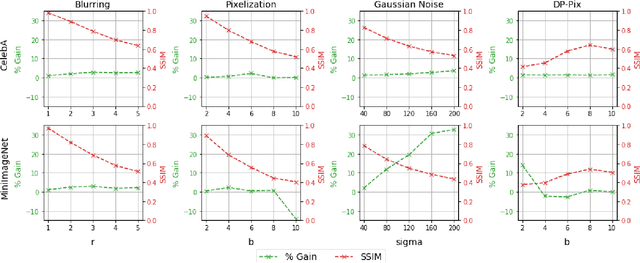
Requiring less data for accurate models, few-shot learning has shown robustness and generality in many application domains. However, deploying few-shot models in untrusted environments may inflict privacy concerns, e.g., attacks or adversaries that may breach the privacy of user-supplied data. This paper studies the privacy enhancement for the few-shot learning in an untrusted environment, e.g., the cloud, by establishing a novel privacy-preserved embedding space that preserves the privacy of data and maintains the accuracy of the model. We examine the impact of various image privacy methods such as blurring, pixelization, Gaussian noise, and differentially private pixelization (DP-Pix) on few-shot image classification and propose a method that learns privacy-preserved representation through the joint loss. The empirical results show how privacy-performance trade-off can be negotiated for privacy-enhanced few-shot learning.
Learning from Few Examples: A Summary of Approaches to Few-Shot Learning
Mar 07, 2022



Few-Shot Learning refers to the problem of learning the underlying pattern in the data just from a few training samples. Requiring a large number of data samples, many deep learning solutions suffer from data hunger and extensively high computation time and resources. Furthermore, data is often not available due to not only the nature of the problem or privacy concerns but also the cost of data preparation. Data collection, preprocessing, and labeling are strenuous human tasks. Therefore, few-shot learning that could drastically reduce the turnaround time of building machine learning applications emerges as a low-cost solution. This survey paper comprises a representative list of recently proposed few-shot learning algorithms. Given the learning dynamics and characteristics, the approaches to few-shot learning problems are discussed in the perspectives of meta-learning, transfer learning, and hybrid approaches (i.e., different variations of the few-shot learning problem).
Pruning Attention Heads of Transformer Models Using A* Search: A Novel Approach to Compress Big NLP Architectures
Nov 17, 2021


Recent years have seen a growing adoption of Transformer models such as BERT in Natural Language Processing and even in Computer Vision. However, due to their size, there has been limited adoption of such models within resource-constrained computing environments. This paper proposes novel pruning algorithm to compress transformer models by eliminating redundant Attention Heads. We apply the A* search algorithm to obtain a pruned model with strict accuracy guarantees. Our results indicate that the method could eliminate as much as 40% of the attention heads in the BERT transformer model with no loss in accuracy.
Transformation of Node to Knowledge Graph Embeddings for Faster Link Prediction in Social Networks
Nov 17, 2021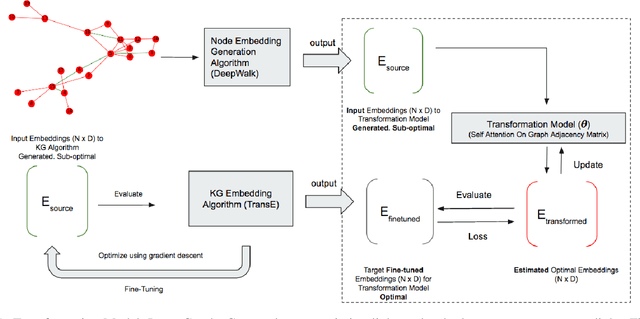


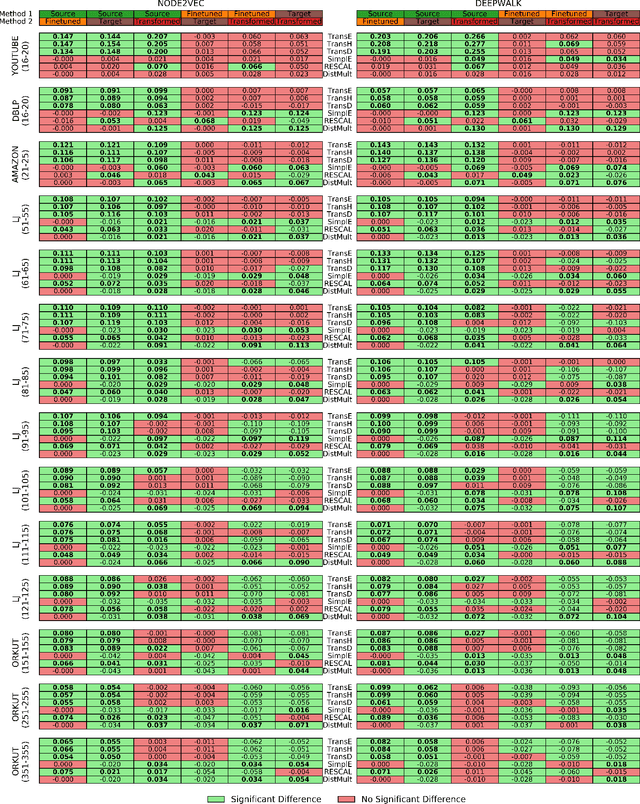
Recent advances in neural networks have solved common graph problems such as link prediction, node classification, node clustering, node recommendation by developing embeddings of entities and relations into vector spaces. Graph embeddings encode the structural information present in a graph. The encoded embeddings then can be used to predict the missing links in a graph. However, obtaining the optimal embeddings for a graph can be a computationally challenging task specially in an embedded system. Two techniques which we focus on in this work are 1) node embeddings from random walk based methods and 2) knowledge graph embeddings. Random walk based embeddings are computationally inexpensive to obtain but are sub-optimal whereas knowledge graph embeddings perform better but are computationally expensive. In this work, we investigate a transformation model which converts node embeddings obtained from random walk based methods to embeddings obtained from knowledge graph methods directly without an increase in the computational cost. Extensive experimentation shows that the proposed transformation model can be used for solving link prediction in real-time.
Few-Shot Keyword Spotting With Prototypical Networks
Jul 25, 2020



Recognizing a particular command or a keyword, keyword spotting has been widely used in many voice interfaces such as Amazon's Alexa and Google Home. In order to recognize a set of keywords, most of the recent deep learning based approaches use a neural network trained with a large number of samples to identify certain pre-defined keywords. This restricts the system from recognizing new, user-defined keywords. Therefore, we first formulate this problem as a few-shot keyword spotting and approach it using metric learning. To enable this research, we also synthesize and publish a Few-shot Google Speech Commands dataset. We then propose a solution to the few-shot keyword spotting problem using temporal and dilated convolutions on prototypical networks. Our comparative experimental results demonstrate keyword spotting of new keywords using just a small number of samples.