 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-resolution Interpretation and Diagnostics Tool for Natural Language Classifiers
Mar 06, 2023Developing explainability methods for Natural Language Processing (NLP) models is a challenging task, for two main reasons. First, the high dimensionality of the data (large number of tokens) results in low coverage and in turn small contributions for the top tokens, compared to the overall model performance. Second, owing to their textual nature, the input variables, after appropriate transformations, are effectively binary (presence or absence of a token in an observation), making the input-output relationship difficult to understand. Common NLP interpretation techniques do not have flexibility in resolution, because they usually operate at word-level and provide fully local (message level) or fully global (over all messages) summaries. The goal of this paper is to create more flexible model explainability summaries by segments of observation or clusters of words that are semantically related to each other. In addition, we introduce a root cause analysis method for NLP models, by analyzing representative False Positive and False Negative examples from different segments. At the end, we illustrate, using a Yelp review data set with three segments (Restaurant, Hotel, and Beauty), that exploiting group/cluster structures in words and/or messages can aid in the interpretation of decisions made by NLP models and can be utilized to assess the model's sensitivity or bias towards gender, syntax, and word meanings.
Robustness Tests of NLP Machine Learning Models: Search and Semantically Replace
Apr 20, 2021
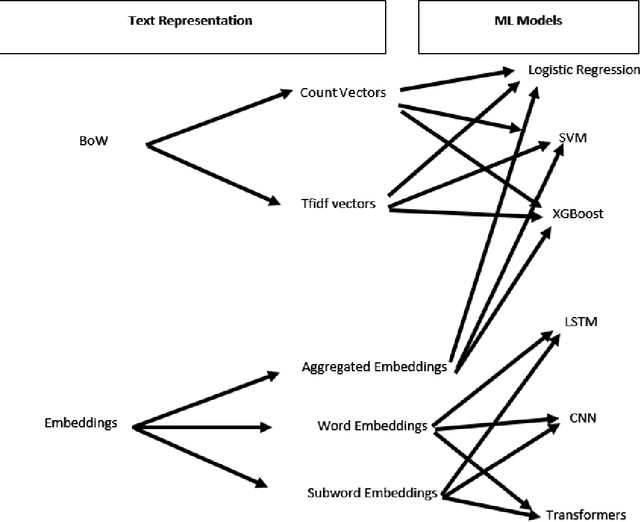
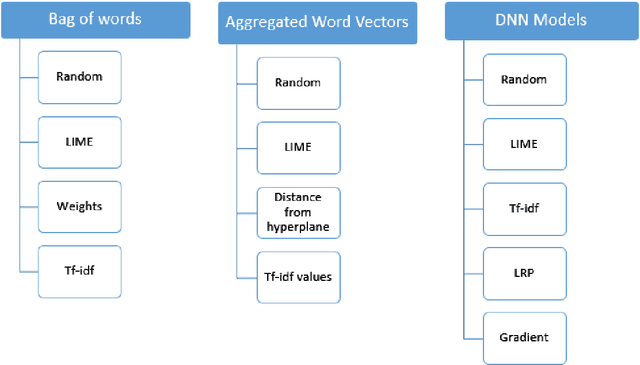
This paper proposes a strategy to assess the robustness of different machine learning models that involve natural language processing (NLP). The overall approach relies upon a Search and Semantically Replace strategy that consists of two steps: (1) Search, which identifies important parts in the text; (2) Semantically Replace, which finds replacements for the important parts, and constrains the replaced tokens with semantically similar words. We introduce different types of Search and Semantically Replace methods designed specifically for particular types of machine learning models. We also investigate the effectiveness of this strategy and provide a general framework to assess a variety of machine learning models. Finally, an empirical comparison is provided of robustness performance among three different model types, each with a different text representation.