 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Risk Management for Generative AI In Financial Institutions
Mar 19, 2025The success of OpenAI's ChatGPT in 2023 has spurred financial enterprises into exploring Generative AI applications to reduce costs or drive revenue within different lines of businesses in the Financial Industry. While these applications offer strong potential for efficiencies, they introduce new model risks, primarily hallucinations and toxicity. As highly regulated entities, financial enterprises (primarily large US banks) are obligated to enhance their model risk framework with additional testing and controls to ensure safe deployment of such applications. This paper outlines the key aspects for model risk management of generative AI model with a special emphasis on additional practices required in model validation.
Towards a framework on tabular synthetic data generation: a minimalist approach: theory, use cases, and limitations
Nov 19, 2024We propose and study a minimalist approach towards synthetic tabular data generation. The model consists of a minimalistic unsupervised SparsePCA encoder (with contingent clustering step or log transformation to handle nonlinearity) and XGboost decoder which is SOTA for structured data regression and classification tasks. We study and contrast the methodologies with (variational) autoencoders in several toy low dimensional scenarios to derive necessary intuitions. The framework is applied to high dimensional simulated credit scoring data which parallels real-life financial applications. We applied the method to robustness testing to demonstrate practical use cases. The case study result suggests that the method provides an alternative to raw and quantile perturbation for model robustness testing. We show that the method is simplistic, guarantees interpretability all the way through, does not require extra tuning and provide unique benefits.
Assessing Robustness of Machine Learning Models using Covariate Perturbations
Aug 02, 2024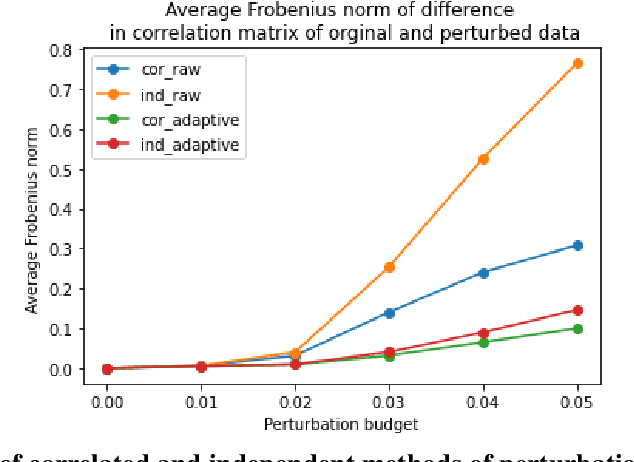
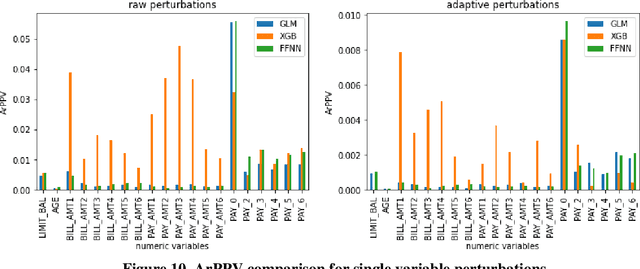
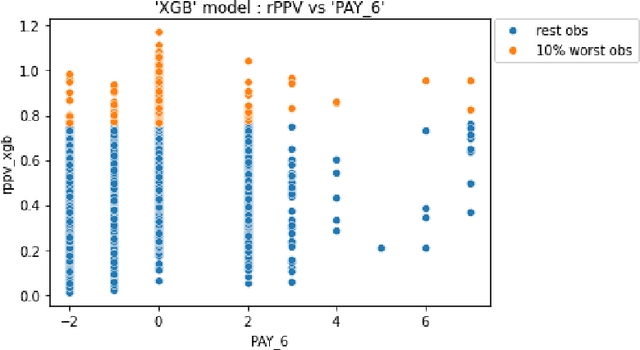
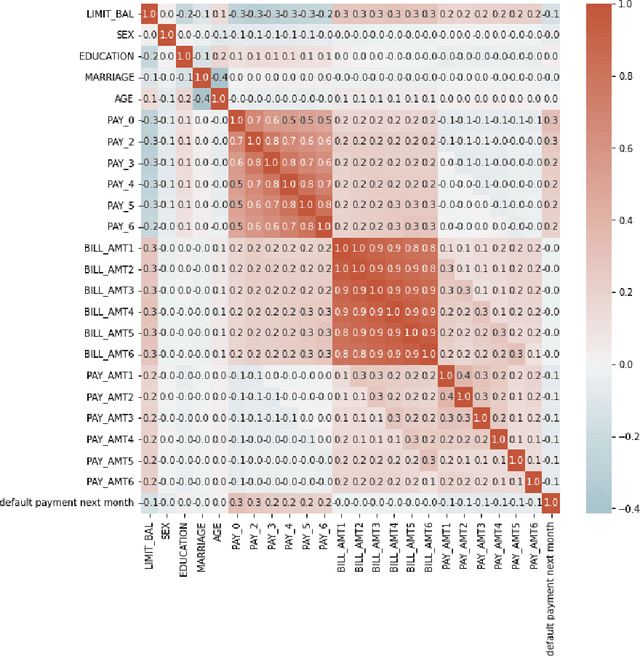
As machine learning models become increasingly prevalent in critical decision-making models and systems in fields like finance, healthcare, etc., ensuring their robustness against adversarial attacks and changes in the input data is paramount, especially in cases where models potentially overfit. This paper proposes a comprehensive framework for assessing the robustness of machine learning models through covariate perturbation techniques. We explore various perturbation strategies to assess robustness and examine their impact on model predictions, including separate strategies for numeric and non-numeric variables, summaries of perturbations to assess and compare model robustness across different scenarios, and local robustness diagnosis to identify any regions in the data where a model is particularly unstable. Through empirical studies on real world dataset, we demonstrate the effectiveness of our approach in comparing robustness across models, identifying the instabilities in the model, and enhancing model robustness.
Behavior of Hyper-Parameters for Selected Machine Learning Algorithms: An Empirical Investigation
Nov 15, 2022



Hyper-parameters (HPs) are an important part of machine learning (ML) model development and can greatly influence performance. This paper studies their behavior for three algorithms: Extreme Gradient Boosting (XGB), Random Forest (RF), and Feedforward Neural Network (FFNN) with structured data. Our empirical investigation examines the qualitative behavior of model performance as the HPs vary, quantifies the importance of each HP for different ML algorithms, and stability of the performance near the optimal region. Based on the findings, we propose a set of guidelines for efficient HP tuning by reducing the search space.