 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a framework on tabular synthetic data generation: a minimalist approach: theory, use cases, and limitations
Nov 19, 2024We propose and study a minimalist approach towards synthetic tabular data generation. The model consists of a minimalistic unsupervised SparsePCA encoder (with contingent clustering step or log transformation to handle nonlinearity) and XGboost decoder which is SOTA for structured data regression and classification tasks. We study and contrast the methodologies with (variational) autoencoders in several toy low dimensional scenarios to derive necessary intuitions. The framework is applied to high dimensional simulated credit scoring data which parallels real-life financial applications. We applied the method to robustness testing to demonstrate practical use cases. The case study result suggests that the method provides an alternative to raw and quantile perturbation for model robustness testing. We show that the method is simplistic, guarantees interpretability all the way through, does not require extra tuning and provide unique benefits.
Assessing Robustness of Machine Learning Models using Covariate Perturbations
Aug 02, 2024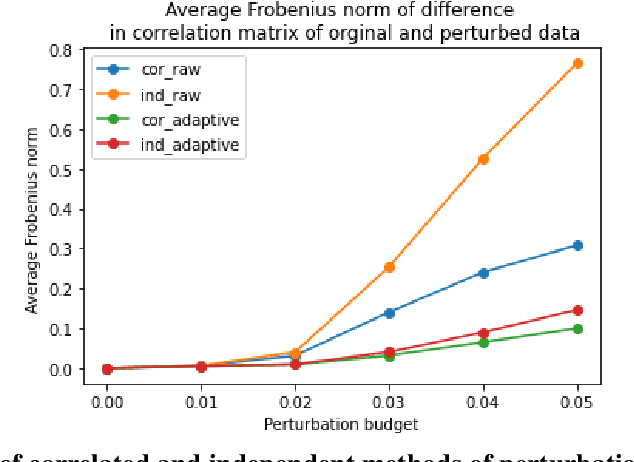
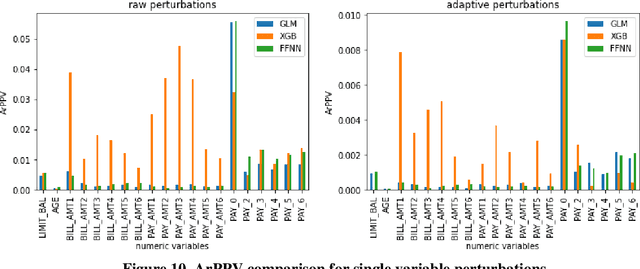
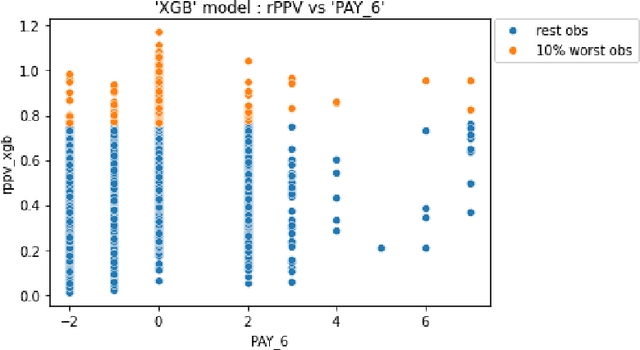
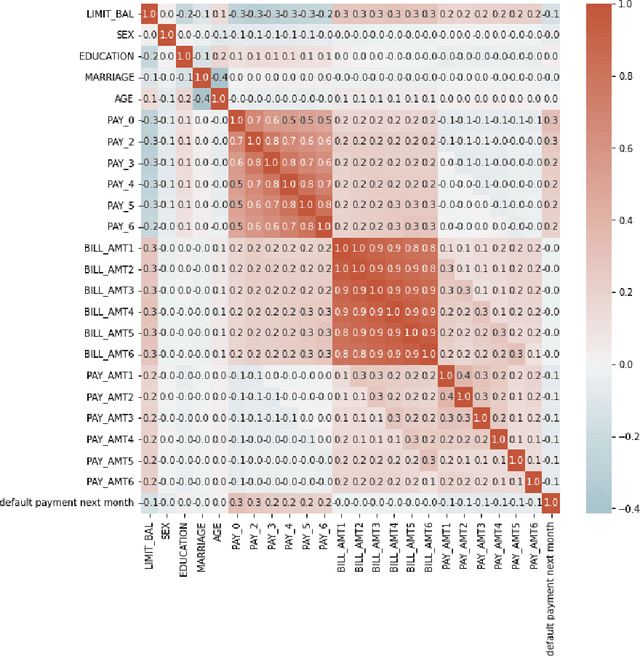
As machine learning models become increasingly prevalent in critical decision-making models and systems in fields like finance, healthcare, etc., ensuring their robustness against adversarial attacks and changes in the input data is paramount, especially in cases where models potentially overfit. This paper proposes a comprehensive framework for assessing the robustness of machine learning models through covariate perturbation techniques. We explore various perturbation strategies to assess robustness and examine their impact on model predictions, including separate strategies for numeric and non-numeric variables, summaries of perturbations to assess and compare model robustness across different scenarios, and local robustness diagnosis to identify any regions in the data where a model is particularly unstable. Through empirical studies on real world dataset, we demonstrate the effectiveness of our approach in comparing robustness across models, identifying the instabilities in the model, and enhancing model robustness.
Behavior of Hyper-Parameters for Selected Machine Learning Algorithms: An Empirical Investigation
Nov 15, 2022



Hyper-parameters (HPs) are an important part of machine learning (ML) model development and can greatly influence performance. This paper studies their behavior for three algorithms: Extreme Gradient Boosting (XGB), Random Forest (RF), and Feedforward Neural Network (FFNN) with structured data. Our empirical investigation examines the qualitative behavior of model performance as the HPs vary, quantifies the importance of each HP for different ML algorithms, and stability of the performance near the optimal region. Based on the findings, we propose a set of guidelines for efficient HP tuning by reducing the search space.
Quantifying Inherent Randomness in Machine Learning Algorithms
Jun 24, 2022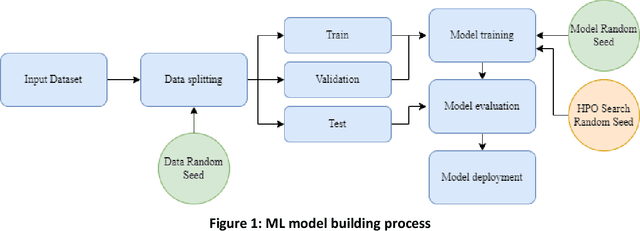
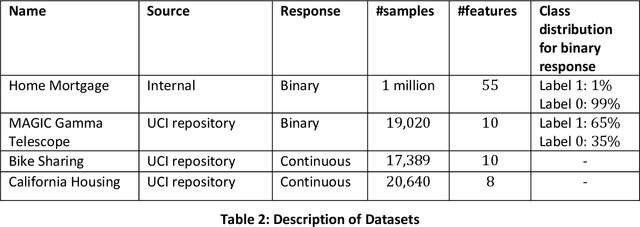
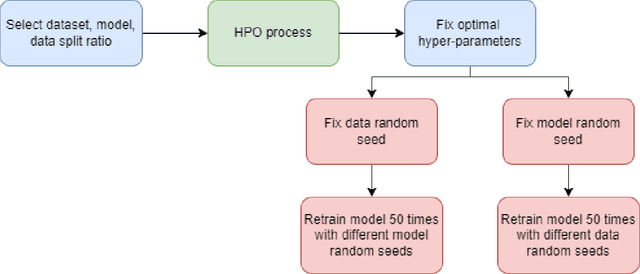
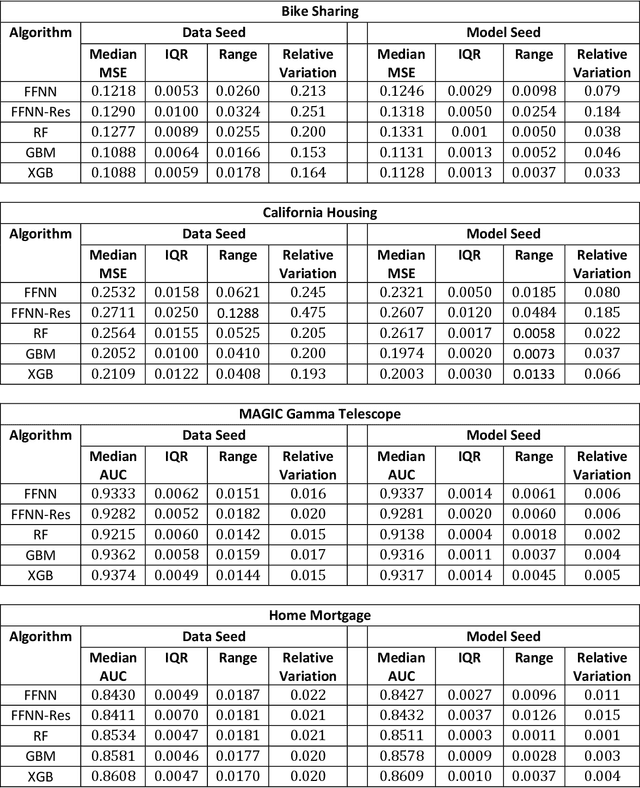
Most machine learning (ML) algorithms have several stochastic elements, and their performances are affected by these sources of randomness. This paper uses an empirical study to systematically examine the effects of two sources: randomness in model training and randomness in the partitioning of a dataset into training and test subsets. We quantify and compare the magnitude of the variation in predictive performance for the following ML algorithms: Random Forests (RFs), Gradient Boosting Machines (GBMs), and Feedforward Neural Networks (FFNNs). Among the different algorithms, randomness in model training causes larger variation for FFNNs compared to tree-based methods. This is to be expected as FFNNs have more stochastic elements that are part of their model initialization and training. We also found that random splitting of datasets leads to higher variation compared to the inherent randomness from model training. The variation from data splitting can be a major issue if the original dataset has considerable heterogeneity. Keywords: Model Training, Reproducibility, Variation
Interpretable Feature Engineering for Time Series Predictors using Attention Networks
May 23, 2022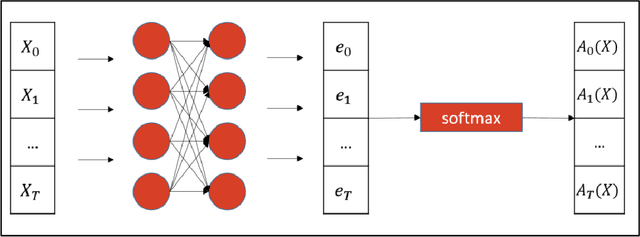

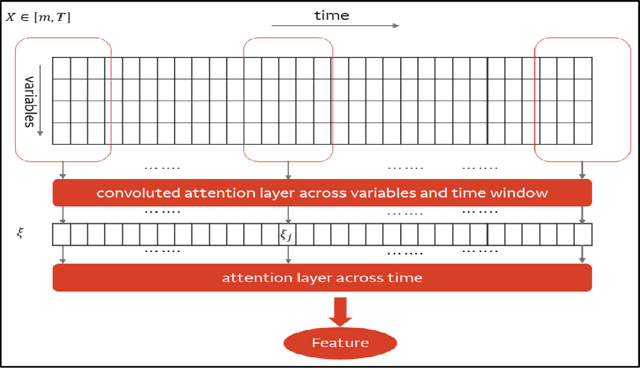

Regression problems with time-series predictors are common in banking and many other areas of application. In this paper, we use multi-head attention networks to develop interpretable features and use them to achieve good predictive performance. The customized attention layer explicitly uses multiplicative interactions and builds feature-engineering heads that capture temporal dynamics in a parsimonious manner. Convolutional layers are used to combine multivariate time series. We also discuss methods for handling static covariates in the modeling process. Visualization and explanation tools are used to interpret the results and explain the relationship between the inputs and the extracted features. Both simulation and real dataset are used to illustrate the usefulness of the methodology. Keyword: Attention heads, Deep neural networks, Interpretable feature engineering
Traversing the Local Polytopes of ReLU Neural Networks: A Unified Approach for Network Verification
Nov 17, 2021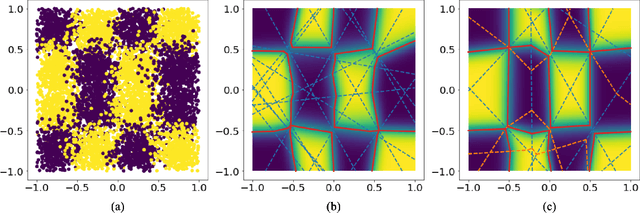
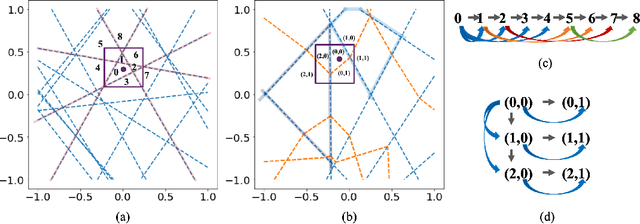
Although neural networks (NNs) with ReLU activation functions have found success in a wide range of applications, their adoption in risk-sensitive settings has been limited by the concerns on robustness and interpretability. Previous works to examine robustness and to improve interpretability partially exploited the piecewise linear function form of ReLU NNs. In this paper, we explore the unique topological structure that ReLU NNs create in the input space, identifying the adjacency among the partitioned local polytopes and developing a traversing algorithm based on this adjacency. Our polytope traversing algorithm can be adapted to verify a wide range of network properties related to robustness and interpretability, providing an unified approach to examine the network behavior. As the traversing algorithm explicitly visits all local polytopes, it returns a clear and full picture of the network behavior within the traversed region. The time and space complexity of the traversing algorithm is determined by the number of a ReLU NN's partitioning hyperplanes passing through the traversing region.
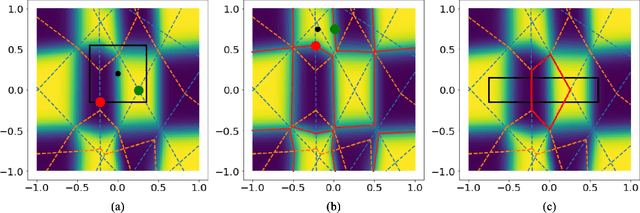
Supervised Linear Dimension-Reduction Methods: Review, Extensions, and Comparisons
Sep 09, 2021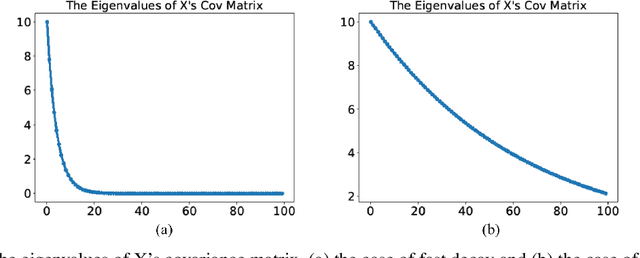
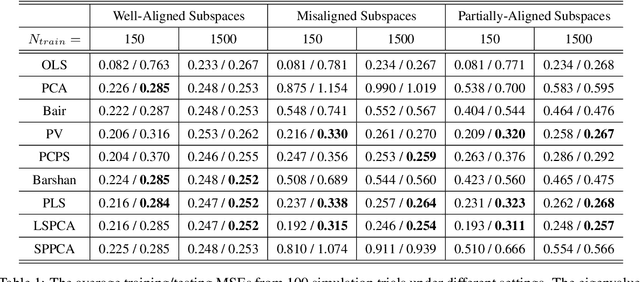
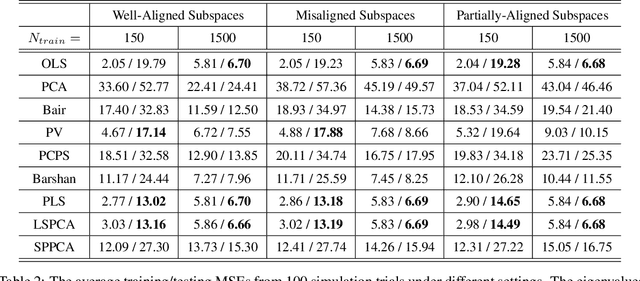
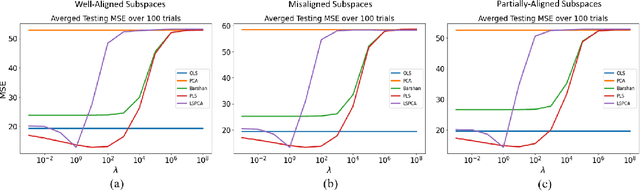
Principal component analysis (PCA) is a well-known linear dimension-reduction method that has been widely used in data analysis and modeling. It is an unsupervised learning technique that identifies a suitable linear subspace for the input variable that contains maximal variation and preserves as much information as possible. PCA has also been used in prediction models where the original, high-dimensional space of predictors is reduced to a smaller, more manageable, set before conducting regression analysis. However, this approach does not incorporate information in the response during the dimension-reduction stage and hence can have poor predictive performance. To address this concern, several supervised linear dimension-reduction techniques have been proposed in the literature. This paper reviews selected techniques, extends some of them, and compares their performance through simulations. Two of these techniques, partial least squares (PLS) and least-squares PCA (LSPCA), consistently outperform the others in this study.
Supervised Machine Learning Techniques: An Overview with Applications to Banking
Jul 28, 2020
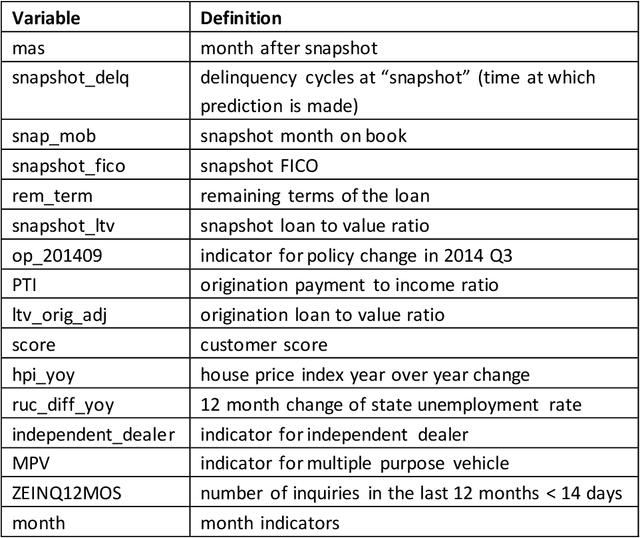
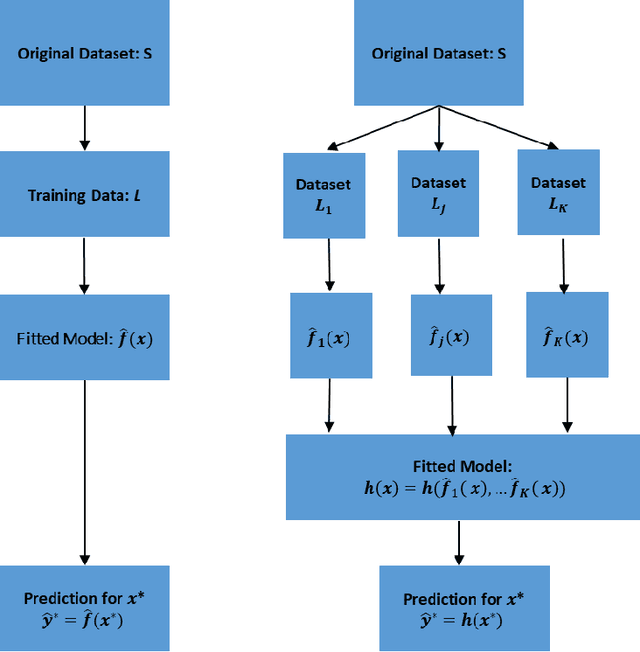
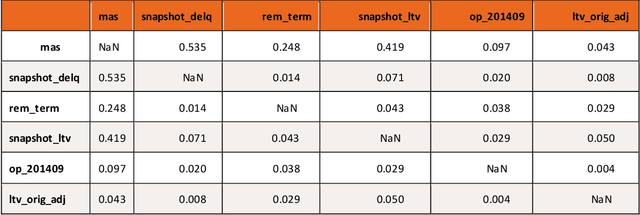
This article provides an overview of Supervised Machine Learning (SML) with a focus on applications to banking. The SML techniques covered include Bagging (Random Forest or RF), Boosting (Gradient Boosting Machine or GBM) and Neural Networks (NNs). We begin with an introduction to ML tasks and techniques. This is followed by a description of: i) tree-based ensemble algorithms including Bagging with RF and Boosting with GBMs, ii) Feedforward NNs, iii) a discussion of hyper-parameter optimization techniques, and iv) machine learning interpretability. The paper concludes with a comparison of the features of different ML algorithms. Examples taken from credit risk modeling in banking are used throughout the paper to illustrate the techniques and interpret the results of the algorithms.
Adaptive Explainable Neural Networks (AxNNs)
Apr 05, 2020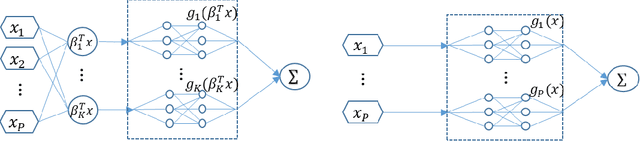
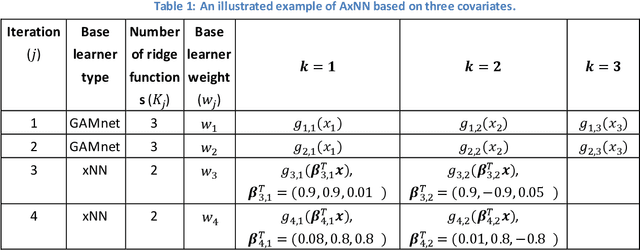
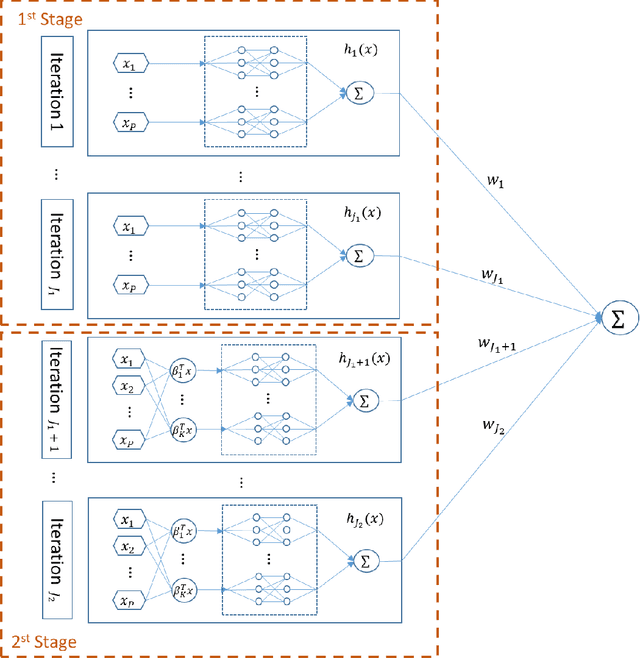
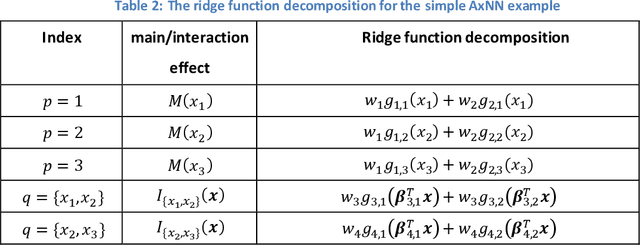
While machine learning techniques have been successfully applied in several fields, the black-box nature of the models presents challenges for interpreting and explaining the results. We develop a new framework called Adaptive Explainable Neural Networks (AxNN) for achieving the dual goals of good predictive performance and model interpretability. For predictive performance, we build a structured neural network made up of ensembles of generalized additive model networks and additive index models (through explainable neural networks) using a two-stage process. This can be done using either a boosting or a stacking ensemble. For interpretability, we show how to decompose the results of AxNN into main effects and higher-order interaction effects. The computations are inherited from Google's open source tool AdaNet and can be efficiently accelerated by training with distributed computing. The results are illustrated on simulated and real datasets.
Model Interpretation: A Unified Derivative-based Framework for Nonparametric Regression and Supervised Machine Learning
Sep 08, 2018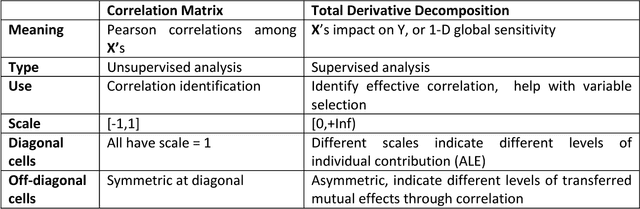
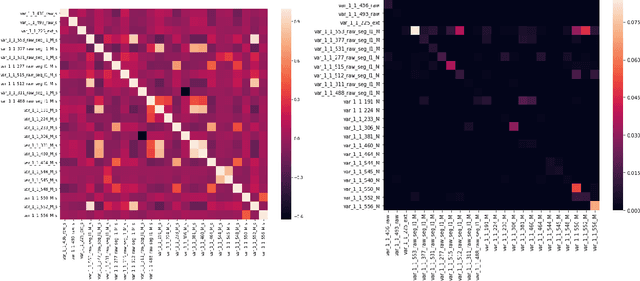
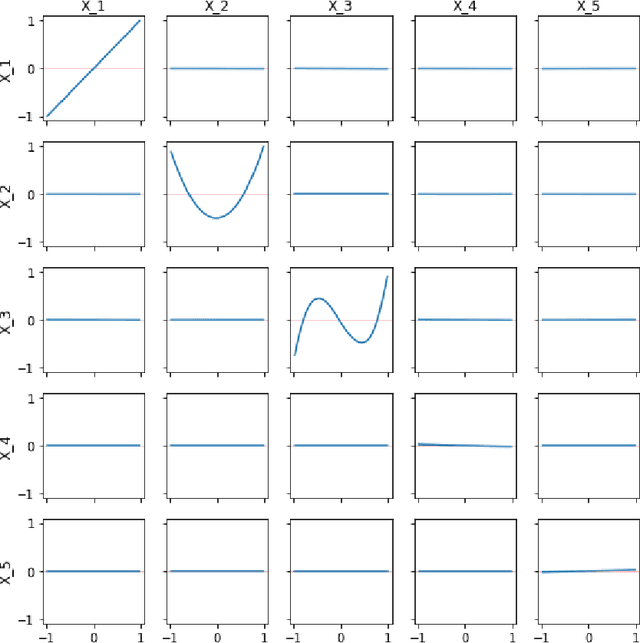
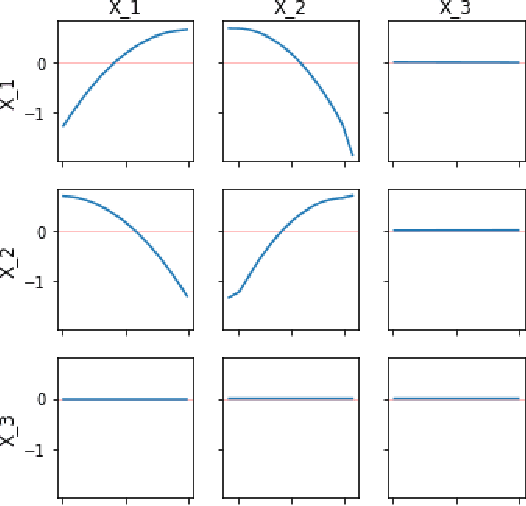
Interpreting a nonparametric regression model with many predictors is known to be a challenging problem. There has been renewed interest in this topic due to the extensive use of machine learning algorithms and the difficulty in understanding and explaining their input-output relationships. This paper develops a unified framework using a derivative-based approach for existing tools in the literature, including the partial-dependence plots, marginal plots and accumulated effects plots. It proposes a new interpretation technique called the accumulated total derivative effects plot and demonstrates how its components can be used to develop extensive insights in complex regression models with correlated predictors. The techniques are illustrated through simulation results.