 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Inherent Randomness in Machine Learning Algorithms
Jun 24, 2022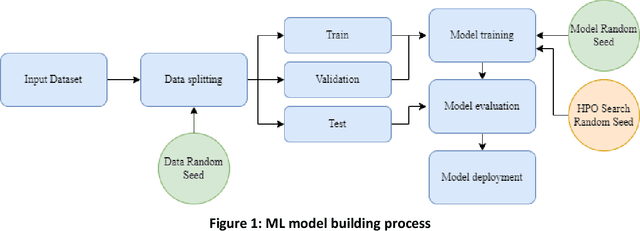
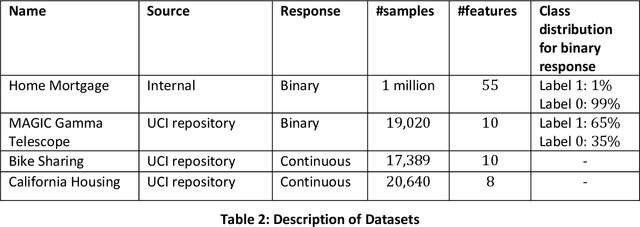
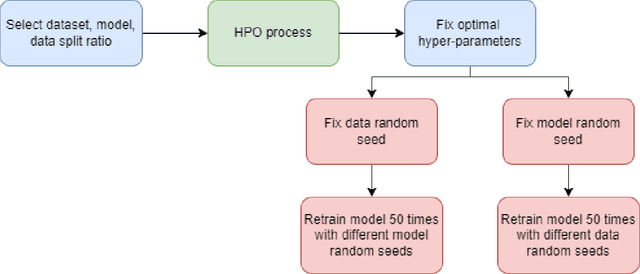
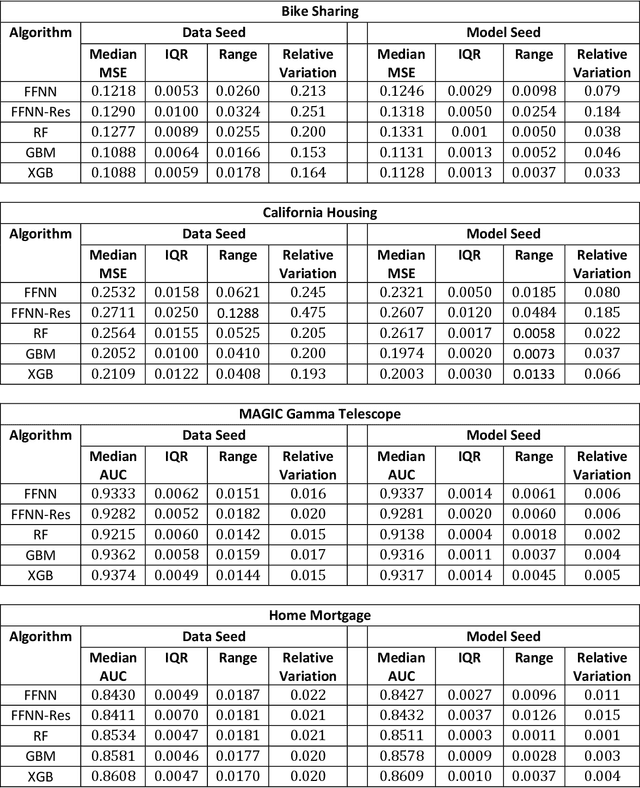
Most machine learning (ML) algorithms have several stochastic elements, and their performances are affected by these sources of randomness. This paper uses an empirical study to systematically examine the effects of two sources: randomness in model training and randomness in the partitioning of a dataset into training and test subsets. We quantify and compare the magnitude of the variation in predictive performance for the following ML algorithms: Random Forests (RFs), Gradient Boosting Machines (GBMs), and Feedforward Neural Networks (FFNNs). Among the different algorithms, randomness in model training causes larger variation for FFNNs compared to tree-based methods. This is to be expected as FFNNs have more stochastic elements that are part of their model initialization and training. We also found that random splitting of datasets leads to higher variation compared to the inherent randomness from model training. The variation from data splitting can be a major issue if the original dataset has considerable heterogeneity. Keywords: Model Training, Reproducibility, Variation