 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-based Classification: Connecting Similarity Learning to Binary Classification
Paper and Code
Jun 11, 2020
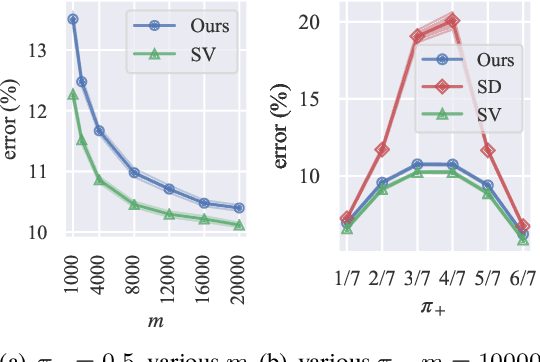
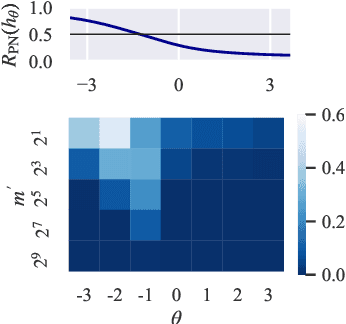

In real-world classification problems, pairwise supervision (i.e., a pair of patterns with a binary label indicating whether they belong to the same class or not) can often be obtained at a lower cost than ordinary class labels. Similarity learning is a general framework to utilize such pairwise supervision to elicit useful representations by inferring the relationship between two data points, which encompasses various important preprocessing tasks such as metric learning, kernel learning, graph embedding, and contrastive representation learning. Although elicited representations are expected to perform well in downstream tasks such as classification, little theoretical insight has been given in the literature so far. In this paper, we reveal that a specific formulation of similarity learning is strongly related to the objective of binary classification, which spurs us to learn a binary classifier without ordinary class labels---by fitting the product of real-valued prediction functions of pairwise patterns to their similarity. Our formulation of similarity learning does not only generalize many existing ones, but also admits an excess risk bound showing an explicit connection to classification. Finally, we empirically demonstrate the practical usefulness of the proposed method on benchmark datasets.