 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARDA: Automatic Relational Data Augmentation for Machine Learning
Mar 21, 2020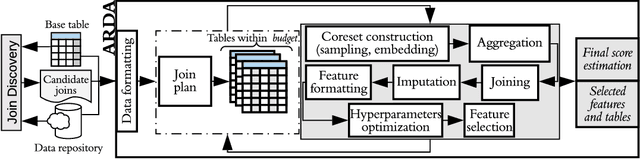
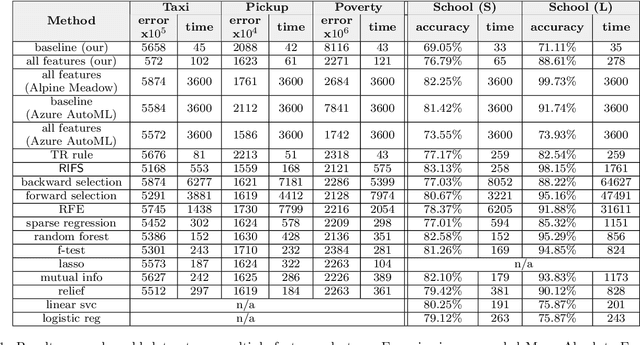
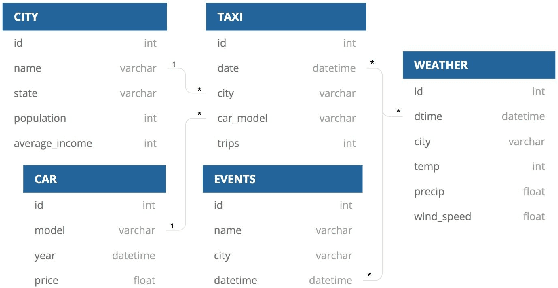
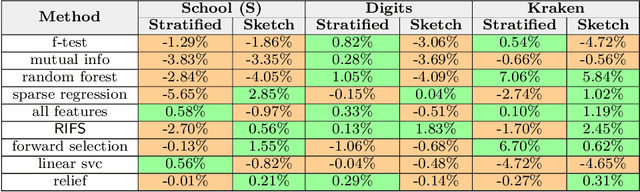
Automatic machine learning (\AML) is a family of techniques to automate the process of training predictive models, aiming to both improve performance and make machine learning more accessible. While many recent works have focused on aspects of the machine learning pipeline like model selection, hyperparameter tuning, and feature selection, relatively few works have focused on automatic data augmentation. Automatic data augmentation involves finding new features relevant to the user's predictive task with minimal ``human-in-the-loop'' involvement. We present \system, an end-to-end system that takes as input a dataset and a data repository, and outputs an augmented data set such that training a predictive model on this augmented dataset results in improved performance. Our system has two distinct components: (1) a framework to search and join data with the input data, based on various attributes of the input, and (2) an efficient feature selection algorithm that prunes out noisy or irrelevant features from the resulting join. We perform an extensive empirical evaluation of different system components and benchmark our feature selection algorithm on real-world datasets.
Sherlock: A Deep Learning Approach to Semantic Data Type Detection
May 25, 2019
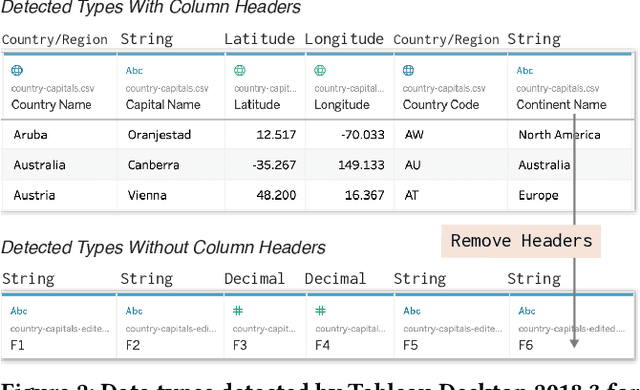
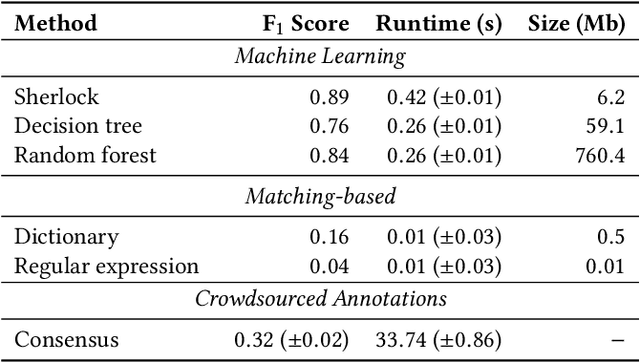

Correctly detecting the semantic type of data columns is crucial for data science tasks such as automated data cleaning, schema matching, and data discovery. Existing data preparation and analysis systems rely on dictionary lookups and regular expression matching to detect semantic types. However, these matching-based approaches often are not robust to dirty data and only detect a limited number of types. We introduce Sherlock, a multi-input deep neural network for detecting semantic types. We train Sherlock on $686,765$ data columns retrieved from the VizNet corpus by matching $78$ semantic types from DBpedia to column headers. We characterize each matched column with $1,588$ features describing the statistical properties, character distributions, word embeddings, and paragraph vectors of column values. Sherlock achieves a support-weighted F$_1$ score of $0.89$, exceeding that of machine learning baselines, dictionary and regular expression benchmarks, and the consensus of crowdsourced annotations.
VizNet: Towards A Large-Scale Visualization Learning and Benchmarking Repository
May 12, 2019
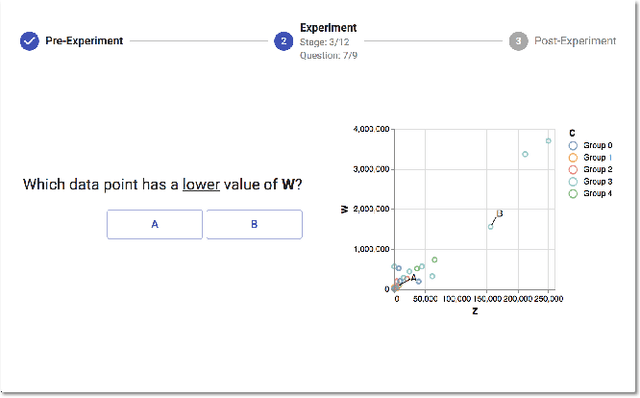

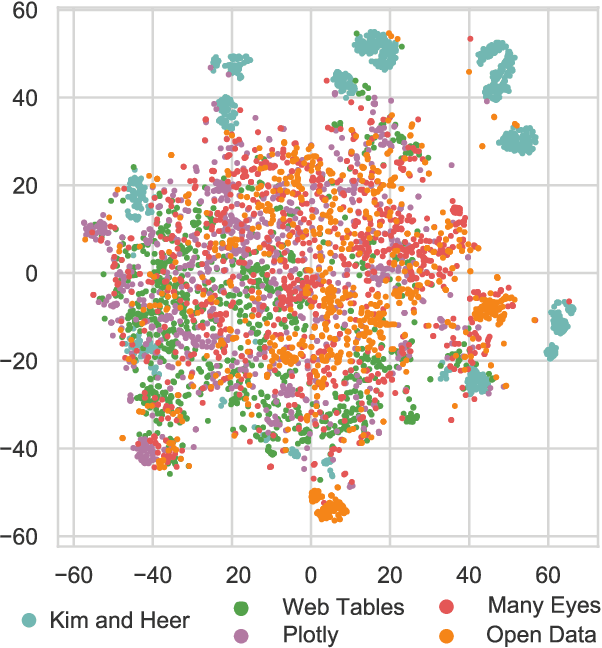
Researchers currently rely on ad hoc datasets to train automated visualization tools and evaluate the effectiveness of visualization designs. These exemplars often lack the characteristics of real-world datasets, and their one-off nature makes it difficult to compare different techniques. In this paper, we present VizNet: a large-scale corpus of over 31 million datasets compiled from open data repositories and online visualization galleries. On average, these datasets comprise 17 records over 3 dimensions and across the corpus, we find 51% of the dimensions record categorical data, 44% quantitative, and only 5% temporal. VizNet provides the necessary common baseline for comparing visualization design techniques, and developing benchmark models and algorithms for automating visual analysis. To demonstrate VizNet's utility as a platform for conducting online crowdsourced experiments at scale, we replicate a prior study assessing the influence of user task and data distribution on visual encoding effectiveness, and extend it by considering an additional task: outlier detection. To contend with running such studies at scale, we demonstrate how a metric of perceptual effectiveness can be learned from experimental results, and show its predictive power across test datasets.