 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Measuring Calibration in Deep Learning
Apr 02, 2019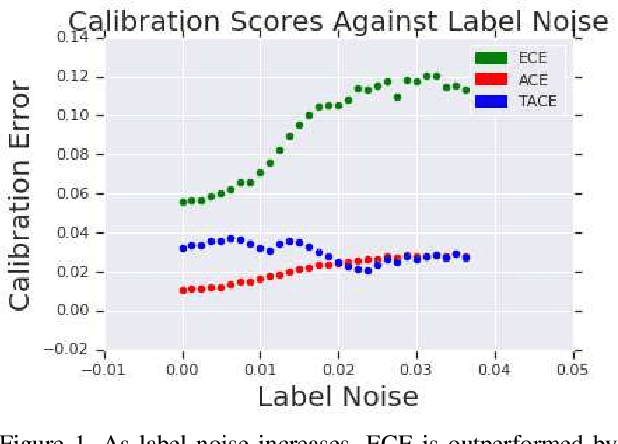
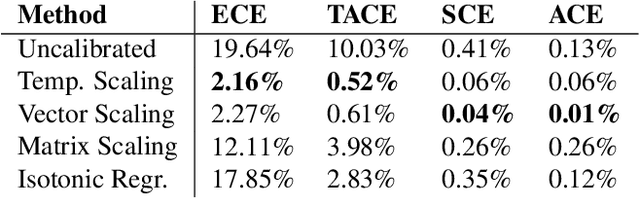
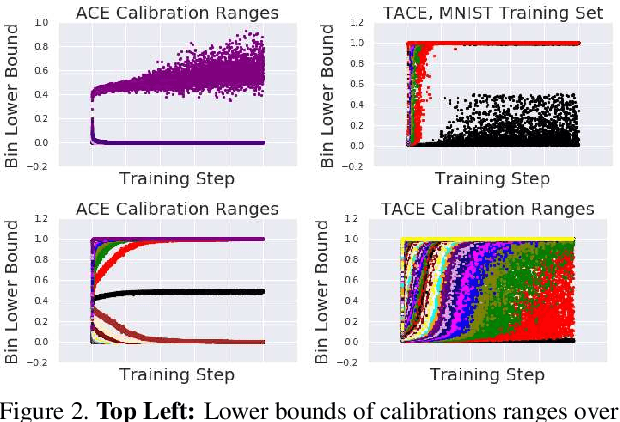
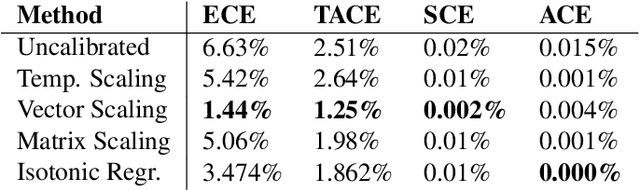
The reliability of a machine learning model's confidence in its predictions is critical for highrisk applications. Calibration-the idea that a model's predicted probabilities of outcomes reflect true probabilities of those outcomes-formalizes this notion. While analyzing the calibration of deep neural networks, we've identified core problems with the way calibration is currently measured. We design the Thresholded Adaptive Calibration Error (TACE) metric to resolve these pathologies and show that it outperforms other metrics, especially in settings where predictions beyond the maximum prediction that is chosen as the output class matter. There are many cases where what a practitioner cares about is the calibration of a specific prediction, and so we introduce a dynamic programming based Prediction Specific Calibration Error (PSCE) that smoothly considers the calibration of nearby predictions to give an estimate of the calibration error of a specific prediction.