 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Personalized Semantics for Soft Attributes in Recommender Systems using Concept Activation Vectors
Feb 06, 2022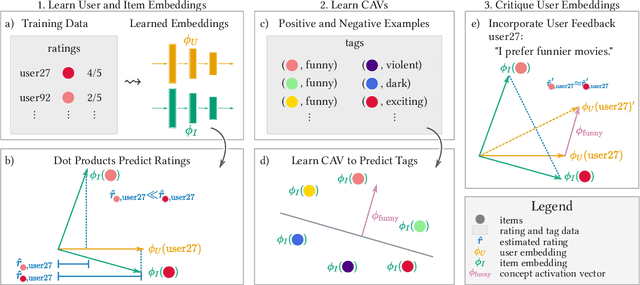


Interactive recommender systems (RSs) allow users to express intent, preferences and contexts in a rich fashion, often using natural language. One challenge in using such feedback is inferring a user's semantic intent from the open-ended terms used to describe an item, and using it to refine recommendation results. Leveraging concept activation vectors (CAVs) [21], we develop a framework to learn a representation that captures the semantics of such attributes and connects them to user preferences and behaviors in RSs. A novel feature of our approach is its ability to distinguish objective and subjective attributes and associate different senses with different users. Using synthetic and real-world datasets, we show that our CAV representation accurately interprets users' subjective semantics, and can improve recommendations via interactive critiquing
ConQUR: Mitigating Delusional Bias in Deep Q-learning
Feb 27, 2020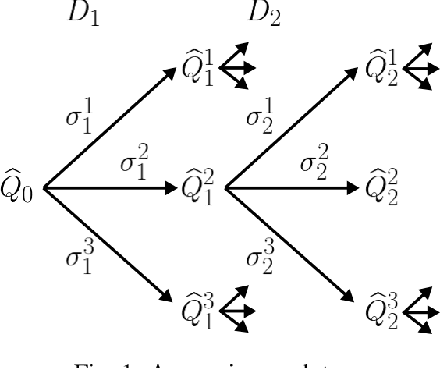
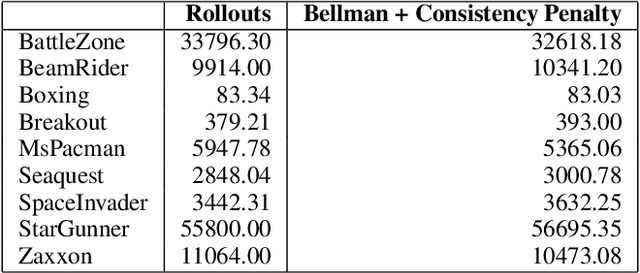

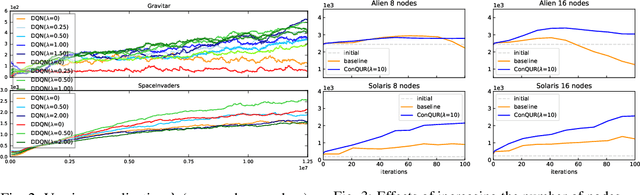
Delusional bias is a fundamental source of error in approximate Q-learning. To date, the only techniques that explicitly address delusion require comprehensive search using tabular value estimates. In this paper, we develop efficient methods to mitigate delusional bias by training Q-approximators with labels that are "consistent" with the underlying greedy policy class. We introduce a simple penalization scheme that encourages Q-labels used across training batches to remain (jointly) consistent with the expressible policy class. We also propose a search framework that allows multiple Q-approximators to be generated and tracked, thus mitigating the effect of premature (implicit) policy commitments. Experimental results demonstrate that these methods can improve the performance of Q-learning in a variety of Atari games, sometimes dramatically.
Gradient-based Optimization for Bayesian Preference Elicitation
Nov 20, 2019

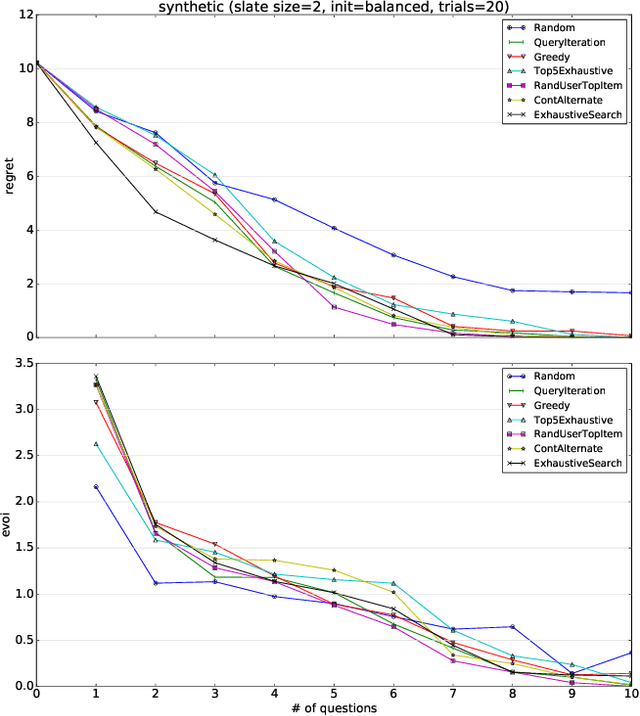

Effective techniques for eliciting user preferences have taken on added importance as recommender systems (RSs) become increasingly interactive and conversational. A common and conceptually appealing Bayesian criterion for selecting queries is expected value of information (EVOI). Unfortunately, it is computationally prohibitive to construct queries with maximum EVOI in RSs with large item spaces. We tackle this issue by introducing a continuous formulation of EVOI as a differentiable network that can be optimized using gradient methods available in modern machine learning (ML) computational frameworks (e.g., TensorFlow, PyTorch). We exploit this to develop a novel, scalable Monte Carlo method for EVOI optimization, which is more scalable for large item spaces than methods requiring explicit enumeration of items. While we emphasize the use of this approach for pairwise (or k-wise) comparisons of items, we also demonstrate how our method can be adapted to queries involving subsets of item attributes or "partial items," which are often more cognitively manageable for users. Experiments show that our gradient-based EVOI technique achieves state-of-the-art performance across several domains while scaling to large item spaces.
Safe Exploration for Identifying Linear Systems via Robust Optimization
Nov 30, 2017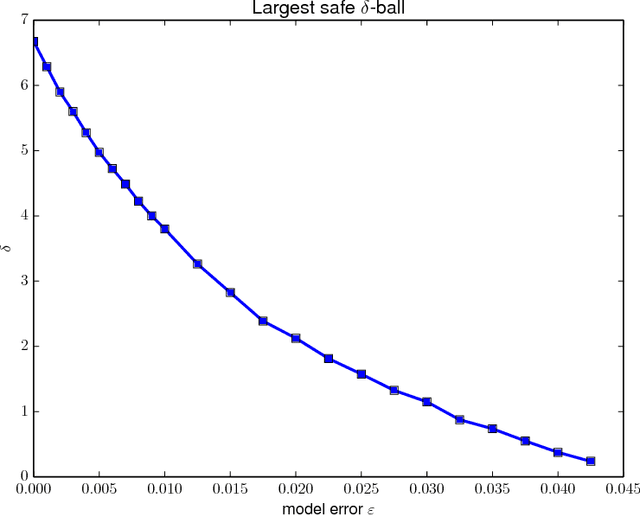
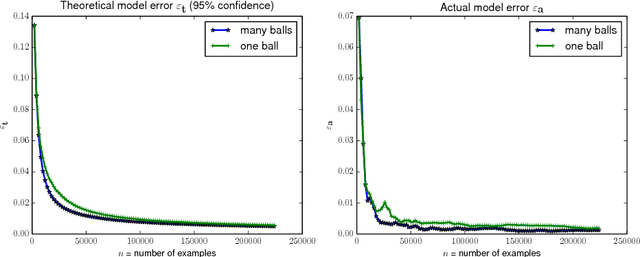
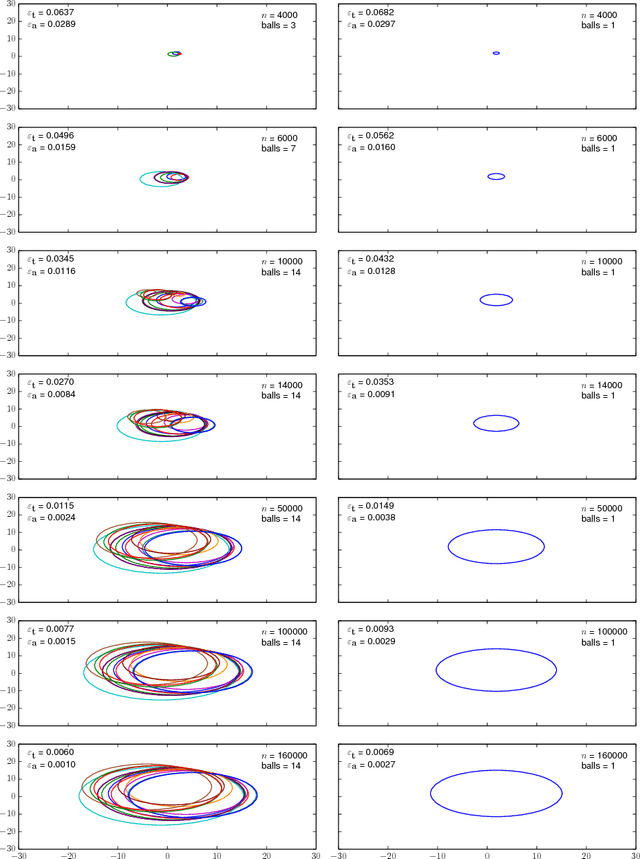
Safely exploring an unknown dynamical system is critical to the deployment of reinforcement learning (RL) in physical systems where failures may have catastrophic consequences. In scenarios where one knows little about the dynamics, diverse transition data covering relevant regions of state-action space is needed to apply either model-based or model-free RL. Motivated by the cooling of Google's data centers, we study how one can safely identify the parameters of a system model with a desired accuracy and confidence level. In particular, we focus on learning an unknown linear system with Gaussian noise assuming only that, initially, a nominal safe action is known. Define safety as satisfying specific linear constraints on the state space (e.g., requirements on process variable) that must hold over the span of an entire trajectory, and given a Probably Approximately Correct (PAC) style bound on the estimation error of model parameters, we show how to compute safe regions of action space by gradually growing a ball around the nominal safe action. One can apply any exploration strategy where actions are chosen from such safe regions. Experiments on a stylized model of data center cooling dynamics show how computing proper safe regions can increase the sample efficiency of safe exploration.
Learning Low-Density Separators
Jan 22, 2009
We define a novel, basic, unsupervised learning problem - learning the lowest density homogeneous hyperplane separator of an unknown probability distribution. This task is relevant to several problems in machine learning, such as semi-supervised learning and clustering stability. We investigate the question of existence of a universally consistent algorithm for this problem. We propose two natural learning paradigms and prove that, on input unlabeled random samples generated by any member of a rich family of distributions, they are guaranteed to converge to the optimal separator for that distribution. We complement this result by showing that no learning algorithm for our task can achieve uniform learning rates (that are independent of the data generating distribution).